Weitere Nutzung von SeeAlso-Schnittstellen
10. Februar 2009 um 19:15 1 KommentarDass sich das SeeAlso-Protokoll im Rahmen der Kataloganreicherungen auch (wie bereits angedacht) für die Einbindung von Rezensionen eignet, hat Ende Januar Carsten Schulze demonstriert: Das geschichtswissenschaftliche Fachportal Clio-Online verwaltet eine Datenbank mit über 50.000 Rezensionen. Daniel Burckhardt hat für diese Datenbank eine OAI-Schnittstelle erstellt, über die die monatlich etwa 500 hinzukommenden Einträge geharvested werden können. Ein Skript von Carsten sammelt auf diese Weise die Rezensionen, extrahiert die ISBN der rezensierten Werke und ermöglicht die Abfrage über SeeAlso Simple (z.B. ISBN 3506775197).
„SeeAlso Simple“ bedeutet, dass die Schnittstelle auf eine Anfrage mit dem Parameter id lediglich die Daten im JSON-Format zurückliefert (was für den Einsatz ausreicht), während bei „SeeAlso Full“ mit dem Parameter format=opensearchdescription der Dienst eine Selbstbeschreibung liefert. Das XSLT-Skript, das aus der Selbstbeschreibung ein Test-Interfaceerzeugt, habe ich übrigens so aktualisiert, das die Ergebnisliste gleich in verschiedenen Anzeigestilen („display“) dargestellt werden kann – zum Ausprobieren sollte ein SeeAlso-Dienst verwendet werden, der mehrere Treffer liefert, zum Beispiel isbn2gbvlib (liefert GBV-Bibliotheken, die einen bestimmten per ISBN gegebenen Titel haben) oder diese Anfrage.
Weiterer Nutzer von SeeAlso sind seit Kurzem die Hannover-Bibliotheken, in deren Katalogen nun auch ein Link auf Wikipedia sowie Coverbilder angezeigt werden (die Coverbilder kommen übrigens nur teilweise von LibraryThing). Ob ein Verweis auf Wikipedia sinnvoll ist, wird ja immer wieder angezweifelt – mit SeeAlso kann jede Bibliothek (HTML-Kenntnisse und Gestaltungsmacht über die eigene OPAC-Oberfläche vorrausgesetzt) selber entscheiden, was sie an welcher Stelle zur Anreicherung in ihren Katalog einbindet und was nicht.
P.S: ISBN2GBVLib funktioniert inzwischen wieder.
Link Resolver und Widgets im OPAC
26. November 2008 um 13:05 Keine KommentareJonathan Rochkind hat in seinem Blog SeeAlso und Umlaut verglichen, die beide eine Form von Link Resolver darstellen. Während über SeeAlso ausgehend von einer ID (ISBN, ISSN, DOI, PPN, …) eine Liste von passenden Einträgen mit Links zurückgeliefert wird, liefert Umlaut ausgehend von einer OpenURL auch leicht komplexere Inhalte, wie zum Beispiel ein Formular, mit dem in verschiedenen Quellen im Volltext eines Buches gesucht werden kann. Die Abfrage geschieht jedoch leider nicht über eine standardisierte API sondern proprietär (d.h. nur Umlaut kann lesen was Umlaut liefert).

Nach meiner Auffassung ist Umlaut (wie Link Resolver im Allgemeinen) eine spezielle Form einer Metasuche. Über eine OpenURL-Anfrage können mehrere Dienste und Quellen (SFX, CrossRef, Amazon, OCLC Worldcat, ISBNdb, LibraryThing, Google Books, HathiTrust, OpenLibrary, the Internet Archive, Worldcat Identities …) gemeinsam abgefragt werden und die Ergebnisse werden auf einer Seite zusammengefasst (siehe Beispiel). Das Zusammenfassen von Inhalten aus mehreren Quellen kann allerdings auch im OPAC bei einer Titelanzeige geschehen (siehe Beispiel).
Allgemein ist für die Zusammenfassung von Inhalten aus unterschiedlichen Quellen (Mashup-Prinzip) hilfreich, wenn auf einheitliche APIs und Datenformate zurückgegriffen wird. Das populärste Beispiel ist RSS (bzw. ATOM). SeeAlso kann als API und Format für einfachere Listen dienen und für komplexere Inhalte käme vielleicht die Universal Widget API (UWA) in Frage. UWA-Widgets können auch in eigene Seiten eingebunden werden. Einen OPAC als Widget gibt es ja schon – wie wäre es umgekehrt einen OPAC aus Widgets zusammenzusetzen? Ich denke, dass es noch einige Zeit dauern wird, bis sich neben ATOM/RSS weitere gute Standards für die Aggregierung von Inhalten auf Webseiten durchsetzen. Praktische Beispiele gibt es ja inzwischen immer mehr, gerade hat Lorcan Dempsey einige davon zusammengefasst.
Ariadne article about SeeAlso linkserver protocol
13. November 2008 um 11:32 Keine Kommentare The current issue of Ariadne which has just been published contains an article about the „SeeAlso“ linkserver protocol: Jakob Voß: „SeeAlso: A Simple Linkserver Protocol„, Ariadne Issue 57, 2008.
The current issue of Ariadne which has just been published contains an article about the „SeeAlso“ linkserver protocol: Jakob Voß: „SeeAlso: A Simple Linkserver Protocol„, Ariadne Issue 57, 2008.
SeeAlso combines OpenSearch and unAPI to a simple API that delivers list of links. You can use it for dynamically embedding links to recommendations, reviews, current availability, reviews, search completion suggestions, etc. It’s no rocket science but I found a well defined API with reusable server and client better then having to hack a special format and lookup syntax for each single purpose.
The reference client is written in JavaScript and the reference server is written in Perl. Implementing it in any other language should not be complicated. I’d be happy to get some feedback either in form of code, applications, or criticism. 🙂 I noted that SeeAlso::Server is the only implementation of unAPI at CPAN so far – if someone is interested, we could extract parts into an independent unAPI package. The WWW::OpenSearch::Description package is also worth to consider for use in SeeAlso::Server.
Working group on digital library APIs and possible outcomes
13. April 2008 um 14:48 3 KommentareLast year the Digital Library Federation (DLF) formed the „ILS Discovery Interface Task Force„, a working group on APIs for digital libraries. See their agenda and the current draft recommendation (February, 15th) for details [via Panlibus]. I’d like to shortly comment on the essential functions they agreed on at a meeting with major library system (ILS) vendors. Peter Murray summarized the functions as „automated interfaces for offloading records from the ILS, a mechanism for determining the availability of an item, and a scheme for creating persistent links to records.“
On the one hand I welcome if vendors try to agree on (open) standards and service oriented architecture. On the other hand the working group is yet another top-down effort to discuss things that just have to be implemented based on existing Internet standards.
1. Harvesting: In the library world this is mainly done via OAI-PMH. I’d also consider RSS and Atom. To fetch single records, there is unAPI – which the DLF group does not mention. There is no need for any other harvesting API – missing features (if any) should be integrated into extensions and/or next versions of OAI-PMH and ATOM instead of inventing something new. P.S: Google Wave shows what to expect in the next years.
2. Search: There is still good old overblown Z39.50. The near future is (slightly overblown) SRU/SRW and (simple) OpenSearch. There is no need for discussion but for open implementations of SRU (I am still waiting for a full client implementation in Perl). I suppose that next generation search interfaces will be based on SPARQL or other RDF-stuff.
2. Availability: The announcement says: „This functionality will be implemented through a simple REST interface to be specified by the ILS-DI task group“. Yes, there is definitely a need (in december I wrote about such an API in German). However the main point is not the API but to define what „availability“ means. Please focus on this. P.S: DAIA is now available.
3. Linking: For „Linking in a stable manner to any item in an OPAC in a way that allows services to be invoked on it“ (announcement) there is no need to create new APIs. Add and propagate clean URIs for your items and point to your APIs via autodiscovery (HTML link element). That’s all. Really. To query and distribute general links for a given identifier, I created the SeeAlso API which is used more and more in our libraries.
Furthermore the draft contains a section on „Patron functionality“ which is going to be based on NCIP and SIP2. Both are dead ends in my point of view. You should better look at projects outside the library world and try to define schemas/ontologies for patrons and patron data (hint: patrons are also called „customer“ and „user“). Again: the API itself is not underdefined – it’s the data which we need to agree on.
Linkserver auch beim BSZ
14. Februar 2008 um 00:20 1 KommentarIch muss zugeben, dass ich den Verbundkatalog des Südwestdeutschen Bibliotheksverbundes (SWB) nur sehr selten nutze und auch nur ganz zufällig darauf gestoßen bin – jedenfalls ist mir gerade aufgefallen, dass das BSZ (die Zentrale des SWB) ebenfalls einen Linkserver für seine Kataloge anbietet. Die Eigenentwicklung des BSZ wird folgendermaßen beschrieben:
Anreicherung des Katalogs mit Internet-Ressourcen:
Die Einzeltrefferanzeige im Web-Katalog kann ergänzt werden durch die Einblendung von dynamisch erzeugten Links zum Buchhandel (z.Zt. amazon, lehmanns, kno-k&v, libri, abebooks, booklooker, zvab). Soweit dort vorhanden werden das Cover und ein direkter Link zum Medium (i.e. der ISBN) angezeigt. Der Link-Server läuft zentral im BSZ

Im Verbundkatalog werden die Links mit dem Button „Verfügbarkeit im Buchhandel prüfen“ eingeblendet, wie zum Beispiel bei diesem guten Buch ausprobiert werden kann (siehe nebenstehendes Bild). Die Einbindung geschieht zwar nicht über eine sauber definierte Schnittstellen sondern als proprietärer HTML-Batzen, aber prinzipiell sehe ich kein Hindernis, den Service auf SeeAlso umzustellen, so dass verschiedene Linkserver einfacher gemeinsam in unterschiedliche Anwendungen eingebunden werden können. Ich habe mir erstmal verkniffen, zur Demonstration einen vollständigen SeeAlso-Proxy zu schreiben zumal dazu ein kleiner Trick notwendig wäre (stattdessen gibt es einen experimentellen Proxy für Google Buchsuche). Das Prinzip ist jedenfalls das selbe wie bei den Linkservern der VZG des GBV. Ein spontanes Lob an die Kollegen im Süden!
P.S: Der Linkserver des BSZ nimmt wie isbn2wikipedia auch ISBNs und liefert (in zusätzlichem HTML) eingebettete Links – ich hoffe das führt nicht zur irrigen Annahme, dass Linkserver nur mit ISBNs funktionieren!
P.P.S: Ich höre schon (wie bei Wikipedia) den Aufschrei der Entrüstung, aber muss es mal deutlich sagen: Google Buchsuche ist sehr nützlich und ein Link darauf fast immer ein Mehrwert. So habe ich im konkreten Fall zwar keinen Volltext aber wie gesucht Rezensionen gefunden (die FAZ-Kritik von Martin Lhotzky ist übrigens Bullshit) – Bibliotheken müssten für sowas wahrscheinlich erstmal Analysen und Regelwerke erstellen, was eine Rezension sei und wer wie wann bestimmen darf, was wie wo genau als zusätzlicher Link eingetragen wird – anstatt den Nutzer einfach selber entscheiden zu lassen.
thingISBN is getting better – so does SeeAlso
17. Januar 2008 um 00:05 Keine KommentareTim Spalding points out that thingISBN is getting better [via FRBR blog] – a good reason to update the thingISBN data of our SeeAlso Linkserver isbn2librarything. It now includes 2994299 ISBNs, that’s almost 12 times the size of the isbn2wikipedia linkserver. But what’s a linkserver? A linkserver is a server that gets an identifier (for instance an ISBN) and gives you links (for instance a link to a work at LibraryThing). You can try out some SeeAlso linkservers at a demo page or start to implement your own.
To get an impression, look in GBV union catalog, for instance this record: after a short moment, a link to German Wikipedia is included. More and more German libraries follow to include such additional links in their catalog. The Catalog of University Bremen includes both links to (German) Wikipedia and links to LibraryThing (you have to click at „weitere Informationen…“ at a selected record):

There is also an experimental ISBN2WorldCat linkserver. But linkservers that only send one or zero links are not very effective. I could combine multiple service to something like ISBN2SocialCataloging or such. Any suggestions for other services that libraries might not be frightened to link to? I’d also like to include more data in the link to LibraryThing (for instance the number of reviews) but unless German libraries wake up to ask for LibraryThing for Libraries I better not reimplement services that LibraryThing already offers.
The linkserver model could also be used to provide links to library holding and thus implement a FRBR-Manifestation to FRBR-Item mapping. As I just wrote at CODE4LIB and PER4LIB, a simple data format for holding information is needed to do so.
First Draft of SeeAlso Simple linkserver API
14. Januar 2008 um 23:45 2 KommentareI finally finished the first draft of the SeeAlso Simple Specification  . The webservice API for simple linkservers is based on OpenSearch Suggestions. It will be completed by the „SeeAlso Full Specification“ which adds unAPI and OpenSearch Description documents. The service is already implemented and running at the Union Catalog of GBV, see my earlier posting or simply have a look at this example. The same service is installed for testing at the Wikimedia Toolserver. For Wikipedia I drafted a different client that can be tested via a Bookmarklet: Drag the Link „ISBN2W“ to you bookmark toolbar, visit an English or German Wikipedia article with ISBNs on it, click the Bookmarklet link in your toolbar and hover the the ISBNs (that will become yellow) with the mouse. German Wikipedia users can also enable the service by adding a line of JavaScript to their user profile.
. The webservice API for simple linkservers is based on OpenSearch Suggestions. It will be completed by the „SeeAlso Full Specification“ which adds unAPI and OpenSearch Description documents. The service is already implemented and running at the Union Catalog of GBV, see my earlier posting or simply have a look at this example. The same service is installed for testing at the Wikimedia Toolserver. For Wikipedia I drafted a different client that can be tested via a Bookmarklet: Drag the Link „ISBN2W“ to you bookmark toolbar, visit an English or German Wikipedia article with ISBNs on it, click the Bookmarklet link in your toolbar and hover the the ISBNs (that will become yellow) with the mouse. German Wikipedia users can also enable the service by adding a line of JavaScript to their user profile.
An implementation (SeeAlso Simple and SeeAlso Full) in Perl is available at CPAN (there was neither unAPI nor OpenSearch Suggestions, so I implemented both). Please note that ISBN to Wikipedia is only one example how the API can be used. In my opinion the concept of a linkserver is highly undervalued but will become more important again (for instance as a lightweigth alternative to simple SPARQL queries). Feedback and usage is welcome!
Heidelberger Katalog auf dem Weg zu Serviceorientierter Architektur
23. Dezember 2007 um 20:59 4 KommentareDie zunehmende Trennung von Bibliotheksdaten und ihrer Präsentation zeigt „HEIDI“, der Katalog der Unibibliothek Heidelberg. Vieles, was moderne Bibliothekskataloge bieten sollten, wie eine ansprechende Oberfläche, Einschränkung der Treffermenge per Drilldown, Permalinks, Exportmöglichkeit (u.A. direkt nach BibSonomy), RSS-Feeds und nicht zuletzt eine aktuelle Hilfe für Benutzer ist hier – zwar nicht immer perfekt, aber auf jeden Fall vorbildhaft – umgesetzt. Soweit ich es von Außen beurteilen kann, baut der Katalog auf zentralen Daten des Südwestdeutschen Bibliotheksverbundes (SWB) und lokalen Daten des lokalen Bibliothekssystems auf. Zum Vergleich hier ein Titel in HEIDI und der selbe Titel im SWB-Verbundkatalog. Aus dem Lokalsystem werden die Titeldaten mit Bestands- und Verfügbarkeitsdaten der einzelnen Exemplare angereichter, also Signatur, Medien/Inventarnummer, Standort, Status etc.:

Die tabellarische Ansicht diese Daten erinnert mich an WorldCat local, das sich zu WorldCat teilweise so verhält wie ein Bibliotheks-OPAC zu einem Verbundsystem. Hier ein Beispieldatensatz bei den University of Washington Libraries (und der gleiche Datensatz in WorldCat). Die Exemplardaten werden aus dem lokalen Bibliothekssystem als HTML-Haufen per JavaScript nachgeladen, das sieht dann so aus:

Bei HEIDI findet die Integration von Titel- und Exemplardaten serverseitig statt, dafür macht der Katalog an anderer Stelle rege von JavaScript Gebrauch. In beiden Fällen wird eine proprietäres Verfahren genutzt, um ausgehend von einem Titel im Katalog, die aktuellen Exemplardaten und Ausleihstati zu erhalten. Idealerweise sollte dafür ein einheitliches, offenes und webbasiertes Verfahren, d.h. ein RDF-, XML-, Micro- o.Ä. -format und eine Webschnittstelle existieren, so dass es für den Katalog praktisch egal ist, welches lokale Ausleih- und Bestandssystem im Hintergrund vorhanden ist. Die Suchoberfläche greift damit als als ein unabhängiger Dienst auf Katalog und Ausleihsystem zu, die ihrerseits eigene unabhängige Dienste mit klar definierten, einfachen Schnittstellen bereitstellen. Man spricht bei solch einem Design auch von „Serviceorientierter Architektur“ (SOA), siehe dazu der Vortrag auf dem letzten Sun-Summit. Eigentlich hätte beispielsweise die IFLA sich längst um einen Standard für Exemplardaten samt Referenz-implementation kümmern sollen, aber bei FRBR hat sie es ja auch nicht geschafft, eine RDF-Implementierung auf die Beine zu stellen; ich denke deshalb, es wird eher etwas aus der Praxis kommen, zum Beispiel im Rahmen von Beluga. Der Heidelberger Katalog setzt SOA noch nicht ganz um, geht allerdings schon in die richtige Richtung. Beispielweise wird parallel im Digitalisierten Zettelkatalog DigiKat gesucht und ggf. ein Hinweis auf mögliche Treffer eingeblendet. Wenn dafür ein offener Standard (zum Beispiel OpenSearch oder SRU) verwendet würde, könnten erstens andere Kataloge ebenso dynamisch zum DigiKat verweisen und zweitens in fünf Minuten andere Kataloge neben dem DigiKat hinzugefügt werden.
Ein weiteres Feature von HEIDI sind die Personeneinträge, von denen auf die deutschsprachige Wikipedia verwiesen wird – hier ein Beispiel und der entsprechende Datensatz im SWB. Die Verlinkung auf Wikipedia geschieht unter Anderem mit Hilfe der Personendaten und wurde von meinem Wikipedia-Kollegen „Kolossos“ erdacht und umgesetzt. Über einen statischen Link wird eine Suche durch einen Webservice angestossen, der mit Hilfe der PND und des Namens einen passenden biografischen Wikipedia-Artikel sucht. Ich könnte den Webservice so erweitern, dass er die SeeAlso-API verwendet (siehe Ankündigung), so dass Links auf Wikipedia auch nur dann angeboten werden, wenn ein passender Artikel vorhanden ist. Für einen verlässlichen und nachhaltigen Dienst ist es dazu jedoch notwendig, dass der SWB seine Personenangaben und -Normdaten mit der PND zusammenbringt. Natürlich könnte auch nach Namen gesucht werden aber warum dann nicht gleich den Namen einmal in der PND suchen und dann die PND-Nummer im Titel-Datensatz abspeichern? Hilfreich wäre dazu ein Webservice, der bei Übergabe eines Namens passende PND-Nummern liefert. Die Fälle, in denen eine automatische Zuordnung nicht möglich ist, können ja semiautomatisch gelöst werden, so wie es seit über zwei Jahren der Wikipedianer APPER mit den Personendaten vormacht. Hilfreich für die Umsetzung wäre es, wenn die Deutsche Nationalbibliothek URIs für ihre Normdaten vergibt und ihre Daten besser im Netz verfügbar macht, zum Beispiel in Form einer Download-Möglichkeit der gesamten PND.
P.S.: Hier ist testweise die PND-Suche in Wikipedia als SeeAlso-Service umgesetzt, zum Ausprobieren kann dieser Client verwendet werden, einfach bei „Identifier“ eine PND eingeben (z.B. „124448615“).
Linking to Wikipedia via ISBN
5. Dezember 2007 um 19:52 2 KommentareTwo weeks ago I announced a new beta webservice for linking from title data to German Wikipedia articles that cite a given work by ISBN. Now Lambert pointed me to a message by Eric Hellmann about xISBN supporting links to the English Wikipedia since last week. This makes GBV one week earlier then OCLC and both of us ten month later then LibraryThing. The idea is not new but based on the work of Lars Aronsson, Spiritus rector of future library systems.
The three services have been developed partly parallel based on some same code. Here are two examples of the xISBN service by Xiaoming Liu and the GBV service that I am developing. xISBN is based on a powerfull API with many query parameters and planned to be part of WorldCat Grid Services (more about this maybe here, here, here, and here), while my service is based on a simple API called SeeAlso which is based on OpenSearch Suggestions and unAPI. Both approaches have their pros and cons. I will provide more information as soon as our server is more stable and the scripts are clean enough to get published at CPAN. Meanwhile I encourage everyone to play with OCLC’s xISBN (via an API of its own), WorldCat Idenities (via SRU), LibraryThing for Libraries (via an API of its own), available catalouges (via Z39.50, via SRU and via other APIs), the Wikipedia Query API, and the growing number of other services. Let’s mash up the library systems for the future!
Verweise auf passende Rezensionen
5. Dezember 2007 um 16:35 4 KommentareNachdem ich in einer Fortbildung (siehe slides) am Rande die Realisierung von Links auf Wikipedia mittels des SeeAlso-Protokolls vorgestellt habe, kam von einer Teilnehmerin die Idee, auf die selbe Weise auf Rezensionen zu verweisen. Neben Amazon (wo Rezensionen manipuliert werden) und LibraryThing gibt es eine Vielzahl von Rezensionsdiensten von Fachreferenten und Wissenschaftlern. Leider bekommt dies außerhalb enger Fachcommunities kein Schwein mit, da Rezensionen weder systematisch erschlossen werden, noch praktikabel recherchierbar sind – dies gilt anscheinend auch für Rezensionen in Zeitungen, z.B. bei der ZEIT. Die Idee, über einen Linkserver Verweise auf passende Rezensionen zu liefern, finde ich wunderbar, weshalb ich gleich mal ein Konzept erstellt habe. Hier nur das Diagram, ausführlich im GBV-Wiki:
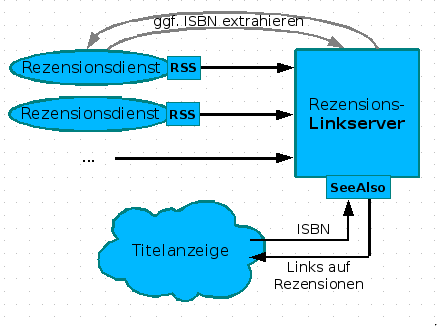
Leider hinken die meisten Rezensionsdienste dem Stand der Technik hinterher und bieten keine (oder kaputte) Feeds an. Wollen die nicht gelesen werden? Nun ja, vielleicht wachen Sie noch auf. Kennt jemand weitere Rezensionsdienste mit benutzbaren Feeds? So lange nicht genügend Rezensionsdienste verfügbar sind, ist der skizzierte Linkserver den Aufwand nicht wert, aber das kann ja noch kommen. Bitte mehr solcher Ideen! Wer nicht weiß, was Feeds sind und sich nicht vorstellen kann, wie ein Linkserver funktioniert, oder den Unterschied zwischen Indexbasierter und Metasuchmaschine nicht einigermaßen verinnerlicht hat, wird auch nicht auf die Ideen kommen, die notwendig sind, damit Bibliotheken nicht in der Bedeutungslosigkeit verschwinden. Deshalb sind Fortbildung und genügend freie Zeit zum Experimentieren so wichtig – zum Beispiel mit diesen Web 2.0-Diensten!
P.S: Neben Rezensionen und Lins auf Wikipedia können auch andere Informationen zu einem Werk von Interesse sein, z.B. Zusammenfassungen, Erwähnungen in Blogs etc.
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare