Konkurrenz zu Normdaten mit dem Scopus Affiliation Identifier
30. April 2008 um 09:34 2 KommentareWie medinfo berichtet (Details dort) hat Scopus nach dem Author identifier nun den Scopus Affiliation Identifier eingeführt. Damit baut Scopus praktisch eine eigene Normdatei für Körperschaftenh auf. In Deutschland ist dafür bislang die Gemeinsame Körperschaftsdatei (GKD) verbreitet, weitere Systeme existieren in anderen Ländern.
Ich sehe die Entwicklung von Normdaten ähnlich wie Patrick Danowski, der in seiten Vorträgen (The future importance of bibliographic data Sharing and control in Web 2.0, Sharing and control) auf die Bedeutung von freien Normdaten hingewiesen hat: Wenn Bibliotheken nicht endlich ihre Normdaten aktiv und kompetent für die Nutzung im Web anbieten, machen es andere und die bibliothekarischen Normdaten versinken in der Bedeutungslosigkeit. Das Zeitfenster, in dem andere Akteure dazu gebracht werden können, die bibliothekarischen Normdaten weiterzunutzen, schließt sich langsam – wenn es zu spät ist, werden Bibliotheken den anderen herlaufen müssen anstatt umgekehrt. Das Potential für Bibliotheken, sich als relevanter Bestandteil des (Semantic) Web zu positionieren ist mit den bestehenden Normdaten da. Leider aber ist die Situation zu oft – wie beispielsweise neulich an der DNB – so, dass eine gute Idee in ihrer (technischen und organisatorischen) Umsetzung dem Stand der Entwicklung hinterherhinkt und langsam so sehr verkrustet, dass es irgendwann eben andere besser machen – und Bibliotheken damit stückweise überflüssig werden. 🙁
Umfrage und Studie zu Bibliothekssystemen
29. April 2008 um 10:47 6 KommentareDie Ergebnisse einer 2007 durchgeführten internationalen Umfrage zu Bibliothekssystemen (ILS) sind seit Januar verfügbar. Marshall Breeding hat die Umfrage durchgeführt und stellt mehrere Statistiken bereit (ansonsten schreibt Breeding an verschiedenen Stellen zur „New Generation of Library Interfaces„). Die in Deutschland verwendeten Bibliothekssysteme sucht man vergeblich: PICA LBS: 1 Antwort, LIBERO: 3 Antworten, Allegro: 0 Antworten, SISIS-SunRise: 0 Antworten. Angesichts der niedrigen Beteiligung aus Deutschland ist das aber auch nicht verwunderlich: von 1783 Antworten kamen genausoviele von Deutschen Bibliotheken, wie beispielsweise aus Malaysia, Libanon oder Singapur: nämlich 2. Es sei aber bemerkt, dass auch aus den im Vergleich zu Deutschland hinsichtlich ihrer Bibliothekssysteme aktiveren Niederlanden nur 5 Antworten kommen, die Masse ist aus dem Englischsprachigen Raum.
Ein wenig seltsam finde ich das schon, was ist die Schlussfolgerung? Deutsche Bibliotheken interessieren sich nicht für ihre Bibliothekssysteme? Deutsche Bibliotheken nehmen nicht an internationalen Umfragen teil? Die in Deutschland verwendeten Bibliothekssysteme sind sowieso hoffnungslos irrelevant? Was Softwaremäßig außerhalb des deutschen Bibliothekstellerands geschieht interessiert nicht? Umfragen werden überbewertet? …
Auf eine weitere Studie weist Lorcan Dempsey hin: „Library Management Systems Study: An Evaluation and horizon scan of the current library management systems and related systems landscape for UK higher education“ (PDF). Die Studie enthält einige sehr bemerkenswerten allgemeinen Aussagen („Key trends“) über die Entwicklung von Bibliothekssystemen: Standards, Web Services, Konsortien, Open Source, Open Data, Entkoppelte Systeme (Serviceorientierte Architektur). Es lohnt sich also auch hier mal reinzuschauen (wenn man sich für die Zukunft von Bibliothekssystemen interessiert). [via Web4lib].
BibSonomy und Kataloge verknüpfen mit dem Bibkey
25. April 2008 um 15:46 2 KommentareAnknüpfend an einen Workshop zum Thema „Social Tagging in Bibliotheken“ und an Gespräche auf der INETBIB 2008 gab es Überlegungen, Bibliothekskataloge mit der webbasierten Literaturverwaltung BibSonomy zu verknüpfen (siehe auch die Diplomarbeit von Annett Kerschis auf die Patrick hingewiesen hat).
Zum einen sollen Nutzer Einträge aus dem Katalog direkt in BibSonomy abspeichern können (wie bereits der KUG und HEIDI anbieten) – der einfachste Weg dazu ist ein BibTeX-Export. Zum anderen soll per Webservice BibSonomy abgefragt werden, ob und mit welchen Tags dort bereits ein Titel von Nutzern gespeichert wurde. Ein grundsätzliches Problem dabei ist jedoch, erst einmal den Titel zu identifizieren, nach dem gesucht werden soll. Die dahinter liegende Aufgabenstellung ist ein klassisches (nicht nur) Bibliothekswissenschaftliches Forschungsfeld: Duplikaterkennung in bibliographischen Datenbanken. BibSonomy ist dabei auf eine ähnliche Lösung gekommen, wie sie teilweise in Katalogen angewandt wird: Aus verschiedenen Feldern (Titel, Autor, Jahr…) wird durch Normalisierung und mittels einer Hashfunktion eine Zeichenkette als Identifikator („Hashkey“) gebildet. Dubletten sollen dabei möglichst auf den gleiche Hashkey abgebildet werden. Der übergreifende Hashkey von BibSonomy heisst dort „Interhash“.
Ich bin momentan dabei, diesen Hashkey zu spezifizieren (Unter dem Namen „Bibkey Level 1“) und zu implementieren – der Bibkey kann hier ausprobiert werden. In diesem Beispiel wird der Titel über die ISBN aus den GBV-Verbundkatalog geholt und aus den Daten der Bibkey gebildet (serverseitig, Link „Go to record in GSO“). Mit dem Bibkey wird dann über eine weitere API von BibSonomy (die ich als „SeeAlso“-verpackt habe) abgefragt ob den Titel schon jemand in seiner Sammlung hat (clientseitig, Link „Available in BibSonomy“).
Wie alle Heuristiken funktionier der Bibkey in seiner jetzigen Form nicht in jedem Fall. In diesem Beispiel wird bei BibSonomy nichts gefunden, weil die meisten Nutzer „Albert-László Barabási“ Nicht richtig buchstabieren können. Auch verschiedene Auflagen kommen aufgrund unterschiedlicher Jahreszahl nicht zusammen. Es ist also noch genügend Forschungs- und Entwicklungsbedarf. Auch für den Einsatz von FRBR wird über Hashkeys nachgedacht, wie dieser Vortrag von Rosemie Callewaert auf der ELAG2008 zeigt.
Weitere Literatur zum Thema „Hashkeyverfahren zur Duplikaterkennung in bibliographischen Daten“ sammle ich dank hilfreicher Hinweise mit dem Tag „bibkey“ – falls jemand seine Bachelor/Master-Arbeit dazu machen möchte, helfe ich gerne! 🙂
Vorbildliches OPAC-Widget von der Jacobs University
23. April 2008 um 15:03 1 KommentarKollege John_Paul weist hier im Kommentar und auf den Seiten der Jacobs University auf das gelungene Katalog-Widget jOPAC hin. Der Meinung von Christan Hauschke, dass das Widget „im deutschsprachigen Raum wirklich Maßstäbe setzt“ kann ich mich anschließen. Das Widget ist mit Hilfe von Netvibes Universal Widget API (UWA) programmiert und damit unter verschiedenen Widget-Engines (iGoogle, Netvibes, Windows Vista Sidebar, Apple Dashboard, Windows XP Yahoo Sidebar …) lauffähig. Ein Serverausfall bei Netvibes heute vormittag zeigte allerdings auch ein Manko vieler Mashups: Die Dienste fallen ab und zu mal aus. Wenn der UWA Quellcode von Netvibes auf einen eigenen Server kopiert wird, sollte eine Fehlerquelle minimiert sein. Auf den OPAC der Bibliothek der Jacobs University greift das Widget über einen eigenen Webservice zu, der wiederum per Z39.50 mit dem OPAC kommuniziert – es sollte also nicht sehr aufwändig sein, solch ein Widget auch für andere Bibliotheken anzubieten. Im Detail müsste man sich allerdings anschauen, welche Daten in welchem Format genau über Z39.50 abgefragt werden, da verwendet ja leider gerne jede(s/r) Bibliothek(ssystem/sverbund) seine eigenen Standards.
P.S: Nein, ich habe nichts mit der „Jacobs University“ zu tun, mein Name wird mit „k“ geschrieben 😉
Frickelbangen mit dem Panzerballett
23. April 2008 um 01:33 Keine KommentareÜber „Kulturzeit“ bin ich Ende März auf die außergewöhnliche Jazz-Metal-Band Panzerballett gestoßen, die ich hiermit weiterempfehlen möchte – Hörbeispiele gibt es auf ihrer myspace-Seite. Die Mischung aus Metal, Jazz und Humor ist … ich sag mal „schon geil“, wenn auch sicherlich nicht jedermanns Sache. Im Norddeutschen Raum spielen die Bayern erst wieder Mitte August zur Zappanale (Festivalseite), da könnte man ja sowieso mal hinfahren. P.S: Ha, noch keine Google-Hits zum Thema „Frickelbangen“ bisher 🙂
Mathematische Weblogs, vom Fachreferenten erklärt
20. April 2008 um 13:24 1 KommentarHeft 1, Band 16 (2008) der Mitteilungen der DMV (Deutsche Mathematikervereinigung), die schon durch den regelmäßigen Jamiri-Comic positiv auffällt, enthält auf Seite 8-10 den Artikel „Weblogs – ein neues Medium für die Mathematik?“ von Katharina Habermann, Fachreferentin für Mathematik und Informatik an der SUB Göttingen. Eine Sammlung interessanter Matheblogs stellt sie bei del.icio.us zusammen und ihr Weblog ist auch sehr interessant (nur anscheinend leider nicht ausreichend in das offizielle Angebot der SUB und in die Virtuelle Fachbibliothek Mathematik eingebunden?). Wem als Fachreferent noch immer nicht ganz klar ist, was der ganze Web 2.0-Krempel soll und was Weblogs, Social Bookmarking & Co mit ihrer eigenen Arbeit zu tun haben, sollte sich den Artikel, Linksammlung und Weblogs mal ansehen – sicherlich lässt sich das auch auf andere Fächer übertragen.
Dynamische Kataloganreicherung mit Webservices
16. April 2008 um 17:36 3 KommentareDie Folien des Vortrags „Dynamische Kataloganreicherung mit Webservices“ am 15.4.2008 Berliner Bibliothekswissenschaftlichem Kolloquium (BBK) sind jetzt online bei Slideshare. In der aktuellen letzten iX (04/2008) gibt es einen Artikel zu Webschnittstellen, die dort erwähnten Sechs Wahrheiten über Freie APIs hätte ich auch noch aufnehmen sollen (auf die Nachteile von Webservices bin ich im Vortrag nicht eingegangen).
Eine Gute Übersicht von Webanwendungen, Widgets und Plugins, die Bibliotheken ihren Nutzern anbieten können, bietet die University of Texas Libraries, Austin. Vom Facebook-Widget bis zum Hinweis auf Zotero ist alles dabei und übersichtlich erklärt. Neue Widgets können direkt empfohlen werden und werden im Blog vorgestellt. Die Bibliothek ist unter Anderem auch Google Book Search-Partner und veröffentlicht Videos bei YouTube.
P.S: Und wo ich so sehr die Wichtigkeit von Standards betont habe: so sollte ein Standard nicht aussehen. Wie bei anderen Themen (Wikipedia-Artikeln, Kongress-veranstaltern etc.) reicht es nicht aus, auf den Namen des Herausgebers zu schauen, um Qualität von Müll unterscheiden zu können – ISO-„Standards“ sind beispielsweise nicht nur nicht frei zugänglich (und damit schon mal zweifelhaft) sondern in einigen Fällen eher das Gegenteil eines Standarts.
Web und Desktop wachsen zusammen
16. April 2008 um 14:25 4 KommentareBeim Zusammenlegen der Wikipedia-Artikel „Applet“, „Web-Widget“ und „Desktop-Widget“ zu einem Artikel „Widget“ (ggf. auch „Gadget“ oder „Plugin“, das Grundprinzip ist das Gleiche) ist mir aufgefallen, dass tatsächlich einiges dran an diesen kleinen Programmen, die sich in Windows Sidebar, Apple Dashboard, KDE Plasma, iGoogle, Facebook, Netvibes … oder eigene Webseiten einbinden lassen. Es handelt sich hierbei nicht nur um einen Hype, sondern um eine grundlegende Entwicklung, bei der Web und Desktop zusammenwachsen. Im Zuge der Webanwendungen ist schon länger die Rede davon, dass das Internet wird zum Betriebssystem wird – bisher sah ich das eher skeptisch, aber wenn man die Entwicklung etwas größer betrachtet, wird deutlich, dass da schon etwas Grundlegendes in Bewegung ist. Auf der einen Seite kommt der Desktop zu den Anwendungen ins Web (beispielsweise Google Docs oder die WordPress-Installation in der ich grade tippe) und auf der anderen Seite kommt das Web in Form von Anwendungen auf den Desktop. Da die Hersteller von Mobilgeräten hinsichtlich offener Schnittstellen noch rumzicken, bringt Google mit Android gleich ein eigenes (übrigens Linux-basiertes) Betriebssystem – die restlichen Anwender können Google Desktop als Widget-Plattform verwenden. Weitere Hinweise dieser Entwicklung sind die W3C Web Application Formats Working Group und ihr Entwurf zur Widgets 1.0 recommendation sowie Mozilla Prism, womit Webanwendungen auf den Desktop gebracht werden sollen. Welche Techniken und Systeme sich letzendlich durchsetzen werden, dürfte noch etwas offen bleiben. Um sich auf den grundsätzlichen Wandel vorzubereiten, bieten Widgets jedoch schon heute eine gute Möglichkeit – sollte man sich mal ansehen.
Bibliothekartag 2008 = 0.5?
14. April 2008 um 18:10 11 Kommentare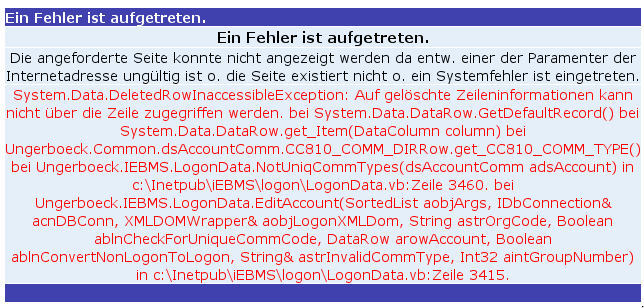
Fehlermeldung bei der Anmeldung
Ein weiteres Beispiel dafür, dass Bibliotheken eigenen technischen Sachverstand benötigen anstatt outzusourcen bietet die Webseite des Bibliothekartags 2008 in Mannheim. Sieht schön aus, ist aber Murx. Statt wesentlicher Informationen in zeitgemäßer Form gibt es Grußworte und einen Offenen Brief an die bibliothekarische Fachöffentlichkeit – als JPG!? Nicht das Tagungsweblog wird eingebunden, sondern ein totes „Forum„. Die Programmübersicht, eigentlich ja der Kern einer solchen Webseite, ist aufgrund von CSS-Spielereien völlig unbrauchbar (der Auslöser dieses Rants). Einfache Tabelle? Thematische Übersicht? Liste der Referenten? Verlinkte Raumpläne? Alles Fehlanzeige. Dass für die Stadtpläne nicht einfach Google-Maps verwendet wurde ist da noch zu vernachlässigen und Ortsangaben wie „Treffpunkt: Foyer der UB, Plöck 107-109, 69117 Heidelberg (Bitte geben Sie als Suchwort ‚Plöck 109‘ ein)“ haben wenigstens Seltenheitswert 😉
Ich finde es äußerst problematisch, wie sich Bibliotheken unnötig in Abhängigkeit von Firmen begeben (hier diese Firmen) und dabei ihrer eigenen Handlungsspielräume und Fähigkeiten einschränken. „Mal schnell“ etwas an der Webseite oder am OPAC ändern geht nicht dann nicht mehr so einfach und/oder kostet zusätzlich Geld. Dem Hinweis zur Entwicklung eigener Kompetenzen von Anne Christensen im Beluga-Projekt kann ich mich nur anschließen. Mir geht der zwar Web-2.0-Leierkasten inzwischen auf den Geist (und ich werde freiwillig keine „Was ist und was soll XY 2.0“-Vorträge mehr halten), aber anscheinend ist es noch immer nicht angekommen, das im Web nur überlebt, wer sich selber mit den zahlreichen Diensten und Angeboten vertraut macht und sie selber ausprobiert. Für Konferenzen fallen mir neben Google Maps spontan Venteria und Mixxt ein und eine Programmübersicht kann so ausschauen. Schön wäre es auch, wenn die einzelnen Veranstaltungen mit Microformats erschlossen sind, jeweils eine eigene URL bekommen und aktiv zum Tagging angeboten werden, so dass sich jeder Besucher mit einem beliebigen Tagging-Dienst und/oder Kalenderprogramm einfach einen Plan zusammenstellen kann. Auch die Einbindung von Feeds zur Veranstaltung wäre nett – wenn sich Bibliotheken nicht mit Sacherschließung, Verschlagwortung und Metadaten auskennen, mit was dann?! Die UB Mannheim zeigt mit ihrem Blog, dem (versteckten) Konferenzblog und Überlegungen zu Tagging zumindest, dass es auch anders geht. Die Pläne zum kritiklosen Einsatz von Primo überzeugen dafür weniger – wurden Alternativen wie Encore, VuFind, OpenBib etc. überhaupt ernsthaft in Betracht gezogen?
Als Tags für Beiträge zum Bibliothekartag schlage ich „bibliothekartag2008“ (genutzt hier, kein Tag bei netbib) und „#bibtag08“ vor – sowas sollte eigentlich auch auf der Webseite zur Veranstaltung vorgegeben und erklärt werden, sonst werden die Tags gar nicht erst verwendet, vergessen oder uneinheitlich benutzt – wie teilweise passiert zur Inetbib 2008: dort wurde mal getaggt mit Leerzeichen, mal ohne und mal ganz ohne Tag. Naja, Googles Volltextsuche wird es schon richten – aber dafür brauchen wir dann auch keine Bibliothekare mehr.
P.S: Beim Versuch mich anzumelden, gab das Registrierungssystem „>sogleich eine Fehlermeldung von sich, als ich meine Telefonnummer korrigieren wollte. Kein Wunder wenn das m:con Congress Center Rosengarten VisualBasic unter IIS verwendet 😉
Working group on digital library APIs and possible outcomes
13. April 2008 um 14:48 3 KommentareLast year the Digital Library Federation (DLF) formed the „ILS Discovery Interface Task Force„, a working group on APIs for digital libraries. See their agenda and the current draft recommendation (February, 15th) for details [via Panlibus]. I’d like to shortly comment on the essential functions they agreed on at a meeting with major library system (ILS) vendors. Peter Murray summarized the functions as „automated interfaces for offloading records from the ILS, a mechanism for determining the availability of an item, and a scheme for creating persistent links to records.“
On the one hand I welcome if vendors try to agree on (open) standards and service oriented architecture. On the other hand the working group is yet another top-down effort to discuss things that just have to be implemented based on existing Internet standards.
1. Harvesting: In the library world this is mainly done via OAI-PMH. I’d also consider RSS and Atom. To fetch single records, there is unAPI – which the DLF group does not mention. There is no need for any other harvesting API – missing features (if any) should be integrated into extensions and/or next versions of OAI-PMH and ATOM instead of inventing something new. P.S: Google Wave shows what to expect in the next years.
2. Search: There is still good old overblown Z39.50. The near future is (slightly overblown) SRU/SRW and (simple) OpenSearch. There is no need for discussion but for open implementations of SRU (I am still waiting for a full client implementation in Perl). I suppose that next generation search interfaces will be based on SPARQL or other RDF-stuff.
2. Availability: The announcement says: „This functionality will be implemented through a simple REST interface to be specified by the ILS-DI task group“. Yes, there is definitely a need (in december I wrote about such an API in German). However the main point is not the API but to define what „availability“ means. Please focus on this. P.S: DAIA is now available.
3. Linking: For „Linking in a stable manner to any item in an OPAC in a way that allows services to be invoked on it“ (announcement) there is no need to create new APIs. Add and propagate clean URIs for your items and point to your APIs via autodiscovery (HTML link element). That’s all. Really. To query and distribute general links for a given identifier, I created the SeeAlso API which is used more and more in our libraries.
Furthermore the draft contains a section on „Patron functionality“ which is going to be based on NCIP and SIP2. Both are dead ends in my point of view. You should better look at projects outside the library world and try to define schemas/ontologies for patrons and patron data (hint: patrons are also called „customer“ and „user“). Again: the API itself is not underdefined – it’s the data which we need to agree on.
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare