KIM-Session zu Metadaten auf dem Bibliothekstag 2008
4. Juni 2008 um 16:38 Keine KommentareDer Vortrag zu „Strukturierten Metadaten in Wikipedia“ auf dem Bibliothekstag 2008 ist gut angenommen worden. Fragen kamen vor allem zu ISBN, PND und Personendaten. Leider konnte ich wahrscheinlich nicht ganz rüberbringen, dass dies nur Beispiele für Metadaten aus Wikipedia sind und dass die Verknüpfung und Weiternutzung von Metadaten insgesamt zunimmt; Wikipedia ist hierbei nur ein wesentlicher Nucleus. Vielleicht hätte zum Verständnis noch der Einführungsvortag von Bernhard Haslhofer zum Semantic Web geholfen, der leider krankheitsbedingt ausfallen musste. Der Vortrag „Metadaten im digitalen Workflow“ von Jens Klump aus Potsdam hat mir gefallen, ich vermute nur, dass er für viele Besucher schwer zu verstehen war – Metadaten sind halt auch ein etwas trockenes Thema, schon verwunderlich, dass die Session mit schätzungsweise 100 Personen so gut besucht war. Bei dem Vortrag von Steffen Lamparter über „Metadaten in Service Registries“ konnte ich zunächst bei einigen grundlegenden Punkte zustimmen (Trend zu immer mehr Produzenten von Inhalten und Metadaten, fortschreitende Automatisierung, immer mehr Dienste etc.), aber als er später zu Ontologien kam, wurde es etwas zu unkonkret und praxisfern. Die Einschätzung liegt vielleicht auch an meiner generell skeptischen Haltung gegenüber Ontologien. Abschließend widmeten sich Tom Baker und Stefanie Rühle der Frage „Kann Zertifizierung der Modellkonformität helfen“ und knüpften damit an den Einführungsvortrag von Mirjam Keßler über das KIM-Projekt an.
Social Cataloging ist Bibliothekswissenschaft at its best
2. Juni 2008 um 21:47 3 KommentareIst eigentlich schon jemandem aufgefallen, dass das Erste Lehrbuch der Bibliothekswissenschaft, nämlich Martin Schrettingers „Handbuch der Bibliothek-Wissenschaft von 1834 mit vollständigem Titel „Handbuch der Bibliothek-Wissenschaft, besonders zum Gebrauche der Nicht-Bibliothekare; welche ihre Privat-Büchersammlung selbst einrichten wollen“ heisst? Social Cataloging ist also nichts anderes als die Fortführung von Bibliothekswissenschaft mit zeitgemäßen Mitteln. Zeitgemäß heisst nichts anderes als digital (entweder digital oder marginal) und damit kommt der Social Software-Aspekt des Social Catalogings ganz automatisch. Denn Digital heisst unbegrenzte kopier- und modifizierbar, das war schon vor 20 Jahren so, auch wenn das bei einigen ewig Gestrigen noch immer nicht angekommen ist: „Der Computer ist eine Maschine zum Kopieren und Verändern von Bits.“ (Wau Holland). Dass ganz normale bibliophile Menschen ihre Literatursammlungen selber erschließen ist nichts bibliothekarisch Irrelevantes oder Unprofessionelles sonder wäre sicher ganz im Sinne Schrettingers. Gestern hätte sich noch niemand vorstellen können, dass in Zukunft Enzyklopädien von Freiwilligen geschrieben werden, morgen werden wir uns darüber wundern, dass Publikationen früher allein von einer Handvoll Bibliothekaren erschlossen wurden. Die kommen nämlich mit dem Katalogisieren jetzt schon nicht hinterher – oder wo bitte sind die fachlich erschlossenen Weblogs, Primärdaten, Vorträge etc.? Mit den dank Social Cataloging freiwerdenden Kräften können dann die Aufgaben angegangen werden, für die nach Ulrich Johannes Schneider in seinem heutigen, ganzseitigen Artikel in der Süddeutschen Zeitung nicht genügend Stellen da sind. In diesem Sinne wünsche ich allen Bibliothekaren und Nicht-Bibliothekaren, ganz gleich welche Sammlung von Publikationen sie einrichten wollen, einen schönen Bibliothekartag 2008!
Bibliothekartag 2008 = 0.5?
14. April 2008 um 18:10 11 Kommentare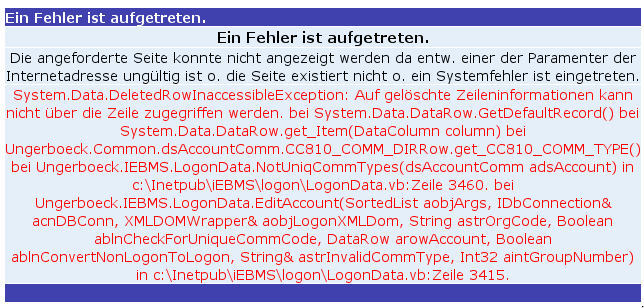
Fehlermeldung bei der Anmeldung
Ein weiteres Beispiel dafür, dass Bibliotheken eigenen technischen Sachverstand benötigen anstatt outzusourcen bietet die Webseite des Bibliothekartags 2008 in Mannheim. Sieht schön aus, ist aber Murx. Statt wesentlicher Informationen in zeitgemäßer Form gibt es Grußworte und einen Offenen Brief an die bibliothekarische Fachöffentlichkeit – als JPG!? Nicht das Tagungsweblog wird eingebunden, sondern ein totes „Forum„. Die Programmübersicht, eigentlich ja der Kern einer solchen Webseite, ist aufgrund von CSS-Spielereien völlig unbrauchbar (der Auslöser dieses Rants). Einfache Tabelle? Thematische Übersicht? Liste der Referenten? Verlinkte Raumpläne? Alles Fehlanzeige. Dass für die Stadtpläne nicht einfach Google-Maps verwendet wurde ist da noch zu vernachlässigen und Ortsangaben wie „Treffpunkt: Foyer der UB, Plöck 107-109, 69117 Heidelberg (Bitte geben Sie als Suchwort ‚Plöck 109‘ ein)“ haben wenigstens Seltenheitswert 😉
Ich finde es äußerst problematisch, wie sich Bibliotheken unnötig in Abhängigkeit von Firmen begeben (hier diese Firmen) und dabei ihrer eigenen Handlungsspielräume und Fähigkeiten einschränken. „Mal schnell“ etwas an der Webseite oder am OPAC ändern geht nicht dann nicht mehr so einfach und/oder kostet zusätzlich Geld. Dem Hinweis zur Entwicklung eigener Kompetenzen von Anne Christensen im Beluga-Projekt kann ich mich nur anschließen. Mir geht der zwar Web-2.0-Leierkasten inzwischen auf den Geist (und ich werde freiwillig keine „Was ist und was soll XY 2.0“-Vorträge mehr halten), aber anscheinend ist es noch immer nicht angekommen, das im Web nur überlebt, wer sich selber mit den zahlreichen Diensten und Angeboten vertraut macht und sie selber ausprobiert. Für Konferenzen fallen mir neben Google Maps spontan Venteria und Mixxt ein und eine Programmübersicht kann so ausschauen. Schön wäre es auch, wenn die einzelnen Veranstaltungen mit Microformats erschlossen sind, jeweils eine eigene URL bekommen und aktiv zum Tagging angeboten werden, so dass sich jeder Besucher mit einem beliebigen Tagging-Dienst und/oder Kalenderprogramm einfach einen Plan zusammenstellen kann. Auch die Einbindung von Feeds zur Veranstaltung wäre nett – wenn sich Bibliotheken nicht mit Sacherschließung, Verschlagwortung und Metadaten auskennen, mit was dann?! Die UB Mannheim zeigt mit ihrem Blog, dem (versteckten) Konferenzblog und Überlegungen zu Tagging zumindest, dass es auch anders geht. Die Pläne zum kritiklosen Einsatz von Primo überzeugen dafür weniger – wurden Alternativen wie Encore, VuFind, OpenBib etc. überhaupt ernsthaft in Betracht gezogen?
Als Tags für Beiträge zum Bibliothekartag schlage ich „bibliothekartag2008“ (genutzt hier, kein Tag bei netbib) und „#bibtag08“ vor – sowas sollte eigentlich auch auf der Webseite zur Veranstaltung vorgegeben und erklärt werden, sonst werden die Tags gar nicht erst verwendet, vergessen oder uneinheitlich benutzt – wie teilweise passiert zur Inetbib 2008: dort wurde mal getaggt mit Leerzeichen, mal ohne und mal ganz ohne Tag. Naja, Googles Volltextsuche wird es schon richten – aber dafür brauchen wir dann auch keine Bibliothekare mehr.
P.S: Beim Versuch mich anzumelden, gab das Registrierungssystem „>sogleich eine Fehlermeldung von sich, als ich meine Telefonnummer korrigieren wollte. Kein Wunder wenn das m:con Congress Center Rosengarten VisualBasic unter IIS verwendet 😉
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare