Tagging von OpenAccess-Artikeln mit Wikipedia
5. August 2010 um 07:38 5 KommentareZur Zeit bekomme ich nur am Rande die tollen Beiträge der Biblioblogosphäre wie Ethik von unten und die Übersicht von Repository-Upload-Formularen mit, da ich intensiv an der Dissertation sitze (siehe meine Literatur). Lamberts Vorschlag Wikipedia zur Sacherschließung von Open Access zu nutzen, möchte ich jedoch nicht unkommentiert lassen.
Die Grundidee ist folgende: Wissenschaftliche Literatur aus Open Access Repositorien lässt sich 1.) direkt verlinken 2.) im Volltext analysieren und 3.) zur automatischen Erzeugung von Literaturangaben verwenden. Dagegen steht, dass die Sacherschließung dürftig ist und Artikel oft sehr speziell sind. Wikipedia ist dagegen ebenso für 1-3 verfügbar und bietet einen guten (manchmal sogar ausgewogenen) Einstiegspunkt in ein Thema – es fehlt jedoch oft an weiterführenden Hinweisen auf aktuelle Literatur. Lambert schlägt nun eine Webanwendung vor, in der Nutzer Wikipedia-Artikel und Open-Access Artikel einander zuordnen können. LibraryThing hat vorgemacht, dass Sacherschließung nicht dröge sein muss, sondern durch spielerische Anreize gute Ergebnisse liefert. Deshalb sollte die Sacherschließung mit Wikipedia auch möglichst einfach als Spiel umgesetzt werden. Die Webanwendung könnte sowohl von einer eigenen Seite als auch als Widget direkt aus Wikipedia und aus OA-Repositorien oder Suchmaschinen benutzt werden und sollte mit möglichst wenigen Klicks (im Idealfall nur ein einziger!) zu bedienen sein. Durch Auswertung der Volltexte können mit herkömmlicher Suchmaschinentechnologie (z.B. Solr oder Maui) von OA-Artikeln bzw. Wikipedia-Artikeln ähnliche Artikel der jeweils anderen Textgattung vorgeschlagen werden. Nutzer können dann die Vorschläge als passend oder als unpassend bewerten.
 Ich stelle mir die Bewertung ähnlich wie bei Stackoverlow vor (siehe Screenshot-Ausschnitt rechts). Nutzer können dort Reputations-Punkte für verschiedene Aktionen bekommen (oder verlieren) – siehe Stackoverflow-FAQ. Für das Hinzufügen eines nicht-automatisch vorgeschlagenen Artikels könnte es z.B. mehr Punkte geben als für das Bestätigen eines bereits vorhandenen Artikels, so dass zusätzliche Recherchen belohnt werden. In jedem Fall sollte die Weiterentwicklung der Idee erstmal mit der Benutzeroberfläche beginnen anstatt gleich über technische Möglichkeiten nachzudenken. Eine Übersicht von Webanwendungen für User-Interface Mockups gibt es hier. Papier oder Tafel und Stift reichen aber auch aus. Wichtig ist nur, dass das Design nicht von Fragen wie „wie setze ich das in HTML um?“ oder „wo und wie sollen die Daten gespeichert werden?“ beschränkt wird.
Ich stelle mir die Bewertung ähnlich wie bei Stackoverlow vor (siehe Screenshot-Ausschnitt rechts). Nutzer können dort Reputations-Punkte für verschiedene Aktionen bekommen (oder verlieren) – siehe Stackoverflow-FAQ. Für das Hinzufügen eines nicht-automatisch vorgeschlagenen Artikels könnte es z.B. mehr Punkte geben als für das Bestätigen eines bereits vorhandenen Artikels, so dass zusätzliche Recherchen belohnt werden. In jedem Fall sollte die Weiterentwicklung der Idee erstmal mit der Benutzeroberfläche beginnen anstatt gleich über technische Möglichkeiten nachzudenken. Eine Übersicht von Webanwendungen für User-Interface Mockups gibt es hier. Papier oder Tafel und Stift reichen aber auch aus. Wichtig ist nur, dass das Design nicht von Fragen wie „wie setze ich das in HTML um?“ oder „wo und wie sollen die Daten gespeichert werden?“ beschränkt wird.
BibSonomy mit neuer Oberfläche
16. Dezember 2008 um 03:19 4 KommentareSeit einigen Tagen (im Blog steht noch nichts?) zeigt sich die Social-Cataloging Plattform BibSonomy mit einer neuen Benutzeroberfläche. Die Schriftgröße ist leider noch immer Augenkrebs und ich kann mich plötzlich nicht mehr per OpenID Delegation anmelden, aber das wird sicherlich auch noch (vielleicht finde ich dann auch heraus, warum mein PhD-Literatur-Account nicht öffentlich einsehbar ist). Social Cataloging kam in der gestrigen Vorlesung zu Social Tagging und (gemeinschaftlicher) Erschließung etwas zu kurz, deshalb sei nochmal darauf hingewiesen, dass die derzeit innovativ aktivsten Dienste zur Verwaltung von bibliographischen Daten keine Bibliotheken sondern LibraryThing und BibSonomy sind. Bibliotheken können dagegen lediglich in Sachen Autorität und Dauerhaftigkeit punkten und werden sich hoffentlich einige Scheiben abschneiden. Übrigens suchen sowohl die Verbundzentrale des GBV als auch das BibSonomy-Team studentische Mitarbeiter. Wer als Student im Raum Göttingen/Kassel wohnt und Webanwendungen o.Ä. programmieren kann, sollte sich mal überlegen, ob er/sie nur langweilige Übungsaufgaben und Firmenanwendungen schreiben oder an der Zukunft der webbasierten Literaturverwaltung mitarbeiten möchte! 🙂
Deutschsprachiges Buch zum Thema Social-Tagging
24. September 2008 um 17:53 1 Kommentar Das erste deutschsprachige Buch zum Thema Social-Tagging ist diese Woche im Waxmann Verlag erschienen: Birgit Gaiser, Thorsten Hampel, Stefanie Panke (Hrsg.): Good Tags – Bad Tags. Social Tagging in der Wissensorganisation. 240 Seiten, 29,90 EUR, ISBN 978-3-8309-2039-7. Das im Anschluss an den Workshop „Social Tagging in der Wissensorganisation“ (siehe PDF) am Institut für Wissensmedien am 21. und 22. Februar 2008 entstandene Sammelwerk kann auch als PDF heruntergeladen werden. Hier das Inhaltsverzeichnis (auch als PDF):
Das erste deutschsprachige Buch zum Thema Social-Tagging ist diese Woche im Waxmann Verlag erschienen: Birgit Gaiser, Thorsten Hampel, Stefanie Panke (Hrsg.): Good Tags – Bad Tags. Social Tagging in der Wissensorganisation. 240 Seiten, 29,90 EUR, ISBN 978-3-8309-2039-7. Das im Anschluss an den Workshop „Social Tagging in der Wissensorganisation“ (siehe PDF) am Institut für Wissensmedien am 21. und 22. Februar 2008 entstandene Sammelwerk kann auch als PDF heruntergeladen werden. Hier das Inhaltsverzeichnis (auch als PDF):
Einleitung
- Thomas Vander Wal: Welcome to the Matrix! (S. 7-9)
- Birgit Gaiser, Thorsten Hampel, Stefanie Panke: Vorwort (S. 11-14)
- Matthias Müller-Prove: Modell und Anwendungsperspektive des Social Tagging (S. 15-22)
Teil 1: Theoretische Ansätze und empirische Untersuchungen
- Stefanie Panke, Birgit Gaiser: „With my head up in the clouds“ – Social Tagging aus Nutzersicht (S. 23-36)
- Christoph Held, Ulrike Cress: Social Tagging aus kognitionspsychologischer Sicht (S. 37-50)
- Michael Derntl, Thorsten Hampel, Renate Motschnig, Tomáš Pitner: Social Tagging und Inclusive Universal Access (S. 51-62)
Teil 2: Einsatz von Tagging in Hochschulen und Bibliotheken
- Christian Hänger: Good tags or bad tags? Tagging im Kontext der bibliothekarischen Sacherschließung (S. 63-72)
- Mandy Schiefner: Social Tagging in der universitären Lehre (S. 73-84)
- Michael Blank, Thomas Bopp, Thorsten Hampel, Jonas Schulte: Social Tagging = Soziale Suche? (S. 85-98)
- Andreas Harrer, Steffen Lohmann: Potenziale von Tagging als partizipative Methode für Lehrportale und E-Learning-Kurse (S. 97-106)
- Harald Sack, Jörg Waitelonis: Zeitbezogene kollaborative Annotation zur Verbesserung der inhaltsbasierten Videosuche (S. 107-118)
Teil 3: Kommerzielle Anwendungen von Tagging
- Karl Tschetschonig, Roland Ladengruber, Thorsten Hampel, Jonas Schulte: Kollaborative Tagging-Systeme im Electronic Commerce (S. 119-130)
- Tilman Küchler, Jan M. Pawlowski, Volker Zimmermann: Social Tagging and Open Content: A Concept for the Future of E-Learning and Knowledge Management? (S. 131-140)
- Stephan Schillerwein: Der ‚Business Case‘ für die Nutzung von Social Tagging in Intranets und internen Informationssystemen (S. 141-152)
Teil 4: Tagging im Semantic Web
- Benjamin Birkenhake: Semantic Weblog. Erfahrungen vom Bloggen mit Tags und Ontologien (S. 153-162)
- Simone Braun, Andreas Schmidt, Andreas Walter, Valentin Zacharias: Von Tags zu semantischen Beziehungen: kollaborative Ontologiereifung (S. 163-174)
- Jakob Voß: Vom Social Tagging zum Semantic Tagging (S. 175-186)
- Georg Güntner, Rolf Sint, Rupert Westenthaler: Ein Ansatz zur Unterstützung traditioneller Klassifikation durch Social Tagging (S. 187-200)
- Viktoria Pammer, Tobias Ley, Stefanie Lindstaedt: tagr: Unterstützung in kollaborativen Tagging-Umgebungen durch Semantische und Assoziative Netzwerke (S. 201-210)
- Matthias Quasthoff, Harald Sack, Christoph Meinel: Nutzerfreundliche Internet-Sicherheit durch tag-basierte Zugriffskontrolle (S. 211-222)
Das bisher einzige Buch zum Thema war Tagging: people-powered metadata for the social web von Gene Smith (2008, ISBN 0-321-52917-0).
Dublin Core conference 2008 started
23. September 2008 um 12:20 4 KommentareYesterday the Dublin Core Conference 2008 (DC 2008) started in Berlin. The first day I spent with several Dublin Core Tutorials and with running after my bag, which I had forgotten in the train. Luckily the train ended in Berlin so I only had to get to the other part of the town to recover it! The rest of the day I visited the DC-Tutorials by Pete Johnston and Marcia Zeng (slides are online as PDF). The tutorials were right but somehow lost a bit between theory and practise (see Paul’s comment) – I cannot tell details but there must be a way to better explain and summarize Dublin Core in short. The problem may be in a fuzzy definition of Dublin Core. To my taste there are far to many „cans“, „shoulds“, and „mays“ instead of formal „musts“. I would also stress more the importance of publicating stable URIs for everything and using syntax schemas.
What really annoys me on DC is the low committement of the Dublin Core Community to RDF. RDF is not propagated as fbase but only as one possible way to encode Dublin Core. The same way you could have argued in the early 1990s that HTTP/HTML is just one framework to build on. That’s right, and of course RDF is not the final answer to metadata issues – but it’s the state-of-the-art to encode structured data on the web. I wonder when the Dublin Core Community lost tight connection with the W3C/RDF community (which on her part was spoiled by the XML community). In official talks you don’t hear this hidden stories of the antipathies and self-interests in standardization.
The first keynote that I heard at day 2 was given by Jennifer Trant about results of steve.museum – one of the best projects that analyzes tagging in real world environments. Data, software and publications are available to build upon. The second talk – „Encoding Application Profiles in a Computational Model of the Crosswalk“ by Carol Jean Godby (PDF-slides) – was interesting as well. In our library service center we deal a lot with translations (aka mappings, crosswalks etc.) between metadata formats, so the crosswalk web service by OCLC and its description language may be of large use – if it is proberly documented and supported. After this talk Maria Elisabete Catarino reported with „Relating Folksonomies with Dublin Core“ (PDF-slides) from a study on the purposes and usage of social tagging and whether/how tags could be encoded by DC terms.
At Friday we will hold a first Seminar on User Generated Matadata with OpenStreetmap, Wikipedia, BibSonomy and The Open Library – looking forward to it!
P.S: Pete Johnston’s slides on DC basic concepts are now also available at slideshare [via his blog]
So called „best“ ECDL paper ignores tagging
15. September 2008 um 13:39 4 KommentareThe first normal talk at the ECDL2008 was about „Improving Placeholders in Digital Documents“ by George Buchanan and Jennifer Pearson. Placeholders (also known as bookmarks) in physical form are common and easy to use: you just put a peace of paper (or similar flat thing) inside a book, and optionally add notes on it. Bookmarks in the digital world are known but have low usability. A bookmark in a browser is just a plain link without additional information (color, notes, etc.), it only points to a webpage instead of specific parts of the content and it does not show up if you open the object that had been bookmarked. Moreover there is other content you may want to bookmark, for instance PDF files.
Buchanan and Pearson identified current uses of placeholders by user studies (interviews with a dozen of researchers) and created a demo interface for bookmarking PDFs. The talk was nice but I really wonder why it was selected as best paper. Especially the lack of referencing Social Tagging (Brewster Kahle brought it up in a question after the talk) would have been a clear reason for rejection if I was the reviewer! Social Tagging and Social Bookmarking has limitations – but it is much more than normal digital bookmarks and there are several tools to support tagging the files on your own hard disk. You should better try enhance tagging tools so tagging becomes more like annotating documents with placeholders instead of asking people to use artificial bookmarking tools. I hope the next talks will be better in scientific and practical relevance. Maybe the fact that Buchanan also got the best paper award last year (while beeing in the ECDL programm commitee) has influenced the decision? One more argument for open review.
Anyway: as long as there are no good interfaces to easily read and annotate documents, people will prefer paper notes for good reason. Give people a working e-paper-device with high resolution, long-lasting battery, touchscreen and the possibility to share documents without technical barriers like DRM and we can create a collaborative workspace for bookmarking and annotating documents; or as I already called it 2005 in the article „Mehr als Marginalien – das E-Book als gemeinsamer Zettelkasten“ in the German library science e-journal „LIBREAS“: a common file-card box.
Kombination von Weblog, Kalender und Literaturverzeichnis?
6. August 2008 um 20:20 4 KommentareWordPress eignet sich gut als einfaches Content Management System (CMS), da neue Beiträge einfach erstellt und kommentiert werden können. Mit zahlreichen Plugins und Anknüpfungspunkten lässt es sich zu Webanwendungen „aufbohren“, die über einfache Weblogs hinausgehen.
Momentan überlege ich für die Webseite einer Veranstaltungsreihe mit Vorträgen, wie man am besten Weblog, Kalender und Literaturverzeichnis kombinieren könnte. Bislang gibt es für jede Veranstaltung einen eigenen Beitrag. Das Datum des Beitrags ist aber nicht das Datum der Veranstaltung, sondern das Veröffentlichungsdatum des Beitrags. Irgendwie müssten die einzelnen Beiträge aber auch noch in einem Veranstaltungskalender auftauchen; man könnte sie zum Beispiel zusätzlich bei Venteria oder bei LibraryThing local eintragen und die Daten von dort wiederum im Blog einbinden – was zumindest etwas umständlich klingt.
Zu jeder Veranstaltung gibt es passende Literatur, die natürlich auch irgendwie erschlossen sein sollte. Eine Möglichkeit wäre, für jedes Werk einen eigenen Blogeintrag zu erstellen, so wie es in Scriblio der Fall ist (übrigens auch mit Verfügbarkeitsstatus). Ein Vorteil dabei ist, dass zur Verschlagwortung von Veranstaltungen wie für Literatur die gleichen Tags für verwendet werden können. Die andere Möglichkeit wäre, eine Social Cataloging-Anwendung wie BibSonomy oder LibraryThing zu nutzen. Die Literatur wird also in einer eigenen Webanwendung verwaltet und muss irgendwie per Plugin in WordPress eingebunden werden. Für BibSonomy gibt es dieses WordPress-Plugin (sowie die Möglichkeit eines HTML-Export, der per JabRef-Filter angepasst werden kann) und für LibraryThing einen Widget-Generator. Leider lassen sich bei dieser Lösung Veranstaltungen und Literatur nicht gemeinsam erschließen und recherchieren. Bei der Vergabe von und dem Browsing über Tags ist jede Anwendung (Blog, Kalender, Literaturverwaltung) noch eine Insel. Wünschenswert wäre ein gemeinsames Tagging-Vokabular über mehrere Anwendungen – das wäre dann ein einfacher Fall von Semantischem Tagging … und wahrscheinlich erst etwas für 2009 😉
Gewinner des Theseus-Wettbewerb ausgezeichnet
20. Juni 2008 um 16:40 Keine KommentareUnter 180 Bewerbungen im Rahmen des Theseus-Talente-Wettbewerbs sind vor drei Tagen die Gewinner ausgezeichnet worden. Ein Vorschlag, die Webseite des Wettbewerbs von unnötigen PDFs zu befreien, fand sich anscheinend nicht unter den Einreichungen – etwas versteckt findet sich zumindest ein „News“-Beitrag, in dem die ersten vier von 14 ausgezeichneten Gewinner kurz mit ihrem Thema genannt sind. Statt langweiligen Informatik-, Technik-, und Wirtschaftsthemen gibt es den erste Preis für einen Beitrag zum Thema „Tagging“ in Verbindung mit „Semantik“. Die Autorin Sonja Kraus studiert auf Lehramt und Magister mit den Nebenfächern Angewandte Sprachwissenschaft und sprachliche Informationsverarbeitung und hat ihren Beitrag mit „Semantstrategien“ betitelt. Was genau das sein soll geht auch aus ihrem Blog nicht so ganz hervor und die Originalarbeit ist auch (noch?) nicht öffentlich verfügbar, so dass es erstmal bei Buzzwords bleibt. Ich hoffe, es ergeht der Arbeit nicht wie dem ersten deutschsprachigen Buch zum Thema Social Tagging („Social Tagging“ von Sascha Carlin, ISBN 3-940317-03-9), auf das ich schon seit einem Dreivierteljahr vergeblich warte. Stattdessen wird nun das erste Buch der Sammelband „Good Tags, Bad Tags“ zur Tagung Social Tagging in der Wissensorganisation, der unter Anderem einen Beitrag von mir zum Semantischen Tagging enthält (weitere Infos zum Sammelband bei Birgit Gaiser). Neben Sonjas Arbeit wurde übrigens noch ein weiterer Text zum Thema Tagging ausgezeichnet und zwar der von Kim Korte (gefunden dank Trackback in Sonjas Blog :-).
Erschließung von Videos mit Yovisto
20. Mai 2008 um 13:01 1 KommentarLetzten Samstag wurde auf dem Bibcamp 2008 unter Anderem die Videosuchmaschine Yovisto vorgestellt, die an der Uni Jena entstanden ist (siehe Überblick bei infobib und Yovisto-Blog). In Yovisto werden Videos nicht nur mit einfachen Metadaten über den Film erschlossen, sondern mit Tags und Kommentaren innerhalb eines Films. Dazu werden zum einen mittels Texterkennung automatisch Texte im Film erkannt und indexiert – vor allem aus Slideshows bei Vorträgen lassen sich so viele Inhalte ermitteln. Bei der Suche wird angezeigt, welche Wörter an welcher Stellen in einem Film vorkommen und es kann an die entsprechenen Zeitmarke gesprungen werden. Zusätzlich zur automatischen Erschließung können Nutzer zeitbezogen Tags und Kommentare abgeben. Die Benutzeroberfläche ist ziemlich angenehm und leistungsfähig und Yovisto enthält viele weitere experimentelle Funktionen, wie Wiki-Seiten zu einzelnen Filmen, OpenSearch-Schnittstelle, Podcast etc.
Die Erschließung von Videos mit Yovisto eignet sich besonders für Vorlesungsmitschnitte. Diese werden zwar immer mehr gesammelt aber nur wenig durchgehend erschlossen. Was grundsätzlich verbessert werden kann ist die Anbindung an die Bibliothek und den Katalog bzw. an die ganze Uni-Infrastruktur. So sind zwar Beispielsweise in der Digitalen Bibliothek Thüringen Aufzeichnungen von Vorlesungen katalogisiert, aber nicht direkt mit Yovisto verknüpft. Dabei sollte der Trend an Hochschulen eher dahin gehen, die sich auseinander entwickelten Systeme Bibliothek und E-Learning-Plattformen wieder zusammen zu bringen – dazu müssen allerdings alle Beteiligten über ihren Tellerrand hinaus schauen und einige ihrer alten Zöpfe und abschneiden und inkompatible Sonderwege aufgeben. Das Datenformat von Yovisto ist MPEG-7 – anstatt alles von Hand mehrfach zu katalogisieren, können damit sicherlich Daten gemeinsam genutzt werden. Techniken aus Yovisto werden auch im Video-Erschließungssystem REPLAY verwendet, das in Zusammenarbeit mit der ETH-Zürich entsteht.
Bibliothekartag 2008 = 0.5?
14. April 2008 um 18:10 11 Kommentare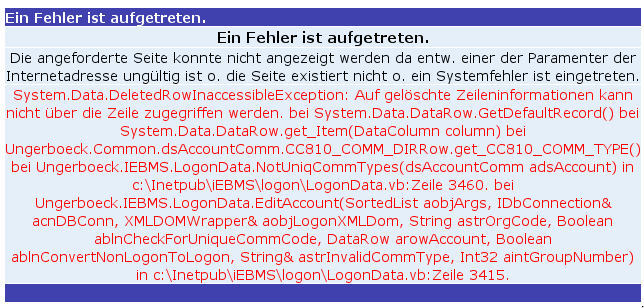
Fehlermeldung bei der Anmeldung
Ein weiteres Beispiel dafür, dass Bibliotheken eigenen technischen Sachverstand benötigen anstatt outzusourcen bietet die Webseite des Bibliothekartags 2008 in Mannheim. Sieht schön aus, ist aber Murx. Statt wesentlicher Informationen in zeitgemäßer Form gibt es Grußworte und einen Offenen Brief an die bibliothekarische Fachöffentlichkeit – als JPG!? Nicht das Tagungsweblog wird eingebunden, sondern ein totes „Forum„. Die Programmübersicht, eigentlich ja der Kern einer solchen Webseite, ist aufgrund von CSS-Spielereien völlig unbrauchbar (der Auslöser dieses Rants). Einfache Tabelle? Thematische Übersicht? Liste der Referenten? Verlinkte Raumpläne? Alles Fehlanzeige. Dass für die Stadtpläne nicht einfach Google-Maps verwendet wurde ist da noch zu vernachlässigen und Ortsangaben wie „Treffpunkt: Foyer der UB, Plöck 107-109, 69117 Heidelberg (Bitte geben Sie als Suchwort ‚Plöck 109‘ ein)“ haben wenigstens Seltenheitswert 😉
Ich finde es äußerst problematisch, wie sich Bibliotheken unnötig in Abhängigkeit von Firmen begeben (hier diese Firmen) und dabei ihrer eigenen Handlungsspielräume und Fähigkeiten einschränken. „Mal schnell“ etwas an der Webseite oder am OPAC ändern geht nicht dann nicht mehr so einfach und/oder kostet zusätzlich Geld. Dem Hinweis zur Entwicklung eigener Kompetenzen von Anne Christensen im Beluga-Projekt kann ich mich nur anschließen. Mir geht der zwar Web-2.0-Leierkasten inzwischen auf den Geist (und ich werde freiwillig keine „Was ist und was soll XY 2.0“-Vorträge mehr halten), aber anscheinend ist es noch immer nicht angekommen, das im Web nur überlebt, wer sich selber mit den zahlreichen Diensten und Angeboten vertraut macht und sie selber ausprobiert. Für Konferenzen fallen mir neben Google Maps spontan Venteria und Mixxt ein und eine Programmübersicht kann so ausschauen. Schön wäre es auch, wenn die einzelnen Veranstaltungen mit Microformats erschlossen sind, jeweils eine eigene URL bekommen und aktiv zum Tagging angeboten werden, so dass sich jeder Besucher mit einem beliebigen Tagging-Dienst und/oder Kalenderprogramm einfach einen Plan zusammenstellen kann. Auch die Einbindung von Feeds zur Veranstaltung wäre nett – wenn sich Bibliotheken nicht mit Sacherschließung, Verschlagwortung und Metadaten auskennen, mit was dann?! Die UB Mannheim zeigt mit ihrem Blog, dem (versteckten) Konferenzblog und Überlegungen zu Tagging zumindest, dass es auch anders geht. Die Pläne zum kritiklosen Einsatz von Primo überzeugen dafür weniger – wurden Alternativen wie Encore, VuFind, OpenBib etc. überhaupt ernsthaft in Betracht gezogen?
Als Tags für Beiträge zum Bibliothekartag schlage ich „bibliothekartag2008“ (genutzt hier, kein Tag bei netbib) und „#bibtag08“ vor – sowas sollte eigentlich auch auf der Webseite zur Veranstaltung vorgegeben und erklärt werden, sonst werden die Tags gar nicht erst verwendet, vergessen oder uneinheitlich benutzt – wie teilweise passiert zur Inetbib 2008: dort wurde mal getaggt mit Leerzeichen, mal ohne und mal ganz ohne Tag. Naja, Googles Volltextsuche wird es schon richten – aber dafür brauchen wir dann auch keine Bibliothekare mehr.
P.S: Beim Versuch mich anzumelden, gab das Registrierungssystem „>sogleich eine Fehlermeldung von sich, als ich meine Telefonnummer korrigieren wollte. Kein Wunder wenn das m:con Congress Center Rosengarten VisualBasic unter IIS verwendet 😉
Aggregation von Metadaten aus Social Software-Diensten mit Aloe
3. April 2008 um 18:33 1 KommentarIm Vortrag „Sagt wer? Metadaten im Web“ auf der re:publica 08 sprach Martin Memmel darüber, „wie Daten von Experten, Maschinen und Endusern kombiniert“ werden können. Dabei stellte er das Projekt Aloe vor (link), in dem am DFKI Metadaten aus verschiedenen Quellen kombiniert und annotiert werden können. Alle Funktionen sind auch als Webservice verfügbar. Interessant sah die im Vortrag vorgestellte Tagging-Funktion aus, die Tag-Vorschläge aus mehreren Tagging-Diensten zusammenführt. Mehr dazu in den Vortragsfolien bei Slideshare.
Wirklich interessant werden solche aggregierenden Dienste meiner Meinung nach erst, sobald sich offene Standardformate zum Austausch von Kommentaren, Bewertungen, Tags etc. und anderen Metadaten durchsetzen. Bisher nicht bekannt in diesem Kontext war mir APML. Ein kritischer Punkt, der am Ende heftig diskutiert wurde, sind die Rechte an Metadaten und was juristisch und moralisch möglich und vertretbar ist. Ist es beispielsweise legitim, aus verschiedenen Social Networking-Plattformen soziale Graphen zusammenzuführen und weiterzugeben? Welche Rechte an Metadaten kann es überhaupt geben und welche lassen sich überhaupt durchsetzen? In jedem Fall spannend, wie es mit der Zusammenführung von Daten aus verschiedenen Diensten weitergeht.
Morgen nimmt Martin Memmel auch noch am Panel Social Media in der Wissenschaft teil, wo die „Möglichkeiten und Grenzen einer Wissenschaft 2.0“ diskutiert werden.
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare