Digitalisate weiterverarbeiten und anzeigen
20. Mai 2008 um 14:47 4 KommentareNur 48 Stunden nach meinem Vorschlag, den digitalisierten Simplicissimus vom PDF über METS/MODS im DFG-Viewer anzeigen zu lassen, meldete sich Christian Mahnke mit einem entsprechenden Python-Skript bei mir 🙂 Inzwischen hat er sogar einige Verbesserungen vorgenommen, die Konvertierung klappt einwandfrei! Hier ein Beispiel einer erzeugten XML-Datei, im DFG-Viewer sieht das dann so aus. Statt dem DFG-Viewer kann die METS/MODS-Datei übrigens auch in einer anderen Anwendung angesehen werden, zum Beispiel mit dem METS Navigator. Weitere METS Werkzeuge listet die LOC auf.
Ein guter Ansatz ist vielleicht auch, sich mal einige der vielen existierenden Comic Viewer anzuschauen. Während in der Bibliothekswelt nämlich noch an Prototypen und Projekten gewerkelt wird, haben private Sammler längst einfache Lösungen zur Archivierung und Präsentation von Digitalisaten geschaffen. Ich vermute jedoch, dass „Wir wollen existierende OpenSource Comic-Viewer so erweitern, dass sie mit METS/MODS-Daten umgehen können“ nicht gut bei DFG-Gutachtern ankommt – womit diese mal wieder ihre mangelnde Kompetenz unter Beweis stellen würden.
Mit dem Skript von Christian lassen sich prinzipiell Digitalisate als Images aus einem PDF auslesen und in verschiedene Größen skalieren. Die Metadaten müssen jedoch anderswo herkommen. Entweder man holt sich die Daten über HTML oder über eine saubere Schnittstelle wie SRU. Im Idealfall wird sogar MARC21 angeboten, das mit Stylesheets der LOC nach MODS konvertiert werden kann.
Statt Digitalisate alter Zeitschriften können auch neue Scans von Inhaltsverzeichnissen zur Anzeige gebracht werden. So geht’s (die Suche ausgehend von einer ISBN sollte nicht schwieriger sein). Wie wäre es, statt Coverbildern im Katalog Thumbnails von Inhaltsverzeichnissen anzuzeigen? Sauber in Services getrennt könnte das folgendermaßen umgesetzt werden:
- Webservice A bekommt ISBN/PND/Bibkey/…, ermittelt den Titel und liefert eine Thumbnail sowie einen Link zur Vollanzeige des Inhaltsverzeichnis (beispielsweise per SeeAlso)
- Webservice B liefert zu einem Titel das PDF und die Metadaten (Beispiel: Katalog mit SRU-Schnittstelle)
- Webservice C erhält eine PDF-URL und Metadaten in MODS-Daten und erzeugt daraus Bitmaps und METS/MODS und stellt diese bereit
- Webservice D kann METS/MODS anzeigen (Beispiel: DFG-Viewer)
Viel Spaß beim Umsetzen, Experimentieren und Ideen sammeln!
Mehr zu Bibliothekssoftware
7. Mai 2008 um 12:45 Keine KommentareAnknüpfend an die US-Umfrage zu Bibliothekssystemen möchte ich auf die unterhaltsame, vonLibrary Mistress ausgegrabene Liste „Bibliothekssoftware 1991“ hinweisen. Vor acht Jahren gab es vom DBI mal eine Umfrage zum „Softwareeinsatz in Bibliotheken“ – das ist aber höchstens noch historisch von Interesse. Michael Lackhoff bietet eine Linksammlung zu Bibliothekssoftware, die allerdings auch nur einen Ausschnitt enthält und nicht ganz aktuell ist – so fehlen beispielsweise die gesamten PICA-Produkte (was auch daran liegt, dass PICA bzw. OCLC, die Produkte nicht richtig vermarkten), neuere Entwicklungen wie VuFind und Evergreen und hoch-relevante Hintergrund-Techniken wie Lucene (mehr zu aktuellen Entwicklungen bei OSS4LIB).
Statt monolithischer Bibliothekssoftware „von der Stange“ sind nämlich die einzelnen Komponenten (Services) und ihre Verzahnung wichtig. Leider ist dagegen noch immer die Vorstellung verbreitet, dass man sich als Bibliothek besser an einen Hersteller wendet, der einem in schön bunter Verpackung, eine Black-Box verkauft. Eine Bibliothek, die sich aber nicht selbst Gedanken darüber macht, welche Daten aus welchen Quellen wie zusammengeführt und in welcher Form bereitgestellt werden, kann eigentlich gleich ihre Mitarbeiter entlassen und auf vollautomatischen Betrieb umstellen – denn in Zukunft wird es sich bei immer mehr Publikationen um elektronische Publikationen handeln, also Daten. Folgende Vorstellung ist leider nicht aus der Luft gegriffen:
Ich dachte wir kaufen Produkt X und die richtigen Daten kommen von Zauberhand hinein, konvertieren sich von alleine und werden auf magische Weise so bereitgestellt, wie es der Nutzer möchte.
Dynamische Kataloganreicherung mit Webservices
16. April 2008 um 17:36 3 KommentareDie Folien des Vortrags „Dynamische Kataloganreicherung mit Webservices“ am 15.4.2008 Berliner Bibliothekswissenschaftlichem Kolloquium (BBK) sind jetzt online bei Slideshare. In der aktuellen letzten iX (04/2008) gibt es einen Artikel zu Webschnittstellen, die dort erwähnten Sechs Wahrheiten über Freie APIs hätte ich auch noch aufnehmen sollen (auf die Nachteile von Webservices bin ich im Vortrag nicht eingegangen).
Eine Gute Übersicht von Webanwendungen, Widgets und Plugins, die Bibliotheken ihren Nutzern anbieten können, bietet die University of Texas Libraries, Austin. Vom Facebook-Widget bis zum Hinweis auf Zotero ist alles dabei und übersichtlich erklärt. Neue Widgets können direkt empfohlen werden und werden im Blog vorgestellt. Die Bibliothek ist unter Anderem auch Google Book Search-Partner und veröffentlicht Videos bei YouTube.
P.S: Und wo ich so sehr die Wichtigkeit von Standards betont habe: so sollte ein Standard nicht aussehen. Wie bei anderen Themen (Wikipedia-Artikeln, Kongress-veranstaltern etc.) reicht es nicht aus, auf den Namen des Herausgebers zu schauen, um Qualität von Müll unterscheiden zu können – ISO-„Standards“ sind beispielsweise nicht nur nicht frei zugänglich (und damit schon mal zweifelhaft) sondern in einigen Fällen eher das Gegenteil eines Standarts.
Working group on digital library APIs and possible outcomes
13. April 2008 um 14:48 3 KommentareLast year the Digital Library Federation (DLF) formed the „ILS Discovery Interface Task Force„, a working group on APIs for digital libraries. See their agenda and the current draft recommendation (February, 15th) for details [via Panlibus]. I’d like to shortly comment on the essential functions they agreed on at a meeting with major library system (ILS) vendors. Peter Murray summarized the functions as „automated interfaces for offloading records from the ILS, a mechanism for determining the availability of an item, and a scheme for creating persistent links to records.“
On the one hand I welcome if vendors try to agree on (open) standards and service oriented architecture. On the other hand the working group is yet another top-down effort to discuss things that just have to be implemented based on existing Internet standards.
1. Harvesting: In the library world this is mainly done via OAI-PMH. I’d also consider RSS and Atom. To fetch single records, there is unAPI – which the DLF group does not mention. There is no need for any other harvesting API – missing features (if any) should be integrated into extensions and/or next versions of OAI-PMH and ATOM instead of inventing something new. P.S: Google Wave shows what to expect in the next years.
2. Search: There is still good old overblown Z39.50. The near future is (slightly overblown) SRU/SRW and (simple) OpenSearch. There is no need for discussion but for open implementations of SRU (I am still waiting for a full client implementation in Perl). I suppose that next generation search interfaces will be based on SPARQL or other RDF-stuff.
2. Availability: The announcement says: „This functionality will be implemented through a simple REST interface to be specified by the ILS-DI task group“. Yes, there is definitely a need (in december I wrote about such an API in German). However the main point is not the API but to define what „availability“ means. Please focus on this. P.S: DAIA is now available.
3. Linking: For „Linking in a stable manner to any item in an OPAC in a way that allows services to be invoked on it“ (announcement) there is no need to create new APIs. Add and propagate clean URIs for your items and point to your APIs via autodiscovery (HTML link element). That’s all. Really. To query and distribute general links for a given identifier, I created the SeeAlso API which is used more and more in our libraries.
Furthermore the draft contains a section on „Patron functionality“ which is going to be based on NCIP and SIP2. Both are dead ends in my point of view. You should better look at projects outside the library world and try to define schemas/ontologies for patrons and patron data (hint: patrons are also called „customer“ and „user“). Again: the API itself is not underdefined – it’s the data which we need to agree on.
Bücher, die ich schon mal ausgeliehen hatte…
15. März 2008 um 15:38 1 KommentarHaftgrund berichtet, dass es in Wiener Büchereien „aus Datenschutzgründen“ nicht mehr möglich ist, im Bibliothekssystem auf Wunsch die Titel zu speichern, die man in der Vergangenheit schon mal ausgeliehen hatte. Schön, dass Bibliotheken anders als die meisten Webanbieter auf Datenschutz achten und nicht bis in alle Ewigkeiten speichern, wer wann was gemacht hat. In diesem Fall ist die Begründung aber wohl eher vorgeschoben, schließlich klingt „Datenschutz“ auch kompetenter als „unsere Software kann das nicht und/oder wir wissen nicht wie man sowas technisch umsetzt“. Die Möglichkeit, alle ausgeliehenden Bücher automatisch in einer Liste abzuspeichern, ist meinem Eindruck nach in Bibliotheken ebenso nützlich wie selten.
Wie Edlef bemerkt, kann man ausgeliehene Bücher ja auch „in citavi, Librarything oder beliebigen anderen Literaturverwaltungssystemen für sich selbst [speichern]“ – was prinzipiell tatsächlich die bessere Variante ist. Nur sollten Bibliotheken Nutzer dabei nicht in „kenn wa nich, wolln wa nicht, ham wa nich, geht nich“-Manier abspeisen, sondern aktiv für die Verknüpfung von Bibliothekssystemen mit Literaturverwaltungssystemen sorgen. Alles was über ein Feld „Ausleihen automatisch bei BibSonomy/LibraryThing/etc. eintragen“ im Benutzerkonto hinausgeht, ist nicht zumutbar und überflüssig.
Ein Lösungsansatz gemäß Serviceorientierter Architektur sähe folgendermaßen aus:
Das Ausleihsystem bekommt eine Webschnitttstelle, über die Nutzer abfragen können, welche Medien sie zur Zeit ausgeliehen haben. Wenn dabei RSS oder ATOM eingesetzt wird (natürlich nur über HTTPS und mit Passwort), sollten gängige Feed-Aggregatoren damit klarkommen. Bisher muss der Zugang zum Ausleihsystem für jede Anwendung wie Bücherwecker einzeln gehackt werden, was mühsam und fehleranfällig ist. Die ausgeliehenen Werke sollten (per URL-Parameter steuerbar) in möglichst vielen Datenformaten beschrieben werden. Prinzipiell reicht aber auch die Standard-Kurztitelanzeige und ein Identifier, mit dem z.B. über unAPI weitere Details in verschiedenen Datenformaten angefordert werden können. Zusätzlich zu diesem Pull-Verfahren sollte die Möglichkeit gegeben werden, á la Pingback andere Dienste zu benachrichtigen sobald ein Benutzer ein Medium ausgeliehen hat.
Den Rest (das automatische Eintragen in eine Literaturverwaltung) kann – und sollte – bei gegebenen APIs eine eigene Anwendung übernehmen. Es würde mich nicht wundern, wenn die fixen Entwickler von LibraryThing das selber basteln oder sich ein Student im Rahmen einer Diplom- oder Bachelorarbeit daran setzt. Sobald saubere, einfache Schnittstellen verfügbar sind, ist der Aufwand für neue „Mashups“ und Zusatzdienste minimal.
Linkserver auch beim BSZ
14. Februar 2008 um 00:20 1 KommentarIch muss zugeben, dass ich den Verbundkatalog des Südwestdeutschen Bibliotheksverbundes (SWB) nur sehr selten nutze und auch nur ganz zufällig darauf gestoßen bin – jedenfalls ist mir gerade aufgefallen, dass das BSZ (die Zentrale des SWB) ebenfalls einen Linkserver für seine Kataloge anbietet. Die Eigenentwicklung des BSZ wird folgendermaßen beschrieben:
Anreicherung des Katalogs mit Internet-Ressourcen:
Die Einzeltrefferanzeige im Web-Katalog kann ergänzt werden durch die Einblendung von dynamisch erzeugten Links zum Buchhandel (z.Zt. amazon, lehmanns, kno-k&v, libri, abebooks, booklooker, zvab). Soweit dort vorhanden werden das Cover und ein direkter Link zum Medium (i.e. der ISBN) angezeigt. Der Link-Server läuft zentral im BSZ

Im Verbundkatalog werden die Links mit dem Button „Verfügbarkeit im Buchhandel prüfen“ eingeblendet, wie zum Beispiel bei diesem guten Buch ausprobiert werden kann (siehe nebenstehendes Bild). Die Einbindung geschieht zwar nicht über eine sauber definierte Schnittstellen sondern als proprietärer HTML-Batzen, aber prinzipiell sehe ich kein Hindernis, den Service auf SeeAlso umzustellen, so dass verschiedene Linkserver einfacher gemeinsam in unterschiedliche Anwendungen eingebunden werden können. Ich habe mir erstmal verkniffen, zur Demonstration einen vollständigen SeeAlso-Proxy zu schreiben zumal dazu ein kleiner Trick notwendig wäre (stattdessen gibt es einen experimentellen Proxy für Google Buchsuche). Das Prinzip ist jedenfalls das selbe wie bei den Linkservern der VZG des GBV. Ein spontanes Lob an die Kollegen im Süden!
P.S: Der Linkserver des BSZ nimmt wie isbn2wikipedia auch ISBNs und liefert (in zusätzlichem HTML) eingebettete Links – ich hoffe das führt nicht zur irrigen Annahme, dass Linkserver nur mit ISBNs funktionieren!
P.P.S: Ich höre schon (wie bei Wikipedia) den Aufschrei der Entrüstung, aber muss es mal deutlich sagen: Google Buchsuche ist sehr nützlich und ein Link darauf fast immer ein Mehrwert. So habe ich im konkreten Fall zwar keinen Volltext aber wie gesucht Rezensionen gefunden (die FAZ-Kritik von Martin Lhotzky ist übrigens Bullshit) – Bibliotheken müssten für sowas wahrscheinlich erstmal Analysen und Regelwerke erstellen, was eine Rezension sei und wer wie wann bestimmen darf, was wie wo genau als zusätzlicher Link eingetragen wird – anstatt den Nutzer einfach selber entscheiden zu lassen.
Schnittstelle für Verfügbarkeitsdaten von Bibliotheksbeständen
21. Januar 2008 um 11:22 4 KommentareLetzen Dezember habe ich über Serviceorientierte Architektur geschrieben und bin unter Anderem auf den Heidelberger UB-Katalog eingegangen. Dabei ging es darum, wie Daten einzelner Exemplare von Bibliotheksbeständen – speziell Verfügbarkeitsdaten – über eine Schnittstelle abgefragt werden können. Bislang gibt es dafür keinen einfachen, einheitlichen Standards sondern höchstens verschiedende proprietäre Verfahren. Till hat mich zu Recht auf den Artikel „Beyond OPAC 2.0: Library Catalog as Versatile Discovery Platform“ hingewiesen, in dem die API-Architektur des Katalogs an der North Carolina State University vorgestellt wurde. Die Beispiele zeigen gut, was mit dem Buzzword „Serviceorientierte Architektu“ eigentlich gemeint ist, wie sowas in Bibliotheken umgesetzt werden kann und was für Vorteile der Einsatz von einfachen, webbasierten Schnittstellen bringt. Die als CatalogWS bezeichnete API ist – wie es sich gehört – offen dokumentiert. CatalogWS enthält einen Catalog Availability Web Service, der ausgehend von einer ISBN ermittelt, in welchen (Teil)bibliotheken ein Titel verfügbar oder ausgeliehen ist.
Bei Bedarf könnte ich mal versuchen, diese API für die GBV-Kataloge zu implementieren. Andererseits sollte man sich vielleicht erstmal Gedanken darüber machen, was es noch für Kandidaten für eine Verfügbarkeitsschnittstelle gibt und welche Daten über so eine Schnittstelle abfragbar sein sollten: Das NCIP-Protokoll scheint mir wie Z39.50 nicht wirklich zukunftsfähig zu sein. Janifer Gatenby macht in ihrem Vortrag „Bridging the gap between discovery and delivery“ (PPT) weitere durchdachte Vorschläge. Auf den Mailinglisten CODE4LIB und PERL4LIB habe ich letzte Woche herumposaunt, wie wichtig eine Holding-API wäre und dass das doch alles eigentlich ganz einfach sei. Neben Iinteressanten Bemerkungen zu FRBR bin ich daraufhin auf Holding-data in Z39.50 hingewiesen worden. In den PICA-LBS-Systemen stehen die Verfügbarkeitsdaten soweit ich es herausgefunden, habe im Feld 201@, aber nur teilweise. Für die weitere Umsetzung wäre es wahrscheinlich sinnvoll, erstmal alle in der Praxis vorkommenden Verfügbarkeits-Stati (ausleihbar, Präsenzbestand, Kurzausleihe, ausgeliehen, unbekannt…) zu ermitteln. Für elektronische Publikationen sollte die Schnittstelle außerdem irgendwie mit existierenden Linkresolvern zusammenarbeiten können. Eine einfache Schnittstelle für Verfügbarkeitsdaten von Bibliotheken ist also nicht ganz trivial, aber solange nicht jeder Spezialfall berücksichtigt wird oder erstmal ein Gremium eingesetzt werden muss, dürfte es machbar sein. Hat sonst noch jemand Interesse?
Heidelberger Katalog auf dem Weg zu Serviceorientierter Architektur
23. Dezember 2007 um 20:59 4 KommentareDie zunehmende Trennung von Bibliotheksdaten und ihrer Präsentation zeigt „HEIDI“, der Katalog der Unibibliothek Heidelberg. Vieles, was moderne Bibliothekskataloge bieten sollten, wie eine ansprechende Oberfläche, Einschränkung der Treffermenge per Drilldown, Permalinks, Exportmöglichkeit (u.A. direkt nach BibSonomy), RSS-Feeds und nicht zuletzt eine aktuelle Hilfe für Benutzer ist hier – zwar nicht immer perfekt, aber auf jeden Fall vorbildhaft – umgesetzt. Soweit ich es von Außen beurteilen kann, baut der Katalog auf zentralen Daten des Südwestdeutschen Bibliotheksverbundes (SWB) und lokalen Daten des lokalen Bibliothekssystems auf. Zum Vergleich hier ein Titel in HEIDI und der selbe Titel im SWB-Verbundkatalog. Aus dem Lokalsystem werden die Titeldaten mit Bestands- und Verfügbarkeitsdaten der einzelnen Exemplare angereichter, also Signatur, Medien/Inventarnummer, Standort, Status etc.:

Die tabellarische Ansicht diese Daten erinnert mich an WorldCat local, das sich zu WorldCat teilweise so verhält wie ein Bibliotheks-OPAC zu einem Verbundsystem. Hier ein Beispieldatensatz bei den University of Washington Libraries (und der gleiche Datensatz in WorldCat). Die Exemplardaten werden aus dem lokalen Bibliothekssystem als HTML-Haufen per JavaScript nachgeladen, das sieht dann so aus:

Bei HEIDI findet die Integration von Titel- und Exemplardaten serverseitig statt, dafür macht der Katalog an anderer Stelle rege von JavaScript Gebrauch. In beiden Fällen wird eine proprietäres Verfahren genutzt, um ausgehend von einem Titel im Katalog, die aktuellen Exemplardaten und Ausleihstati zu erhalten. Idealerweise sollte dafür ein einheitliches, offenes und webbasiertes Verfahren, d.h. ein RDF-, XML-, Micro- o.Ä. -format und eine Webschnittstelle existieren, so dass es für den Katalog praktisch egal ist, welches lokale Ausleih- und Bestandssystem im Hintergrund vorhanden ist. Die Suchoberfläche greift damit als als ein unabhängiger Dienst auf Katalog und Ausleihsystem zu, die ihrerseits eigene unabhängige Dienste mit klar definierten, einfachen Schnittstellen bereitstellen. Man spricht bei solch einem Design auch von „Serviceorientierter Architektur“ (SOA), siehe dazu der Vortrag auf dem letzten Sun-Summit. Eigentlich hätte beispielsweise die IFLA sich längst um einen Standard für Exemplardaten samt Referenz-implementation kümmern sollen, aber bei FRBR hat sie es ja auch nicht geschafft, eine RDF-Implementierung auf die Beine zu stellen; ich denke deshalb, es wird eher etwas aus der Praxis kommen, zum Beispiel im Rahmen von Beluga. Der Heidelberger Katalog setzt SOA noch nicht ganz um, geht allerdings schon in die richtige Richtung. Beispielweise wird parallel im Digitalisierten Zettelkatalog DigiKat gesucht und ggf. ein Hinweis auf mögliche Treffer eingeblendet. Wenn dafür ein offener Standard (zum Beispiel OpenSearch oder SRU) verwendet würde, könnten erstens andere Kataloge ebenso dynamisch zum DigiKat verweisen und zweitens in fünf Minuten andere Kataloge neben dem DigiKat hinzugefügt werden.
Ein weiteres Feature von HEIDI sind die Personeneinträge, von denen auf die deutschsprachige Wikipedia verwiesen wird – hier ein Beispiel und der entsprechende Datensatz im SWB. Die Verlinkung auf Wikipedia geschieht unter Anderem mit Hilfe der Personendaten und wurde von meinem Wikipedia-Kollegen „Kolossos“ erdacht und umgesetzt. Über einen statischen Link wird eine Suche durch einen Webservice angestossen, der mit Hilfe der PND und des Namens einen passenden biografischen Wikipedia-Artikel sucht. Ich könnte den Webservice so erweitern, dass er die SeeAlso-API verwendet (siehe Ankündigung), so dass Links auf Wikipedia auch nur dann angeboten werden, wenn ein passender Artikel vorhanden ist. Für einen verlässlichen und nachhaltigen Dienst ist es dazu jedoch notwendig, dass der SWB seine Personenangaben und -Normdaten mit der PND zusammenbringt. Natürlich könnte auch nach Namen gesucht werden aber warum dann nicht gleich den Namen einmal in der PND suchen und dann die PND-Nummer im Titel-Datensatz abspeichern? Hilfreich wäre dazu ein Webservice, der bei Übergabe eines Namens passende PND-Nummern liefert. Die Fälle, in denen eine automatische Zuordnung nicht möglich ist, können ja semiautomatisch gelöst werden, so wie es seit über zwei Jahren der Wikipedianer APPER mit den Personendaten vormacht. Hilfreich für die Umsetzung wäre es, wenn die Deutsche Nationalbibliothek URIs für ihre Normdaten vergibt und ihre Daten besser im Netz verfügbar macht, zum Beispiel in Form einer Download-Möglichkeit der gesamten PND.
P.S.: Hier ist testweise die PND-Suche in Wikipedia als SeeAlso-Service umgesetzt, zum Ausprobieren kann dieser Client verwendet werden, einfach bei „Identifier“ eine PND eingeben (z.B. „124448615“).
Chatbox als Widget im Katalog
10. Dezember 2007 um 11:07 Keine KommentareLambert weist in Netbib auf die Widget-basierte Einbindung einer Chatbox im Katalog hin, wenn eine Suche keine Treffer liefert. Ein schönes Beispiel dafür, wie einzelne Dienstleistungen als eigenständige Services angeboten und kombiniert werden können. Mit der Ende September vorgestellte Universal Widget API (UWA) könnte das etwas einfacher werden. Dass trotz aller Begeisterung nicht jeder Service in jedem Kontext sinnvoll ist, dürfte klar sein – ein Haufen Widgets macht noch keine Bibliothek, dafür sind Bibliothekare notwendig, die eigene Ideen für Services und Widgets entwickeln und bestehende Dienste ausprobieren – die konkrete Programmierung neuer Widgets kann ja gerne Experten überlassen werden, aber Existierendes zusammenführen, Ausprobieren, Diskutieren, und Ideen entwickeln kann nicht einigen Wenigen überlassen werden!
Verweise auf passende Rezensionen
5. Dezember 2007 um 16:35 4 KommentareNachdem ich in einer Fortbildung (siehe slides) am Rande die Realisierung von Links auf Wikipedia mittels des SeeAlso-Protokolls vorgestellt habe, kam von einer Teilnehmerin die Idee, auf die selbe Weise auf Rezensionen zu verweisen. Neben Amazon (wo Rezensionen manipuliert werden) und LibraryThing gibt es eine Vielzahl von Rezensionsdiensten von Fachreferenten und Wissenschaftlern. Leider bekommt dies außerhalb enger Fachcommunities kein Schwein mit, da Rezensionen weder systematisch erschlossen werden, noch praktikabel recherchierbar sind – dies gilt anscheinend auch für Rezensionen in Zeitungen, z.B. bei der ZEIT. Die Idee, über einen Linkserver Verweise auf passende Rezensionen zu liefern, finde ich wunderbar, weshalb ich gleich mal ein Konzept erstellt habe. Hier nur das Diagram, ausführlich im GBV-Wiki:
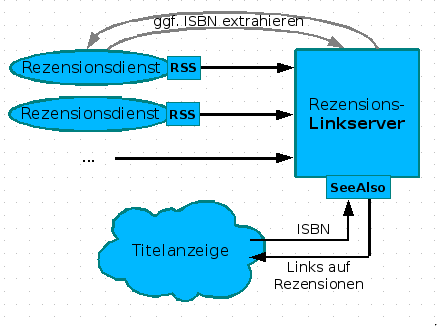
Leider hinken die meisten Rezensionsdienste dem Stand der Technik hinterher und bieten keine (oder kaputte) Feeds an. Wollen die nicht gelesen werden? Nun ja, vielleicht wachen Sie noch auf. Kennt jemand weitere Rezensionsdienste mit benutzbaren Feeds? So lange nicht genügend Rezensionsdienste verfügbar sind, ist der skizzierte Linkserver den Aufwand nicht wert, aber das kann ja noch kommen. Bitte mehr solcher Ideen! Wer nicht weiß, was Feeds sind und sich nicht vorstellen kann, wie ein Linkserver funktioniert, oder den Unterschied zwischen Indexbasierter und Metasuchmaschine nicht einigermaßen verinnerlicht hat, wird auch nicht auf die Ideen kommen, die notwendig sind, damit Bibliotheken nicht in der Bedeutungslosigkeit verschwinden. Deshalb sind Fortbildung und genügend freie Zeit zum Experimentieren so wichtig – zum Beispiel mit diesen Web 2.0-Diensten!
P.S: Neben Rezensionen und Lins auf Wikipedia können auch andere Informationen zu einem Werk von Interesse sein, z.B. Zusammenfassungen, Erwähnungen in Blogs etc.
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare