SuMa-eV Kongress 2008
30. September 2008 um 22:53 Keine KommentareLetzten Donnerstag fand in Berlin die 5. Tagung des SuMa-eV statt, Carl Meyer hat einen pointierten Bericht geschrieben. Preisträger des SuMa Award in der Sparte Musik war die Altpunker-Band „Die Betakteten“ mit dem „Lied vom Datenkraken„. Noch besser als das Lied ist fast die Aufführung in der Vertretung des Landes Niedersachsen beim Bund (sic!) – das hätte sich Sänger Micro zu seiner Zeit bei den Abstürzenden Brieftauben wohl eher nicht gedacht. Am 10. Oktober geht die Tour dann weiter zur Fachtagung für Datenschutzbeauftragte.
Suchmaschinen-Vorträge auf der Inetbib 2008
11. April 2008 um 12:35 3 KommentareDas Panel zu Suchmaschinen auf der Inetbib 2008 war erfreulicherweise durchweg mit Experten besetzt: Der Vortrag von Stefan Keuchel (Pressesprecher von Google Deutschland) bestand ausschließlich aus einer werbenden Darstellung der populärsten Google-Produkte. Muß man alles mal gesehen haben, aber dann reicht es auch (s.a. Netbib-Weblog). Ebenfalls hauptsächlich um Google ging es im Vortrag über Prof. Hendrik Speck (FH Kaiserslautern) über die „Entwicklung des Suchmaschinenmarktes“. Die interessanten Vortragsfolien stehen unter CC-BY-SA zur Verfügung – der Link führt allerdings zur Zeit ins 404 – (s.a. Netbib-Weblog). Der Vortrag von Prof. Mario Fischer (FH Würzburg-Schweinfurt) über Suchmaschinen-Optimierung war sehr unterhaltsam, obgleich er hauptsächlich Binsenweisheiten enthielt (Webseite für die Crawler einfach zugänglich machen, relevante Suchworte verwenden, etc.). Interessant wäre mal ein ähnlicher Vortrag zur „OPAC-Optimierung“. Ob die Teilnehmer über die Beispiele vermurkster Kataloge, in denen Nutzer nicht das finden, was sie suchen, ebenfalls so lachen würden wie in Fischers Vortrag über Webseiten und Suchmaschinen?
Google-Wikipedia-Connection and the decay of academia
10. Dezember 2007 um 02:49 6 KommentareMathias pointed [de] me to a lengthy and partly ridiculous „Report on dangers and opportunities posed by large search engines, particularly Google“ by Hermann Maurer [de] (professor at the IICM, Graz) and various co-authors, among them Stefan Weber, whose book [de], I already wrote about [de]. Weber is known as well as Debora Weber-Wulff for detecting plagiarism in academia – a growing problem with the rise of Google and Wikipedia as Weber points out. But in the current study he (and/or his colleauges) produced so much nonsense that I could not let it uncommented.
Beitrag Google-Wikipedia-Connection and the decay of academia weiterlesen…
Verweise auf passende Rezensionen
5. Dezember 2007 um 16:35 4 KommentareNachdem ich in einer Fortbildung (siehe slides) am Rande die Realisierung von Links auf Wikipedia mittels des SeeAlso-Protokolls vorgestellt habe, kam von einer Teilnehmerin die Idee, auf die selbe Weise auf Rezensionen zu verweisen. Neben Amazon (wo Rezensionen manipuliert werden) und LibraryThing gibt es eine Vielzahl von Rezensionsdiensten von Fachreferenten und Wissenschaftlern. Leider bekommt dies außerhalb enger Fachcommunities kein Schwein mit, da Rezensionen weder systematisch erschlossen werden, noch praktikabel recherchierbar sind – dies gilt anscheinend auch für Rezensionen in Zeitungen, z.B. bei der ZEIT. Die Idee, über einen Linkserver Verweise auf passende Rezensionen zu liefern, finde ich wunderbar, weshalb ich gleich mal ein Konzept erstellt habe. Hier nur das Diagram, ausführlich im GBV-Wiki:
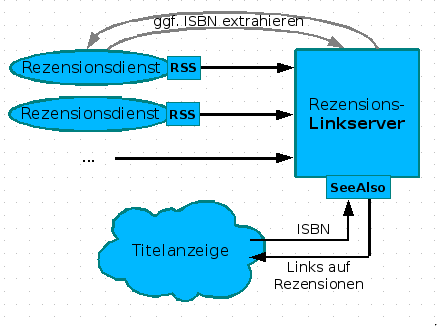
Leider hinken die meisten Rezensionsdienste dem Stand der Technik hinterher und bieten keine (oder kaputte) Feeds an. Wollen die nicht gelesen werden? Nun ja, vielleicht wachen Sie noch auf. Kennt jemand weitere Rezensionsdienste mit benutzbaren Feeds? So lange nicht genügend Rezensionsdienste verfügbar sind, ist der skizzierte Linkserver den Aufwand nicht wert, aber das kann ja noch kommen. Bitte mehr solcher Ideen! Wer nicht weiß, was Feeds sind und sich nicht vorstellen kann, wie ein Linkserver funktioniert, oder den Unterschied zwischen Indexbasierter und Metasuchmaschine nicht einigermaßen verinnerlicht hat, wird auch nicht auf die Ideen kommen, die notwendig sind, damit Bibliotheken nicht in der Bedeutungslosigkeit verschwinden. Deshalb sind Fortbildung und genügend freie Zeit zum Experimentieren so wichtig – zum Beispiel mit diesen Web 2.0-Diensten!
P.S: Neben Rezensionen und Lins auf Wikipedia können auch andere Informationen zu einem Werk von Interesse sein, z.B. Zusammenfassungen, Erwähnungen in Blogs etc.
Wird dem Theseus-Projekt (100 Millionen) Geld für eine Begleitstudie hinterhergeworfen?
21. August 2007 um 23:48 1 KommentarBis zum 15.9. läuft eine Ausschreibung des Bundesministerium für Wirtschaft und Technologie zu einer „Begleitforschung für das Forschungsprogramm THESEUS“ (ich berichtete bereits letzten Monat). Mit der Begleitforschung soll „sichergestellt werden, dass die Fördermaßnahme mit hoher Effizienz umgesetzt, die Qualität der wissenschaftlichen Arbeiten gesichert und das im Rahmen von THESEUS gewonnene Know-How schnell verbreitet wird“. Ich stelle hiermit meine folgende Begleitstudie dem BMWi vorab und kostenlos zur Verfügung:
Im Projekt THESEUS wurden mit Hilfe vieler Buzzwords zahlreiche Berichte, Studien und Prototypen erstellt und 100 Millionen Euro Forschungsgelder an 30 Partner aus Industrie, Wissenschaft und Forschung verteilt. Ende der Studie.
Mal im Ernst: Evaluation ist ja eine gute Idee, aber ich Frage mich, ob einem Großprojekt (bei dem jeder Teilnehmern hauptsächlich für sich möglichst viel Renommee und Geld abgreifen möchte aber am Ende für nichts in die Verantwortung genommen wird), mit solch zusätzlicher Metaforschung (bei der doch wieder die Freunde und Bekannten der Auftragnehmer im Boot sitzen) beizukommen ist. Wenn schon großspurig in der Projektbeschreibung von Web 2.0 und Web 3.0 die Rede ist, dann sollte das auch bei der Planung und Begleitung des Projektes deutlich werden. Wie wäre es statt einer aufwendigen und intransparenten Begleitstudie (die eigentlich ja auch wiederum evaluiert werden müsste) mit einigen wenigen, klaren Regeln für alle Beteiligten:
§ 1) alle im Rahmen von Theseus entwickelten Computerprogramme und Programmbibliotheken werden als Freie Software veröffentlicht und im Laufe des Projektes als Open Source zur Verfügung gestellt, so dass sie von unabhängiger Seite evaluiert, weitergenutzt und weiterentwickelt werden können.
§ 2) alle im Rahmen von Theseus erstellten Dokumente (Berichte, Anleitungen, Dokumentationen, Digitalisate etc.) werden im Laufe des Projektes als Freie Inhalte veröffentlicht, so dass sie von unabhängiger Seite evaluiert, weitergenutzt und weiterentwickelt werden können.
§ 3) die unter § 2 genannten Dokumente umfassen insbesondere auch alle im Rahmen des Theseus-Projektes anfallenden Verträge, Protokolle, Absprachen und Standards, für die zusätzlich eine zeitnahe Veröffentlichung bindent ist, so dass die innerhalb des Projektes getroffenen Entscheidungen von unabhängiger Seite kommentiert und ihre Einhaltung kontrolliert werden können sowie Geldverschwendung und Korruption durch Transparenz vermieden werden.
§ 4) bei Verstößen gegen §§ 1-3 werden den Beteiligten Projektpartern die Fördermittel gekürzt.
Zu einfach? Naiv? Undurchsetzbar? Na dann fällt bei 100 Millionen das Geld zur Augenwischerei in Form einer konsequenzlosen Begleitstudie ja auch nicht mehr ins Gewicht.
Apropos naiv: Das BMWi fordert, dass „Für die Darstellung von Ergebnissen [der Begleitstudie] […] die bestehende Internetseite http://theseus-programm.de in Absprache mit der hierfür vom THESEUS-Programm-Büro beauftragten Agentur genutzt werden [soll]“.
Abgesehen davon, dass jede qualifizierte Studie angesichts dieser Forderung zum Ergebnis kommen sollte, dass Geld für eine „Agentur“ rausgeschmissen wurde, weil die Projektpartner zu inkompetent waren, ein CMS bzw. eine gemeinsame Kommunikations- und Publikationsplattform zu nutzen, wird diese Agentur bzw. das „THESEUS-Programm-Büro“ wohl kaum relevante Kritik auf der eigenen Seite ermöglichen. Oder veröffentlicht die Chinesische Nachrichtenagentur Xinhua plötzlich auch Nachrichten über Menschenrechtsverletzungen in China?
P.S: Letzten Freitag wurde Theseus auf der Veranstaltung „Wag the long tail“ des Verbandes der deutschen Internetwirtschaft e.V Theseus „erstmals der Öffentlichkeit vorgestellt“. Die dazugehörige Pressemitteilung wurde an verschiedener Stelle (u.A. heise) rezipiert – was die viertelstündige (sic!) Vorstellung durch Stefan Wess (Geschäftsführer der Bertelsmann-Tochter Empolis) enthielt, erfährt die Öffentlichkeit aber nicht. Bei Linuxworld schreibt schreibt dazu John Blau, der anscheinend dabei war.
Förderpreis für Suchmaschinen
26. Juli 2007 um 11:40 Keine KommentareDer Gemeinnützige Verein zur Förderung der Suchmaschinen-Technologie und
des freien Wissenszugangs (SuMa e.V.) schreibt mit dem SuMa Awards 2008 einen Förderpreise für Suchmaschinen aus. Für seine Bemühungen Alternativen zu Google aufzuzeigen und umzusetzen musste Herr Sander-Beuermann schon einige Häme einstecken – jetzt können die Kritiker also beweisen, dass sie es besser können.
Nach den bisherigen Informationen beschränkt sich der Wettbewerb nicht nur auf technische Realisierungen – auch wirtschaftliche und künstlerische Auseinandersetzungen sind gefragt. Mich würde beispielsweise interessieren, was an Semantic Web und Suchagenten wirklich dran ist und wie personalisierte Suchdienste das Suchverhalten verändern – werden wir ohne Internet bald an digitalem Alzheimer leiden? Am Wettbewerb kann also jeder vom Studenten bis zur Forschungsgruppen teilnehmen.
Unter SuMa-Lab.de zeigt der Verein einige existierende Projekte, daneben ist sicherlich A9 einen Blick wert. Eine Suchmaschine muss auch nicht von Grund auf neu programmiert werden, sondern kann mit etablierten Techniken (OpenSearch, SRU, OAI, RSS etc.) vielleicht sogar einfach zusammengeklickt werden – ob kleine Lösungen wie Planet Biblioblog den Hauptpreis bekommen, weiß ich nicht aber mit vielen solcher kleinen Lösungen („Webservices“) ist sicherlich mehr zu erreichen als mit dem Versuch eines dicken Google-Clons. Vergleichbare Wettbewerbe (allerdings mehr technik-zentriert) gab es übrigens schon bei Talis (Mashing Up The Library competition) und bei OCLC (OCLC Research Software Contest).
Streit um Theseus: wohin mit 120 Millionen?
20. Juli 2007 um 15:36 2 KommentareWie am 19.7 mittgeilt wurde ist das EU-Suchmaschinen-Großprojekt Theseus bewilligt worden. Der Gemeinnützige Verein zur Förderung der Suchmaschinen-Technologie und des freien Wissenszugangs e.V. (SuMa-eV) regt sich darüber auf (siehe Pressemitteilung), allerdings dummerweise aus den falschen Gründen.
Es ist nämlich viel eher beklagenswert, dass ohne verbindliche Vorgaben 120 Millionen Euro der Großindustrie (Empolis GmbH, der SAP AG, der Siemens AG und der Deutsche Thompson oHG) in den Rachen geworfen werden, die dafür bunte Luftblasen („Web 3.0“) erzeugt und große Versprechungen à la Transrapid und Mautsystem gemacht werden. Die Panikmache des Suma e.V. kann ich allerdings nicht ganz nachvollziehen. Dass auf „Semantische Technologien“ statt auf eine Google-Kopie gesetzt wird, ist nämlich der richtige Weg – nur muss dieses Buzzword in der Praxis auch richtig ausgefüllt werden, was ich bei der vorliegenden Ausgangslage stark bezweifle.
Die 120 Millionen wären viel besser angelegt, wenn damit zu einem Teil bereits bestehende OpenSource-Initiativen im Suchmaschinen- und Semantic-Web-Bereich unterstützt werden und mit dem Rest digitalisiert und annotiert wird (sei es in Wikipedia, LibraryThing & Co oder durch Bibliotheken und Digitalisierungseinrichtungen). Eine interessante Anwendung der „semantischen Technologien“ wäre es übrigens mal all die beteiligten Projektpartner, Firmen und Personen mit ihren Geschäftsbeteiligungen und Verstrickungen transparent zu erschließen, um zu erfahren, wer hier wem in die Tasche wirtschaftet.
Nachtrag: in der Englischsprachigen Blogosphäre gibt es bereits über ein Dutzend Beiträge zu Theseus. Besonders gefallen hat mir Galileo of the internet, der auch noch die besondere Europäische Komponente dieser Geldverschwendung darlegt:
But nothing symbolises the divide between old Europe and the New World. Whereas Google is a testament to the power of free enterprise, set up by Larry Page and Sergey Brin, then PhD students at Stanford University, the European version is a multi-million project, heavily subsidised by the German and French governments, and developed by some of the largest corporate giants in Europe.
Von G8, Ляпис Трубецкой und Krosslingualer Suche
7. Juni 2007 um 01:46 2 KommentareEine der ebenso schönen wie gefährlichen Eigenschaften des Netzes ist es, Dinge kennenlernen zu können, denen man anderweitig wohl nur durch ferne Reisen begegnet wäre – beispielsweise Heiligendamm oder Minsk. Nun habe ich einen Ohrwurm von der weißrussische Band Ляпис Трубецкой (Lyapis Trubetskoj), deren neue Single Капитал (Kapital) schon seit März in den Russischen TOP 100 läuft. Dazu gibt es ein sehr schönes Video, auf das ganz am Rande Neuraum in einem intelligenten Kommentar zu den G8-Protesten bei Spreeblick (aktuelle Berichterstattung unter Spree8) hingewiesen hat. Er zitiert den Refrain:
In der linken Hand “Snickers”,
In der rechten Hand – “Mars”
Mein PR-Manager ist
Karl Marx
Eine grobe englische Übersetzung gibt es bei Belarusnews, das russische Original scheint das hier zu sein – ich sollte endlich mal kyrillische Buchstaben lernen. Kann jemand mit einer guten deutschen Übersetzung aushelfen? Nützlich war bei der kurzen Recherche die bei AgoraWissen beschriebene Google Cross Language Search.
P.S.: Und noch zwei nette Videos zu G8 bei YouTube (extra3 bzw. scheibenwischer).
Wikipedia-Verlinkung und Artikelstruktur als Mindmap
6. Juni 2007 um 12:22 Keine KommentareAls Such- und Navigationshilfe für Wikipedia wird momentan Wikimindmap in diversen Blogs angepriesen. Um sich einen ersten Überblick zu verschaffen, ist das Programm zur Darstellung der Wikipedia-Verlinkung und Artikelstruktur als Mindmap möglicherweise praktisch – so gut wie das leider nur für Mac verfügbare Pathway (siehe screenshot) ist es aber nicht und zum Suchen in Wikipedia sind Suchmaschinen wie Exalead, WikiSeek und Web.de besser geeignet. Noch besser lässt sich Wikipedia übrigens nutzen, indem man anstatt wild herumzuklicken und zu browsen, mal Artikel aufmerksam Satz für Satz liest, versucht die Aussagen vollständig zu verstehen und danach unklare, unvollständige oder unverständliche Stellen selber ergänzt, verbessert und/oder zusammenfasst. Da bleibt einiges mehr hängen als beim passiven Wikipedia-Genuss. [via Nordenham u.A.]
{kind=link}
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare