Inetbib-Ableger für Werbung und Ankündigungen
25. August 2008 um 23:34 Keine KommentareMichael Schaarwächter, Gründer und Hüter der deutschsprachigen Bibliotheks-Mailingliste INETBIB hat mit Inetbib-k am 12. August einen ein Weblog-Ableger ins Leben gerufen, auf dem bibliothekarische Produktneuigkeiten und Veranstaltungstermine veröffentlicht werden können. Das Konzept von Inetbib-K sieht vor, dass dort auch kommerzielle Informationen veröffentlicht werden können, die auf der Mailingliste als Werbung unerwünscht sind. Allerdings müssen die Beiträge per Mail an Herr Schaarwächter geschickt werden, der dann ggf. aussiebt und kürzt (siehe Ankündigung auf INETBIB).
Die Idee, Nachrichten per E-Mails einzusammeln und redaktionell ausgesucht in einem Blog zu veröffentlichen, der zu einer Mailingliste gehört, klingt vielleicht ein wenig komisch – doch nicht alle Firmen, Organisationen und Veranstalter haben ein eigenes Weblog. Gut ist auch, dass die Beiträge als Hinweise auf Produkte, Dienstleistungen, Veranstaltungen etc. deutlich sind anstatt dass man dauernd auf versteckte Werbung stößt, wie in Zeitschriften für Bibliothek und Dokumentation leider nicht unüblich (als elektronisches Analogon einer Zeitschriftenrubrik verstehe ich Inetbib-K am ehesten).
Hilfreich wäre noch ein aggregierter Feed oder „Planet“ (siehe Planet Netbib) mit Postings der Hersteller von Bibliothekssoftware und anderen bibliotheksrelevanten Firmen – zumindest die, die schon News-Alerts haben und damit nicht auch noch Mails an Inetbib-k schicken müssen. [via Infobib]
Die Zukunft des Katalogisierens
14. Juli 2008 um 12:45 Keine KommentareMeine momentane Begeisterung für OpenStreetMap sollte nicht darüber hinwegtäuschen, dass nach Wikipedia gerade für Bibliotheken der interessanteste und wichtigste Dienst noch immer LibraryThing ist (siehe kurze Einführung für Bibliothekare und zum Ausprobieren bei Lernen 2.0). Ohne je Bibliothekswissenschaft studiert zu haben, entwickelt Tim Spalding innovative Systeme für bibliographische Informationen, bei denen die Bibliothekssysteme jeglicher Hersteller wie von vorvorgestern aussehen (und mit ihnen die Bibliotheken, die sich diese Systeme andrehen lassen, anstatt Dienste wie LibraryThing for Libraries oder VuFind auszuprobieren und genau auf Anne zu hören).
Dabei zeigt LibraryThing nicht nur, wie ein guter Katalog aussehen kann und wie durch Einbindung von Nutzern Mehrwehrt geschaffen wird, sondern nicht weniger als die Zukunft des Katalogisierens! Ich kann jedem, der sich für die Zukunft von Bibliotheken interessiert, nur eindringlich empfehlen, sich den 18-minütigen Mitschnitt des Vortrags von Tim Spalding anzusehen (Teil 1, Teil 2)!
Das nächstes wesentliche Projekt von LibraryThing ist die Open Shelves Classification, die nicht weniger zum Ziel hat als die DDC als Aufstellungssystematik zu ersetzen – das erinnernt mich daran, dass aus Wikipedia-Daten ein Thesaurus erstellt werden kann. Also besser aufpassen (und am Besten mitmachen) anstatt die Augen zu verschließen! [via Patrick]
Die Rolle der Bibliotheken im Internetzeitalter
21. Juni 2008 um 03:07 1 KommentarDa die „uncoolen“ Potsdamer BibliothekarInnen nun schon die dritten sind, die mich auf den Artikel „Die Rolle der Bibliotheken im Internetzeitalter“ (PDF) von Barbara Lison im Themenheft „Wissen im Web“ von „UNESCO heute“ (Ausgabe 1/2008) hinweisen, muss ich doch meinen Senf dazugeben (zumal ich nach drei Wochen Telekom-Generve endlich wieder Internet habe und somit wieder bloggen kann). Der Artikel bietet eine gute Darstellung des aktuellen aktuellen Standes.
Neben die Sammlung und Erschließung von Inhalten – ob in gedruckter Literatur oder in Netzpublikationen – ist immer stärker die Aufgabe der Vermittlung, der Eröffnung des Zugangs getreten.
Außerdem wird ganz kurz das EU-Projekt Europeana genannt – eine etwas bessere Darstellung gibt Jörn Sieglerschmidt im Interview mit dem SWR. Ein wenig erinnert mich der Artikel an „Bücher und Internet: Das Kaleidoskop der Vergangenheit“ von Johannes Schneider Anfang des Monats in der Süddeutschen Zeitung (siehe Kommentar und mein Hinweis): Mehr oder weniger alles richtig und wichtig aber ziemlich unkonkret, wenig vorausschauend oder innovativ und eigentlich schon vor 5 bis 10 Jahren passend. Schön, dass Bibliotheken allgemein in den Medien präsenter sind, aber für die Darstellung des aktuellen Standes gibt es doch Wikipedia!. Vielleicht ist das UNESCO-Magazin einfach nicht der richtige Ort für neue Entwicklungen; der Artikel zu Wikipedia ist ebenfalls nur sehr allgemein gehalten und das mehrfach im Magazin erwähnte Thema Web 2.0 ist eigentlich inzwischen ein alter Hut.
Was nun tatsächlich die Rolle von Bibliotheken im Internetzeitalter ist und sein wird, beantwortet der Artikel jedenfalls nicht zufriedenstellend. Überhaupt ist der Begriff „Internetzeitalter“ viel zu kurz gegriffen. Es geht nicht um das Zeitalter des Internet, sondern um das Zeitalter der Digitalisierung aller Informationen und damit um die unbegrenzte Kopier-, Modifizier- Annotier-, Verknüpf-, und Verfügbarkeit von Informationen. Und dabei haben Bibliotheken ihre Rolle noch längst nicht gefunden.
Nature als Nationallizenz verfügbar
29. Mai 2008 um 17:14 2 KommentareNature, die neben „Science“ renommierteste wissenschaftliche Fachzeitschrift, ist ab sofort im Rahmen der Nationallizenzen in den Jahrgängen von 1869-2007 für alle „in Deutschland wissenschaftlich Tätige“ kostenfrei verfügbar und kann hier recherchiert werden. Welche weiteren Zeitschriften und Datenbanken ebenfalls als Nationallizenz verfügbar sind, ist unter www.nationallizenzen.de einsehbar. Nach und nach werden auch die gesamten Metadaten gesammelt – siehe dazu die Datenbanken, die bei der VZG aufgelistet werden. Der Zugang sollte in allen Bibliotheken möglich sein, die Nature als Nationallizenz ausgewählt haben. Um auch vom eigenen Arbeitsplatz zugreifen zu können, muss man sich theoretisch per Shibbolethals als Nutzer einer Bibliothek ausweisen. Praktisch funktioniert das aber bislang nur für Einzelnutzer, das heisst Personen, die keine Bibliotheken nutzen oder nur Bibliotheken, die noch kein Shibboleth zur Authentifizierung im Rahmen der DFN-Föderation unterstützen. Hier kann man sich anmelden.
Beim Blättern in den alten Ausgaben ist mir aufgefallen, dass sich der Stil und die Anforderungen an wissenschaftliche Fachartikel mit der Zeit doch schon etwas gewandelt haben. Die kurzen Artikel aus dem 19. Jahrhundert erinnern mich teilweise eher an heutige Weblog-Beiträge! 😉
Mehr zu Bibliothekssoftware
7. Mai 2008 um 12:45 Keine KommentareAnknüpfend an die US-Umfrage zu Bibliothekssystemen möchte ich auf die unterhaltsame, vonLibrary Mistress ausgegrabene Liste „Bibliothekssoftware 1991“ hinweisen. Vor acht Jahren gab es vom DBI mal eine Umfrage zum „Softwareeinsatz in Bibliotheken“ – das ist aber höchstens noch historisch von Interesse. Michael Lackhoff bietet eine Linksammlung zu Bibliothekssoftware, die allerdings auch nur einen Ausschnitt enthält und nicht ganz aktuell ist – so fehlen beispielsweise die gesamten PICA-Produkte (was auch daran liegt, dass PICA bzw. OCLC, die Produkte nicht richtig vermarkten), neuere Entwicklungen wie VuFind und Evergreen und hoch-relevante Hintergrund-Techniken wie Lucene (mehr zu aktuellen Entwicklungen bei OSS4LIB).
Statt monolithischer Bibliothekssoftware „von der Stange“ sind nämlich die einzelnen Komponenten (Services) und ihre Verzahnung wichtig. Leider ist dagegen noch immer die Vorstellung verbreitet, dass man sich als Bibliothek besser an einen Hersteller wendet, der einem in schön bunter Verpackung, eine Black-Box verkauft. Eine Bibliothek, die sich aber nicht selbst Gedanken darüber macht, welche Daten aus welchen Quellen wie zusammengeführt und in welcher Form bereitgestellt werden, kann eigentlich gleich ihre Mitarbeiter entlassen und auf vollautomatischen Betrieb umstellen – denn in Zukunft wird es sich bei immer mehr Publikationen um elektronische Publikationen handeln, also Daten. Folgende Vorstellung ist leider nicht aus der Luft gegriffen:
Ich dachte wir kaufen Produkt X und die richtigen Daten kommen von Zauberhand hinein, konvertieren sich von alleine und werden auf magische Weise so bereitgestellt, wie es der Nutzer möchte.
Konkurrenz zu Normdaten mit dem Scopus Affiliation Identifier
30. April 2008 um 09:34 2 KommentareWie medinfo berichtet (Details dort) hat Scopus nach dem Author identifier nun den Scopus Affiliation Identifier eingeführt. Damit baut Scopus praktisch eine eigene Normdatei für Körperschaftenh auf. In Deutschland ist dafür bislang die Gemeinsame Körperschaftsdatei (GKD) verbreitet, weitere Systeme existieren in anderen Ländern.
Ich sehe die Entwicklung von Normdaten ähnlich wie Patrick Danowski, der in seiten Vorträgen (The future importance of bibliographic data Sharing and control in Web 2.0, Sharing and control) auf die Bedeutung von freien Normdaten hingewiesen hat: Wenn Bibliotheken nicht endlich ihre Normdaten aktiv und kompetent für die Nutzung im Web anbieten, machen es andere und die bibliothekarischen Normdaten versinken in der Bedeutungslosigkeit. Das Zeitfenster, in dem andere Akteure dazu gebracht werden können, die bibliothekarischen Normdaten weiterzunutzen, schließt sich langsam – wenn es zu spät ist, werden Bibliotheken den anderen herlaufen müssen anstatt umgekehrt. Das Potential für Bibliotheken, sich als relevanter Bestandteil des (Semantic) Web zu positionieren ist mit den bestehenden Normdaten da. Leider aber ist die Situation zu oft – wie beispielsweise neulich an der DNB – so, dass eine gute Idee in ihrer (technischen und organisatorischen) Umsetzung dem Stand der Entwicklung hinterherhinkt und langsam so sehr verkrustet, dass es irgendwann eben andere besser machen – und Bibliotheken damit stückweise überflüssig werden. 🙁
Umfrage und Studie zu Bibliothekssystemen
29. April 2008 um 10:47 6 KommentareDie Ergebnisse einer 2007 durchgeführten internationalen Umfrage zu Bibliothekssystemen (ILS) sind seit Januar verfügbar. Marshall Breeding hat die Umfrage durchgeführt und stellt mehrere Statistiken bereit (ansonsten schreibt Breeding an verschiedenen Stellen zur „New Generation of Library Interfaces„). Die in Deutschland verwendeten Bibliothekssysteme sucht man vergeblich: PICA LBS: 1 Antwort, LIBERO: 3 Antworten, Allegro: 0 Antworten, SISIS-SunRise: 0 Antworten. Angesichts der niedrigen Beteiligung aus Deutschland ist das aber auch nicht verwunderlich: von 1783 Antworten kamen genausoviele von Deutschen Bibliotheken, wie beispielsweise aus Malaysia, Libanon oder Singapur: nämlich 2. Es sei aber bemerkt, dass auch aus den im Vergleich zu Deutschland hinsichtlich ihrer Bibliothekssysteme aktiveren Niederlanden nur 5 Antworten kommen, die Masse ist aus dem Englischsprachigen Raum.
Ein wenig seltsam finde ich das schon, was ist die Schlussfolgerung? Deutsche Bibliotheken interessieren sich nicht für ihre Bibliothekssysteme? Deutsche Bibliotheken nehmen nicht an internationalen Umfragen teil? Die in Deutschland verwendeten Bibliothekssysteme sind sowieso hoffnungslos irrelevant? Was Softwaremäßig außerhalb des deutschen Bibliothekstellerands geschieht interessiert nicht? Umfragen werden überbewertet? …
Auf eine weitere Studie weist Lorcan Dempsey hin: „Library Management Systems Study: An Evaluation and horizon scan of the current library management systems and related systems landscape for UK higher education“ (PDF). Die Studie enthält einige sehr bemerkenswerten allgemeinen Aussagen („Key trends“) über die Entwicklung von Bibliothekssystemen: Standards, Web Services, Konsortien, Open Source, Open Data, Entkoppelte Systeme (Serviceorientierte Architektur). Es lohnt sich also auch hier mal reinzuschauen (wenn man sich für die Zukunft von Bibliothekssystemen interessiert). [via Web4lib].
BibSonomy und Kataloge verknüpfen mit dem Bibkey
25. April 2008 um 15:46 2 KommentareAnknüpfend an einen Workshop zum Thema „Social Tagging in Bibliotheken“ und an Gespräche auf der INETBIB 2008 gab es Überlegungen, Bibliothekskataloge mit der webbasierten Literaturverwaltung BibSonomy zu verknüpfen (siehe auch die Diplomarbeit von Annett Kerschis auf die Patrick hingewiesen hat).
Zum einen sollen Nutzer Einträge aus dem Katalog direkt in BibSonomy abspeichern können (wie bereits der KUG und HEIDI anbieten) – der einfachste Weg dazu ist ein BibTeX-Export. Zum anderen soll per Webservice BibSonomy abgefragt werden, ob und mit welchen Tags dort bereits ein Titel von Nutzern gespeichert wurde. Ein grundsätzliches Problem dabei ist jedoch, erst einmal den Titel zu identifizieren, nach dem gesucht werden soll. Die dahinter liegende Aufgabenstellung ist ein klassisches (nicht nur) Bibliothekswissenschaftliches Forschungsfeld: Duplikaterkennung in bibliographischen Datenbanken. BibSonomy ist dabei auf eine ähnliche Lösung gekommen, wie sie teilweise in Katalogen angewandt wird: Aus verschiedenen Feldern (Titel, Autor, Jahr…) wird durch Normalisierung und mittels einer Hashfunktion eine Zeichenkette als Identifikator („Hashkey“) gebildet. Dubletten sollen dabei möglichst auf den gleiche Hashkey abgebildet werden. Der übergreifende Hashkey von BibSonomy heisst dort „Interhash“.
Ich bin momentan dabei, diesen Hashkey zu spezifizieren (Unter dem Namen „Bibkey Level 1“) und zu implementieren – der Bibkey kann hier ausprobiert werden. In diesem Beispiel wird der Titel über die ISBN aus den GBV-Verbundkatalog geholt und aus den Daten der Bibkey gebildet (serverseitig, Link „Go to record in GSO“). Mit dem Bibkey wird dann über eine weitere API von BibSonomy (die ich als „SeeAlso“-verpackt habe) abgefragt ob den Titel schon jemand in seiner Sammlung hat (clientseitig, Link „Available in BibSonomy“).
Wie alle Heuristiken funktionier der Bibkey in seiner jetzigen Form nicht in jedem Fall. In diesem Beispiel wird bei BibSonomy nichts gefunden, weil die meisten Nutzer „Albert-László Barabási“ Nicht richtig buchstabieren können. Auch verschiedene Auflagen kommen aufgrund unterschiedlicher Jahreszahl nicht zusammen. Es ist also noch genügend Forschungs- und Entwicklungsbedarf. Auch für den Einsatz von FRBR wird über Hashkeys nachgedacht, wie dieser Vortrag von Rosemie Callewaert auf der ELAG2008 zeigt.
Weitere Literatur zum Thema „Hashkeyverfahren zur Duplikaterkennung in bibliographischen Daten“ sammle ich dank hilfreicher Hinweise mit dem Tag „bibkey“ – falls jemand seine Bachelor/Master-Arbeit dazu machen möchte, helfe ich gerne! 🙂
Vorbildliches OPAC-Widget von der Jacobs University
23. April 2008 um 15:03 1 KommentarKollege John_Paul weist hier im Kommentar und auf den Seiten der Jacobs University auf das gelungene Katalog-Widget jOPAC hin. Der Meinung von Christan Hauschke, dass das Widget „im deutschsprachigen Raum wirklich Maßstäbe setzt“ kann ich mich anschließen. Das Widget ist mit Hilfe von Netvibes Universal Widget API (UWA) programmiert und damit unter verschiedenen Widget-Engines (iGoogle, Netvibes, Windows Vista Sidebar, Apple Dashboard, Windows XP Yahoo Sidebar …) lauffähig. Ein Serverausfall bei Netvibes heute vormittag zeigte allerdings auch ein Manko vieler Mashups: Die Dienste fallen ab und zu mal aus. Wenn der UWA Quellcode von Netvibes auf einen eigenen Server kopiert wird, sollte eine Fehlerquelle minimiert sein. Auf den OPAC der Bibliothek der Jacobs University greift das Widget über einen eigenen Webservice zu, der wiederum per Z39.50 mit dem OPAC kommuniziert – es sollte also nicht sehr aufwändig sein, solch ein Widget auch für andere Bibliotheken anzubieten. Im Detail müsste man sich allerdings anschauen, welche Daten in welchem Format genau über Z39.50 abgefragt werden, da verwendet ja leider gerne jede(s/r) Bibliothek(ssystem/sverbund) seine eigenen Standards.
P.S: Nein, ich habe nichts mit der „Jacobs University“ zu tun, mein Name wird mit „k“ geschrieben 😉
Bibliothekartag 2008 = 0.5?
14. April 2008 um 18:10 11 Kommentare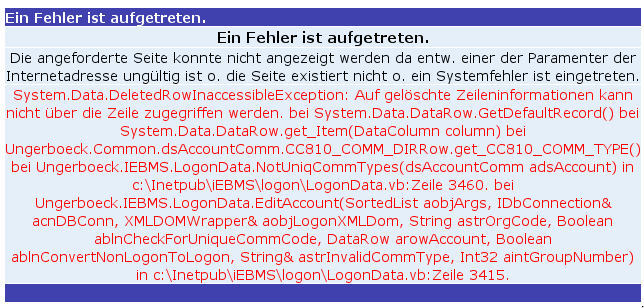
Fehlermeldung bei der Anmeldung
Ein weiteres Beispiel dafür, dass Bibliotheken eigenen technischen Sachverstand benötigen anstatt outzusourcen bietet die Webseite des Bibliothekartags 2008 in Mannheim. Sieht schön aus, ist aber Murx. Statt wesentlicher Informationen in zeitgemäßer Form gibt es Grußworte und einen Offenen Brief an die bibliothekarische Fachöffentlichkeit – als JPG!? Nicht das Tagungsweblog wird eingebunden, sondern ein totes „Forum„. Die Programmübersicht, eigentlich ja der Kern einer solchen Webseite, ist aufgrund von CSS-Spielereien völlig unbrauchbar (der Auslöser dieses Rants). Einfache Tabelle? Thematische Übersicht? Liste der Referenten? Verlinkte Raumpläne? Alles Fehlanzeige. Dass für die Stadtpläne nicht einfach Google-Maps verwendet wurde ist da noch zu vernachlässigen und Ortsangaben wie „Treffpunkt: Foyer der UB, Plöck 107-109, 69117 Heidelberg (Bitte geben Sie als Suchwort ‚Plöck 109‘ ein)“ haben wenigstens Seltenheitswert 😉
Ich finde es äußerst problematisch, wie sich Bibliotheken unnötig in Abhängigkeit von Firmen begeben (hier diese Firmen) und dabei ihrer eigenen Handlungsspielräume und Fähigkeiten einschränken. „Mal schnell“ etwas an der Webseite oder am OPAC ändern geht nicht dann nicht mehr so einfach und/oder kostet zusätzlich Geld. Dem Hinweis zur Entwicklung eigener Kompetenzen von Anne Christensen im Beluga-Projekt kann ich mich nur anschließen. Mir geht der zwar Web-2.0-Leierkasten inzwischen auf den Geist (und ich werde freiwillig keine „Was ist und was soll XY 2.0“-Vorträge mehr halten), aber anscheinend ist es noch immer nicht angekommen, das im Web nur überlebt, wer sich selber mit den zahlreichen Diensten und Angeboten vertraut macht und sie selber ausprobiert. Für Konferenzen fallen mir neben Google Maps spontan Venteria und Mixxt ein und eine Programmübersicht kann so ausschauen. Schön wäre es auch, wenn die einzelnen Veranstaltungen mit Microformats erschlossen sind, jeweils eine eigene URL bekommen und aktiv zum Tagging angeboten werden, so dass sich jeder Besucher mit einem beliebigen Tagging-Dienst und/oder Kalenderprogramm einfach einen Plan zusammenstellen kann. Auch die Einbindung von Feeds zur Veranstaltung wäre nett – wenn sich Bibliotheken nicht mit Sacherschließung, Verschlagwortung und Metadaten auskennen, mit was dann?! Die UB Mannheim zeigt mit ihrem Blog, dem (versteckten) Konferenzblog und Überlegungen zu Tagging zumindest, dass es auch anders geht. Die Pläne zum kritiklosen Einsatz von Primo überzeugen dafür weniger – wurden Alternativen wie Encore, VuFind, OpenBib etc. überhaupt ernsthaft in Betracht gezogen?
Als Tags für Beiträge zum Bibliothekartag schlage ich „bibliothekartag2008“ (genutzt hier, kein Tag bei netbib) und „#bibtag08“ vor – sowas sollte eigentlich auch auf der Webseite zur Veranstaltung vorgegeben und erklärt werden, sonst werden die Tags gar nicht erst verwendet, vergessen oder uneinheitlich benutzt – wie teilweise passiert zur Inetbib 2008: dort wurde mal getaggt mit Leerzeichen, mal ohne und mal ganz ohne Tag. Naja, Googles Volltextsuche wird es schon richten – aber dafür brauchen wir dann auch keine Bibliothekare mehr.
P.S: Beim Versuch mich anzumelden, gab das Registrierungssystem „>sogleich eine Fehlermeldung von sich, als ich meine Telefonnummer korrigieren wollte. Kein Wunder wenn das m:con Congress Center Rosengarten VisualBasic unter IIS verwendet 😉
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare