Linking to Wikipedia via ISBN
5. Dezember 2007 um 19:52 2 KommentareTwo weeks ago I announced a new beta webservice for linking from title data to German Wikipedia articles that cite a given work by ISBN. Now Lambert pointed me to a message by Eric Hellmann about xISBN supporting links to the English Wikipedia since last week. This makes GBV one week earlier then OCLC and both of us ten month later then LibraryThing. The idea is not new but based on the work of Lars Aronsson, Spiritus rector of future library systems.
The three services have been developed partly parallel based on some same code. Here are two examples of the xISBN service by Xiaoming Liu and the GBV service that I am developing. xISBN is based on a powerfull API with many query parameters and planned to be part of WorldCat Grid Services (more about this maybe here, here, here, and here), while my service is based on a simple API called SeeAlso which is based on OpenSearch Suggestions and unAPI. Both approaches have their pros and cons. I will provide more information as soon as our server is more stable and the scripts are clean enough to get published at CPAN. Meanwhile I encourage everyone to play with OCLC’s xISBN (via an API of its own), WorldCat Idenities (via SRU), LibraryThing for Libraries (via an API of its own), available catalouges (via Z39.50, via SRU and via other APIs), the Wikipedia Query API, and the growing number of other services. Let’s mash up the library systems for the future!
Verweise auf passende Rezensionen
5. Dezember 2007 um 16:35 4 KommentareNachdem ich in einer Fortbildung (siehe slides) am Rande die Realisierung von Links auf Wikipedia mittels des SeeAlso-Protokolls vorgestellt habe, kam von einer Teilnehmerin die Idee, auf die selbe Weise auf Rezensionen zu verweisen. Neben Amazon (wo Rezensionen manipuliert werden) und LibraryThing gibt es eine Vielzahl von Rezensionsdiensten von Fachreferenten und Wissenschaftlern. Leider bekommt dies außerhalb enger Fachcommunities kein Schwein mit, da Rezensionen weder systematisch erschlossen werden, noch praktikabel recherchierbar sind – dies gilt anscheinend auch für Rezensionen in Zeitungen, z.B. bei der ZEIT. Die Idee, über einen Linkserver Verweise auf passende Rezensionen zu liefern, finde ich wunderbar, weshalb ich gleich mal ein Konzept erstellt habe. Hier nur das Diagram, ausführlich im GBV-Wiki:
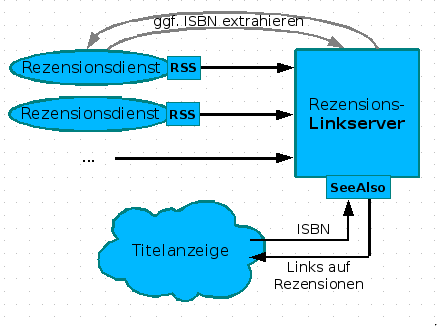
Leider hinken die meisten Rezensionsdienste dem Stand der Technik hinterher und bieten keine (oder kaputte) Feeds an. Wollen die nicht gelesen werden? Nun ja, vielleicht wachen Sie noch auf. Kennt jemand weitere Rezensionsdienste mit benutzbaren Feeds? So lange nicht genügend Rezensionsdienste verfügbar sind, ist der skizzierte Linkserver den Aufwand nicht wert, aber das kann ja noch kommen. Bitte mehr solcher Ideen! Wer nicht weiß, was Feeds sind und sich nicht vorstellen kann, wie ein Linkserver funktioniert, oder den Unterschied zwischen Indexbasierter und Metasuchmaschine nicht einigermaßen verinnerlicht hat, wird auch nicht auf die Ideen kommen, die notwendig sind, damit Bibliotheken nicht in der Bedeutungslosigkeit verschwinden. Deshalb sind Fortbildung und genügend freie Zeit zum Experimentieren so wichtig – zum Beispiel mit diesen Web 2.0-Diensten!
P.S: Neben Rezensionen und Lins auf Wikipedia können auch andere Informationen zu einem Werk von Interesse sein, z.B. Zusammenfassungen, Erwähnungen in Blogs etc.
Social Cataloging in Wikipedia
5. Dezember 2007 um 01:19 Keine KommentareLast week I gave an introduction into social tagging and cataloging for librarians (some German slides here at Slideshare). In a discussion on German Wikipedia about COinS I was pointed to the French Wikipedia: They have a special namespace référence to store more detailled bibliographic information (see MediaWiki-namespaces in general), some more information is collected in Projet:Références, but my French is too little to find out much. This example may demonstrate the concept:
The article „Première période intermédiaire égyptienne“ cites the source „Nicolas Grimal, Histoire de l’Égypte ancienne, 1988“. The citation provides a link to on a special page that lists several editions of the work. Actually this is another implementation of FRBR.
I like the idea of seggregating full bibliographic record and reference in the Wikipedia article, but the concrete solution is too complicated and limited. Wikipedia with flat text is just not the right tool to store bibliographic data. Maybe Semantic MediaWiki can help, but a multilingual approach like LibraryThing does is better. French Wikipedians should not have to duplicate cataloging efforts, but just point to LibraryThing, WorldCat or whatever bibliographic authority is usable. By the way most library catalouges are not usable in this sense – on the Web noone cares how good you data is if you cannot directly link to it and use it in other context.
Wikipedia-Wortschatz-Analyse aktualisiert
3. Dezember 2007 um 00:55 Keine KommentareWie Matthias Richter mitteilt, hat er die Wikipedia-Datenbasis im Deutschen Wortschatz-Portal aktualisiert. Neben statistisch signifikant häufig in einem Satz vorkommenden Wörtern, wird unter http://wortschatz.uni-leipzig.de/WP/ nun auch die Linkstruktur zwischen den Artikel analysiert. Siehe da: Internet wird signifikant häufiger zusammen mit Bibliothek verlinkt – noch häufiger aber sind Archiv und Museum. Ich schließe daraus unwissenschaftlicherweise, dass noch nicht ausgemacht ist, ob Bibliotheken irgendwann nur noch Archive und Museen sein werden oder im Internet auch in Zukunft für die Informationsversorgung relevant sein werden 😉

Relevant APIs for (digital) libraries
30. November 2007 um 14:50 5 KommentareMy current impression of OCLC/WorldCat Service Grid is still far to abstract – instead of creating a framework, we (libraries and library associations) should agree upon some open protocols and (metadata) formats. To start with, here is a list of relevant, existing open standard APIs from my point of view:
Search: SRU/SRW (including CQL), OpenSearch, Z39.50
Harvest/Syndicate: OAI-PMH, RSS, Atom Syndication (also with ATOM Extensions)
Copy/Provide: unAPI, COinS, Microformats (not a real API but a way to provide data)
Upload/Edit: SRU Update, Atom Publishing Protocol
Identity Management: Shibboleth (and other SAML-based protocols), OpenID (see also OSIS)
For more complex applications, additional (REST)-APIs and common metadata standards need to be found (or defined) – but only if the application is just another kind of search, harvest/syndicate, copy/provide, upload/edit, or Identity Management.
P.S: I forgot NCIP, a „standard for the exchange of circulation data“. Frankly I don’t fully understand the meaning and importance of „circulation data“ and the standard looks more complex then needed. More on APIs for libraries can be found in WorldCat Developer Network, in the Jangle project and a DLF Working group on digital library APIs. For staying in the limited world if libraries, this may suffice, but on the web simplicity and availability of implementations matters – that’s why I am working on the SeeAlso linkserver protocol and now at a simple API to query availaibility information (more in August/September 2008).
P.P.S: A more detailed list of concrete library-related APIs was published by Roy Tennant based on a list by Owen Stephens.
P.P.S: And another list by Stephen Abram (SirsiDynix) from September 1st, 2009
OCLC Grid Services – first insights
28. November 2007 um 10:58 1 KommentarI am just sitting at a library developer meeting at OCLC|PICA in Leiden to get to know more about OCLC Service Grid, WorldCat Grid, or whatever the new service-oriented product portfolio of OCLC will be called. As Roy Tennant pointed out, our meeting is „completely bloggable“ so here we are – a dozen of European kind-of system librarians.
The „Grid Services“ that OCLC is going to provide is based on the „OCLC Services Architecture“ (OSA), a framework by which network services are built – I am fundamentally sceptical on additional frameworks, but let’s have a look.
The basic idea about services is to provide a set of small methods for a specific purpose that can be accessed via HTTP. People can then use this services and build and share unexpected application with them – a principle that is called Mashups.
The OCLC Grid portfolio will have four basic pillars:
network services: search services, metadata extraction, identity management, payment services, social services (voting, commenting, tagging…) etc.
registries and data resources: bibliographic registries, knowledge bases, registries of institutions etc. (see WorldCat registries)
reusable components: a toolbox of programming components (clients, samples, source code libraries etc.)
community: a developer network, involvement in open source developement etc.
Soon after social services were mentioned, at heavy discussion on reviews, and commenting started – I find the questions raised with user generated content are less technical but more social. Paul stressed that users are less and less interested in metadata but directly want the content of an information object (book, article, book chapter etc.). The community aspect is still somehow vague to me, we had some discussion about it too. Service oriented architecture also implies a different way of software engineering, which can partly be described by the „perpetual beta“ principle. I am very exited about this change and how it will be practised at OCLC|PICA. Luckily I don’t have to think about the business model and legal part which is not trivial: everyone wants to use services for free, but services need work to get established and maintained, so how do we best distribute the costs among libraries?
That’s all for the introduction, we will get into more concrete services later.
Friendly Fire
27. November 2007 um 01:20 Keine KommentareDass mit so genannten „nicht-tötlichen Waffen“ (noch euphemistischer: „nicht-letales Wirkmittel“) wie zum Beispiel Elektroschockpistolen schon zahlreiche Menschen getötet wurden, ist dank YouTube-Kultur nicht mehr ganz so unbekannt. Die nächste Entwicklung des Sicherheitswahns stellt Kai Raven vor: Killer-Roboter, die auch als besonders geeignet für den Einsatz gegen Demonstranten beworben werden. Die Robotergesetze sind ihnen eher fremd, stattdessen wird die Reizschwelle, gegen andere Menschen vorzugehen, weiter gesenkt – „wir haben nicht geschossen, das war der Robi, dieser Schelm!“, „Ach lass ihn noch ein wenig schießen, ist er wird ja nicht müde und die meisten gehen doch nicht von tot!“ etc. Die Zahl der Opfer des Straßenverkehrs (über 5.000 pro Jahr) ist übrigens zumindest in Deutschland noch ungleich höher als die der Opfer eines irregeleiteten Sicherheitsverständnisses, wobei es mitunter auch Überschneidungen gibt.
Mashups und Mashup-Editoren
26. November 2007 um 01:50 4 KommentareUnter der Bezeichnung ‚Mashups‘ spielt im Internet das Zusammenführen von verschiedenen Quellen und Diensten eine zunehmende Rolle. Der folgende studentische Beitrag gibt eine kurze Einführung in das Thema Mashups und Mashup-Editoren. Dazu gibt es eine passendes Beispiel bei Pageflakes und eine weiterführende Literaturliste bei BibSonomy.
Beitrag Mashups und Mashup-Editoren weiterlesen…
Wer nichts weiß, muss alles glauben
26. November 2007 um 00:05 4 KommentareVor genau einem halben Jahr schrieb ich über das Verhältnis von Wikipedia und Titanic-Magzin. Mit dem aktuellen Dezember-Heft (Nr. 338) ist auf Seite 40/41 eine doppelseitige Wikipedia-Anzeige hinzugekommen – ich weiß nicht, was sowas normal kosten würde, in jedem Fall Danke für die Sachspende! Abgebildet ist das historische Händehalten von Mitterrand und Kohl am 11. November 1984 in Verdun (mit dem auch schon ein Schwulen-Sender Werbung gemacht hat) – nur dass statt Mitterand der Kopf des wunderbaren Louis de Funès einmontiert wurde. Unten rechts findet sich neben dem Wikipedia-Logo der Spruch „Wer nichts weiß, muss alles glauben“, der vermutlich von Marie von Ebner-Eschenbach (1830-1916) stammt, was ich einfach mal so glauben muss, obgleich Zitate besonders gerne falsch überliefert werden. Wer nichts weiß und/oder nicht selber recherchieren und Quellen einschätzen kann, muss halt alles glauben. Oder er glaubt nichts – das wird man ja wohl noch glauben dürfen (super-sicheres Originalzitat von Karl Valentin).
Noch interessanter finde ich in dieser Ausgabe den zweitiligen Artikel von Christian Meurer über die deutsche Figur Horst Mahler. Dessen Lebenslauf mit prominenten Stationen von RAF bis NPD und vielen illustren Zeitgenossen dürfte sich hervorragend dazu eignen, die Bundesdeutsche Geschichte der Nachkriegszeit darzustellen: Andreas Baade (gähn), Hans-Christian Ströbele (inzwischen ohne Mahler einziger direkt in den Bundestag gewählter Grüner), Otto-„BigBrother-Lifetime-Award“-Schily, Gerhard Schröder (Kennt den noch jemand? Ich muss mal in Moskau nachfragen!), Wolf Biermann (Musiker?), Georg Wilhelm Friedrich Hegel (doppelgähn), Günter Rohrmoser (der nicht zu den sympatischen Menschen gehört, die das Bundesverdienstkreuz abgelehnt haben), Erich-„Paolo Pinkas“-Friedmann etc. Bei so vielen lustigen Deutschen könnte doch mal ein „Schlussstrich“ unter die ollen Adolf-Witze gezogen werden: die BRD übertrifft das 3. Reich auch an Witzfiguren und komischen Begebenheiten, also her mit der Mahler-Biografie.
Ergo: Titanic ist lehrreich und unterhaltsam, gerade aufgrund all der ernsthhaften Themen, die im Heft zu finden sind. Wahrscheinlich ist guter Humor sowieso nur zu ernsthaften Themen möglich. Macht es lieber nicht, wie die Universität der Bundeswehr, die der Zeitschriftendatenbank nach ihr seit dem Gründungsjahr (1979) laufendes Titanic-Abonnement 1991 einfach einstellte, während vorbildhaft die Bibliothek der Friedrich Ebert-Stiftung die Jahrgänge bis 2005 auf Mikrofilm bereithält. In diesem Sinne: Viel Spaß noch!
Weblog-Kurse im Kommen
15. November 2007 um 12:48 3 KommentareBald bloggt jeder Bibliothekar. Während ich in Göttingen einen Workshop gebe, scheint gleichzeitig Lambert in Berlin ebenfalls fortzubilden. 🙂 Hoffentlich schaltet er schnell mal unsere Kommentare frei.
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare