Linkserver auch beim BSZ
14. Februar 2008 um 00:20 1 KommentarIch muss zugeben, dass ich den Verbundkatalog des Südwestdeutschen Bibliotheksverbundes (SWB) nur sehr selten nutze und auch nur ganz zufällig darauf gestoßen bin – jedenfalls ist mir gerade aufgefallen, dass das BSZ (die Zentrale des SWB) ebenfalls einen Linkserver für seine Kataloge anbietet. Die Eigenentwicklung des BSZ wird folgendermaßen beschrieben:
Anreicherung des Katalogs mit Internet-Ressourcen:
Die Einzeltrefferanzeige im Web-Katalog kann ergänzt werden durch die Einblendung von dynamisch erzeugten Links zum Buchhandel (z.Zt. amazon, lehmanns, kno-k&v, libri, abebooks, booklooker, zvab). Soweit dort vorhanden werden das Cover und ein direkter Link zum Medium (i.e. der ISBN) angezeigt. Der Link-Server läuft zentral im BSZ

Im Verbundkatalog werden die Links mit dem Button „Verfügbarkeit im Buchhandel prüfen“ eingeblendet, wie zum Beispiel bei diesem guten Buch ausprobiert werden kann (siehe nebenstehendes Bild). Die Einbindung geschieht zwar nicht über eine sauber definierte Schnittstellen sondern als proprietärer HTML-Batzen, aber prinzipiell sehe ich kein Hindernis, den Service auf SeeAlso umzustellen, so dass verschiedene Linkserver einfacher gemeinsam in unterschiedliche Anwendungen eingebunden werden können. Ich habe mir erstmal verkniffen, zur Demonstration einen vollständigen SeeAlso-Proxy zu schreiben zumal dazu ein kleiner Trick notwendig wäre (stattdessen gibt es einen experimentellen Proxy für Google Buchsuche). Das Prinzip ist jedenfalls das selbe wie bei den Linkservern der VZG des GBV. Ein spontanes Lob an die Kollegen im Süden!
P.S: Der Linkserver des BSZ nimmt wie isbn2wikipedia auch ISBNs und liefert (in zusätzlichem HTML) eingebettete Links – ich hoffe das führt nicht zur irrigen Annahme, dass Linkserver nur mit ISBNs funktionieren!
P.P.S: Ich höre schon (wie bei Wikipedia) den Aufschrei der Entrüstung, aber muss es mal deutlich sagen: Google Buchsuche ist sehr nützlich und ein Link darauf fast immer ein Mehrwert. So habe ich im konkreten Fall zwar keinen Volltext aber wie gesucht Rezensionen gefunden (die FAZ-Kritik von Martin Lhotzky ist übrigens Bullshit) – Bibliotheken müssten für sowas wahrscheinlich erstmal Analysen und Regelwerke erstellen, was eine Rezension sei und wer wie wann bestimmen darf, was wie wo genau als zusätzlicher Link eingetragen wird – anstatt den Nutzer einfach selber entscheiden zu lassen.
Felix Klein über Riemann’sche Flächen in Katalogen
23. Januar 2008 um 11:43 6 Kommentare
In einem Posting von letztem Jahr auf ol-tech wies Paul Rubin auf dieses Digitalisat (vollständiger Datensatz bei Archive.org) hin, mit dem die OCR ihre Schwierigkeiten haben dürfte: Abgesehen vom Titelblatt und Inhaltsverzeichnis ist das Vorlesungsskript „Riemann’sche Flächen 1“ (gehalten im Wintersemester 1891/92 in Göttingen) von Felix Klein handschriftlich verfasst! Der entsprechende Katalogeintrag im GBV ist dieser. Das Digitalisat stammt vom „zweiten Abdruck“ (1894), die erste Ausgabe (dieser Datensatz) ist von 1892. Einen unveränderte Nachdruck gab es 1906 (dieser Datensatz). 1986 erschien im Teubner-Verlag eine kommentierte Neuauflage (ISBN 3-211-95829-0), die im GBV-Katalog als Duplikat (hier und hier) verzeichnet ist. Wie aus dem Digitalisat bei Open Library und Internet Archive nicht ganz hervorgeht, gibt es auch den Zweiten Teil mit „Riemann’sche Flächen 2“ (siehe Datensatz) gehalten während des Sommer-Semesters 1892.
Abgesehen vom Inhalt finde das Beispiel schön, da es zwei Probleme und Herausforderungen illustriert. Duplikate und die Schwierigkeit sie automatisch zu erkennen (ein Algorithmus würde wahrscheinlich Teil 1 und Teil 2 zusammenschmeißen) sowie die fehlende semantische Verknüpfungen zwischen Datensätzen. Warum wird bei der Erstausgabe von Teil 1 nicht ein Verweis auf die folgenden Ausgaben, auf das Digitalisat und auf Teil 2 angezeigt? Je mehr ich mich mit dem Thema beschäftige, desto mehr komme ich zur Überzeugung, dass zu solch einer semantischen Tiefenerschließung alle Bibliothekare der Welt nicht ausreichen werden. Ein offener Ansatz wie beim Open Library Projekt, wo Katalogisate wie in Wikipedia von jedem gändert werden können, ist wahrscheinlich die einzige Möglichkeit, mit den Massen an Datensätzen und Verknüpfungsmöglichkeiten fertig zu werden.
P.S: Noch zwei amüsante Fundstücke: es gibt doch einen „Volltext“ und wie sich am Umschlag ablesen lässt wurde das zugrunde liegende Exemplar der Universität Berkeley zuletzt 1987 ausgeliehen worden, bevor es digitalisiert wurde.
Schnittstelle für Verfügbarkeitsdaten von Bibliotheksbeständen
21. Januar 2008 um 11:22 4 KommentareLetzen Dezember habe ich über Serviceorientierte Architektur geschrieben und bin unter Anderem auf den Heidelberger UB-Katalog eingegangen. Dabei ging es darum, wie Daten einzelner Exemplare von Bibliotheksbeständen – speziell Verfügbarkeitsdaten – über eine Schnittstelle abgefragt werden können. Bislang gibt es dafür keinen einfachen, einheitlichen Standards sondern höchstens verschiedende proprietäre Verfahren. Till hat mich zu Recht auf den Artikel „Beyond OPAC 2.0: Library Catalog as Versatile Discovery Platform“ hingewiesen, in dem die API-Architektur des Katalogs an der North Carolina State University vorgestellt wurde. Die Beispiele zeigen gut, was mit dem Buzzword „Serviceorientierte Architektu“ eigentlich gemeint ist, wie sowas in Bibliotheken umgesetzt werden kann und was für Vorteile der Einsatz von einfachen, webbasierten Schnittstellen bringt. Die als CatalogWS bezeichnete API ist – wie es sich gehört – offen dokumentiert. CatalogWS enthält einen Catalog Availability Web Service, der ausgehend von einer ISBN ermittelt, in welchen (Teil)bibliotheken ein Titel verfügbar oder ausgeliehen ist.
Bei Bedarf könnte ich mal versuchen, diese API für die GBV-Kataloge zu implementieren. Andererseits sollte man sich vielleicht erstmal Gedanken darüber machen, was es noch für Kandidaten für eine Verfügbarkeitsschnittstelle gibt und welche Daten über so eine Schnittstelle abfragbar sein sollten: Das NCIP-Protokoll scheint mir wie Z39.50 nicht wirklich zukunftsfähig zu sein. Janifer Gatenby macht in ihrem Vortrag „Bridging the gap between discovery and delivery“ (PPT) weitere durchdachte Vorschläge. Auf den Mailinglisten CODE4LIB und PERL4LIB habe ich letzte Woche herumposaunt, wie wichtig eine Holding-API wäre und dass das doch alles eigentlich ganz einfach sei. Neben Iinteressanten Bemerkungen zu FRBR bin ich daraufhin auf Holding-data in Z39.50 hingewiesen worden. In den PICA-LBS-Systemen stehen die Verfügbarkeitsdaten soweit ich es herausgefunden, habe im Feld 201@, aber nur teilweise. Für die weitere Umsetzung wäre es wahrscheinlich sinnvoll, erstmal alle in der Praxis vorkommenden Verfügbarkeits-Stati (ausleihbar, Präsenzbestand, Kurzausleihe, ausgeliehen, unbekannt…) zu ermitteln. Für elektronische Publikationen sollte die Schnittstelle außerdem irgendwie mit existierenden Linkresolvern zusammenarbeiten können. Eine einfache Schnittstelle für Verfügbarkeitsdaten von Bibliotheken ist also nicht ganz trivial, aber solange nicht jeder Spezialfall berücksichtigt wird oder erstmal ein Gremium eingesetzt werden muss, dürfte es machbar sein. Hat sonst noch jemand Interesse?
Heidelberger Katalog auf dem Weg zu Serviceorientierter Architektur
23. Dezember 2007 um 20:59 4 KommentareDie zunehmende Trennung von Bibliotheksdaten und ihrer Präsentation zeigt „HEIDI“, der Katalog der Unibibliothek Heidelberg. Vieles, was moderne Bibliothekskataloge bieten sollten, wie eine ansprechende Oberfläche, Einschränkung der Treffermenge per Drilldown, Permalinks, Exportmöglichkeit (u.A. direkt nach BibSonomy), RSS-Feeds und nicht zuletzt eine aktuelle Hilfe für Benutzer ist hier – zwar nicht immer perfekt, aber auf jeden Fall vorbildhaft – umgesetzt. Soweit ich es von Außen beurteilen kann, baut der Katalog auf zentralen Daten des Südwestdeutschen Bibliotheksverbundes (SWB) und lokalen Daten des lokalen Bibliothekssystems auf. Zum Vergleich hier ein Titel in HEIDI und der selbe Titel im SWB-Verbundkatalog. Aus dem Lokalsystem werden die Titeldaten mit Bestands- und Verfügbarkeitsdaten der einzelnen Exemplare angereichter, also Signatur, Medien/Inventarnummer, Standort, Status etc.:

Die tabellarische Ansicht diese Daten erinnert mich an WorldCat local, das sich zu WorldCat teilweise so verhält wie ein Bibliotheks-OPAC zu einem Verbundsystem. Hier ein Beispieldatensatz bei den University of Washington Libraries (und der gleiche Datensatz in WorldCat). Die Exemplardaten werden aus dem lokalen Bibliothekssystem als HTML-Haufen per JavaScript nachgeladen, das sieht dann so aus:

Bei HEIDI findet die Integration von Titel- und Exemplardaten serverseitig statt, dafür macht der Katalog an anderer Stelle rege von JavaScript Gebrauch. In beiden Fällen wird eine proprietäres Verfahren genutzt, um ausgehend von einem Titel im Katalog, die aktuellen Exemplardaten und Ausleihstati zu erhalten. Idealerweise sollte dafür ein einheitliches, offenes und webbasiertes Verfahren, d.h. ein RDF-, XML-, Micro- o.Ä. -format und eine Webschnittstelle existieren, so dass es für den Katalog praktisch egal ist, welches lokale Ausleih- und Bestandssystem im Hintergrund vorhanden ist. Die Suchoberfläche greift damit als als ein unabhängiger Dienst auf Katalog und Ausleihsystem zu, die ihrerseits eigene unabhängige Dienste mit klar definierten, einfachen Schnittstellen bereitstellen. Man spricht bei solch einem Design auch von „Serviceorientierter Architektur“ (SOA), siehe dazu der Vortrag auf dem letzten Sun-Summit. Eigentlich hätte beispielsweise die IFLA sich längst um einen Standard für Exemplardaten samt Referenz-implementation kümmern sollen, aber bei FRBR hat sie es ja auch nicht geschafft, eine RDF-Implementierung auf die Beine zu stellen; ich denke deshalb, es wird eher etwas aus der Praxis kommen, zum Beispiel im Rahmen von Beluga. Der Heidelberger Katalog setzt SOA noch nicht ganz um, geht allerdings schon in die richtige Richtung. Beispielweise wird parallel im Digitalisierten Zettelkatalog DigiKat gesucht und ggf. ein Hinweis auf mögliche Treffer eingeblendet. Wenn dafür ein offener Standard (zum Beispiel OpenSearch oder SRU) verwendet würde, könnten erstens andere Kataloge ebenso dynamisch zum DigiKat verweisen und zweitens in fünf Minuten andere Kataloge neben dem DigiKat hinzugefügt werden.
Ein weiteres Feature von HEIDI sind die Personeneinträge, von denen auf die deutschsprachige Wikipedia verwiesen wird – hier ein Beispiel und der entsprechende Datensatz im SWB. Die Verlinkung auf Wikipedia geschieht unter Anderem mit Hilfe der Personendaten und wurde von meinem Wikipedia-Kollegen „Kolossos“ erdacht und umgesetzt. Über einen statischen Link wird eine Suche durch einen Webservice angestossen, der mit Hilfe der PND und des Namens einen passenden biografischen Wikipedia-Artikel sucht. Ich könnte den Webservice so erweitern, dass er die SeeAlso-API verwendet (siehe Ankündigung), so dass Links auf Wikipedia auch nur dann angeboten werden, wenn ein passender Artikel vorhanden ist. Für einen verlässlichen und nachhaltigen Dienst ist es dazu jedoch notwendig, dass der SWB seine Personenangaben und -Normdaten mit der PND zusammenbringt. Natürlich könnte auch nach Namen gesucht werden aber warum dann nicht gleich den Namen einmal in der PND suchen und dann die PND-Nummer im Titel-Datensatz abspeichern? Hilfreich wäre dazu ein Webservice, der bei Übergabe eines Namens passende PND-Nummern liefert. Die Fälle, in denen eine automatische Zuordnung nicht möglich ist, können ja semiautomatisch gelöst werden, so wie es seit über zwei Jahren der Wikipedianer APPER mit den Personendaten vormacht. Hilfreich für die Umsetzung wäre es, wenn die Deutsche Nationalbibliothek URIs für ihre Normdaten vergibt und ihre Daten besser im Netz verfügbar macht, zum Beispiel in Form einer Download-Möglichkeit der gesamten PND.
P.S.: Hier ist testweise die PND-Suche in Wikipedia als SeeAlso-Service umgesetzt, zum Ausprobieren kann dieser Client verwendet werden, einfach bei „Identifier“ eine PND eingeben (z.B. „124448615“).
Open Knowledge Foundation fordert freie Katalogdaten
15. Dezember 2007 um 13:47 Keine KommentareDie Open Knowledge Foundation (OKF) hat, wie unter Anderem netbib berichtet in Reaktion auf den Report on the Future of Bibliographic Control der Library of Congress eine Petition für den freien Zugang zu bibliographische Daten veröffentlicht (siehe Hintergrund): „[…] Bibliographic records are key part of our shared cultural heritage. They too should therefore be made available to the public for access and re-use without restriction. […]“. Am 15. März 2008 veranstaltet die Open Knowledge Foundation übrigens die zweite Open Knowledge Conference in London, während Creative Commons heute das 5-jährige feiert.
Chatbox als Widget im Katalog
10. Dezember 2007 um 11:07 Keine KommentareLambert weist in Netbib auf die Widget-basierte Einbindung einer Chatbox im Katalog hin, wenn eine Suche keine Treffer liefert. Ein schönes Beispiel dafür, wie einzelne Dienstleistungen als eigenständige Services angeboten und kombiniert werden können. Mit der Ende September vorgestellte Universal Widget API (UWA) könnte das etwas einfacher werden. Dass trotz aller Begeisterung nicht jeder Service in jedem Kontext sinnvoll ist, dürfte klar sein – ein Haufen Widgets macht noch keine Bibliothek, dafür sind Bibliothekare notwendig, die eigene Ideen für Services und Widgets entwickeln und bestehende Dienste ausprobieren – die konkrete Programmierung neuer Widgets kann ja gerne Experten überlassen werden, aber Existierendes zusammenführen, Ausprobieren, Diskutieren, und Ideen entwickeln kann nicht einigen Wenigen überlassen werden!
Verweise auf passende Rezensionen
5. Dezember 2007 um 16:35 4 KommentareNachdem ich in einer Fortbildung (siehe slides) am Rande die Realisierung von Links auf Wikipedia mittels des SeeAlso-Protokolls vorgestellt habe, kam von einer Teilnehmerin die Idee, auf die selbe Weise auf Rezensionen zu verweisen. Neben Amazon (wo Rezensionen manipuliert werden) und LibraryThing gibt es eine Vielzahl von Rezensionsdiensten von Fachreferenten und Wissenschaftlern. Leider bekommt dies außerhalb enger Fachcommunities kein Schwein mit, da Rezensionen weder systematisch erschlossen werden, noch praktikabel recherchierbar sind – dies gilt anscheinend auch für Rezensionen in Zeitungen, z.B. bei der ZEIT. Die Idee, über einen Linkserver Verweise auf passende Rezensionen zu liefern, finde ich wunderbar, weshalb ich gleich mal ein Konzept erstellt habe. Hier nur das Diagram, ausführlich im GBV-Wiki:
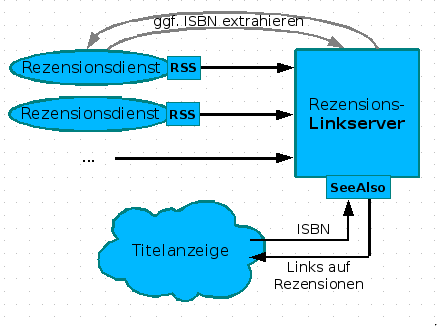
Leider hinken die meisten Rezensionsdienste dem Stand der Technik hinterher und bieten keine (oder kaputte) Feeds an. Wollen die nicht gelesen werden? Nun ja, vielleicht wachen Sie noch auf. Kennt jemand weitere Rezensionsdienste mit benutzbaren Feeds? So lange nicht genügend Rezensionsdienste verfügbar sind, ist der skizzierte Linkserver den Aufwand nicht wert, aber das kann ja noch kommen. Bitte mehr solcher Ideen! Wer nicht weiß, was Feeds sind und sich nicht vorstellen kann, wie ein Linkserver funktioniert, oder den Unterschied zwischen Indexbasierter und Metasuchmaschine nicht einigermaßen verinnerlicht hat, wird auch nicht auf die Ideen kommen, die notwendig sind, damit Bibliotheken nicht in der Bedeutungslosigkeit verschwinden. Deshalb sind Fortbildung und genügend freie Zeit zum Experimentieren so wichtig – zum Beispiel mit diesen Web 2.0-Diensten!
P.S: Neben Rezensionen und Lins auf Wikipedia können auch andere Informationen zu einem Werk von Interesse sein, z.B. Zusammenfassungen, Erwähnungen in Blogs etc.
GBV verlinkt auf Wikipedia mit SeeAlso-Linkserver
14. November 2007 um 17:17 8 KommentareDa es anscheinend bisher niemand in der Biblioblogosphere gemerkt hat und da ich es gerade auf dem Sun-Summit in Frankfurt vorgestellt habe, möchte ich hiermit auf einen neuen Webservice des GBV hinweisen: Mit SeeAlso werden seit Ende letzter Woche dynamisch im GBV-Katalog Links auf Wikipedia-Artikel eingeblendet, in deren Literaturangaben ISBN-Nummern enthalten sind: hier ein Beispiel. Das ganze läuft zunächst als Beta-Test und daher noch etwas langsam – dafür können die Linkserver hier ausprobiert werden; unter Anderem gibt es auch Links auf LibraryThing und VD17. Ideen für weitere Linkserver nach dem SeeAlso–Prinzip sind herzlich willkommen. Sobald die Server-Software als Open Source publiziert wird, können auch andere Einrichtungen eigene Linkserver anbieten. Die Einbindung in eigene Anwendung (vor allem Kataloge) funktioniert schon jetzt – happy mashuping!
GBV bietet COinS an
1. November 2007 um 16:12 3 KommentareWie ich eben in INETBIB schrieb, beginnt der GBV jetzt damit, für seine Kataloge COinS anzubieten. Damit können bibliographische Metadaten einfach aus dem Katalog in eigene Anwendungen übernommen werden. Zu den populären Anwendungen zur Literaturverwaltung gehört das Firefox-Plugin Zotero, welches soeben ein Jahr alt georden und in der Version 1.0 herausgekommen ist. Wie Zotero zusammen mit anderen Social-Software-Werkzeugen und dem Firefox-Abkömmling Flock in eine hocheffizienten Arbeitsplatz integriert werden kann, zeigt dieses Video. Eine anderes Bibliographiewerkzeug, dass COinS unterstützen soll ist Citavi.
Wie Patrick bemerkte ist es bereits seit Anfang August möglich, mit Zotero Daten aus dem GBV zu übernehmen. Dazu hatte der Zotero-Entwickler Ramesh Srigiriraju einen „Scraper“ in JavaScript geschrieben, der das RIS-Format interpretieren kann, welches von der PSI-Katalogsoftware mit dem Parameter PRS=RIS exportiert wird – wer genauer sehen möchte, wie so etwas funktioniert, sollte im Quelltext nach „GSO“ suchen.
Das Angebot von Daten via COinS ist wesentlich leichter nutzbar – sucht im im GSO-Katalog einfach mal nach einem Titel und schaut dann im HTML-Quelltext nach der Zeichenkette „Z3988“. Damit das Angebot auch in lokalen OPACs nutzbar ist, sollten meiner Meinung nach die einzelnen GBV-Bibliotheken erstmal selber Zotero ausprobieren und überlegen, wie sie das Angebot ihren Benutzern am Besten bekannt machen können.
Für die ganz harten Bibliothekshacker hier ein Stück Perl, um COinS für eigene Anwendungen aus beliebigen Webseiten auszulesen:
use HTML::TreeBuilder::XPath;
use LWP::UserAgent;
use URI::OpenURL;
use URI;
my $url = URI->new(shift @ARGV) or die "Please specify an URL!";
my $ua = LWP::UserAgent->new();
my $res = $ua->get($url);
my $html = $res->decoded_content;
my $tree= HTML::TreeBuilder::XPath->new_from_content( $html );
my @coins = $tree->findnodes( '//span[@class="Z3988"]/@title');
@coins = map { URI::OpenURL->new("?" . $_->getValue() ); } (@coins);
foreach my $c (@coins) {
print $c->canonical->dump() . "\n";
}
Bibsonomy bietet API an
7. Oktober 2007 um 19:51 1 KommentarDer aus Kassel stammende Social Bookmarking und Catalouging-Dienst Bibsonomy bietet seit letzter Woche eine ziemlich umfangreiche, REST-basierte API an. Ein Client für JabRef ist auch schon erhältlich, allerdings anscheinend nur als Jar-File. Außerdem ist eine Java-API in Arbeit – auf der Projektseite zum Java-CLient ist übrigens schön das interne Datenmodell von Bibsonomy dargestellt.
Eine weitere Neuerung in Bibsonomy ist die Volltextsuche über alle (oder zumindest einige?) Metadatenfelder in einem gemeinsamen Index – dadurch ist beispielsweise Ego-Suche und die Suche nach konkreten Publikationen möglich – dabei fällt mir wieder die Menge an Duplikaten auf – also nicht immer nur auf den GBV schimpfen, Duplikate haben auch andere 😉
Ich habe die API bisher noch nicht ausprobiert, dafür ist (leider nicht unüblich) ein eigener Zugriffsschlüssel zu beantragen. Wenn ich mir so die API-Dokumentation anschaue, fehlt anscheinend bisher die Metadaten-Volltextsuche – ich hoffe, das kommt noch, denn auf diese Weise könnte automatisch nach einer gegebenen DOI, ISBN etc. gesucht und in Katalogen dynamisch eingeblendet werden, ob eine bestimmte Publikation schon in BibSonomy verzeichnet ist. Das Eintragen neuer Bookmarks und Referenzen aus Bibliothekskatalogen funktioniert ja schon – Voraussetzung dafür ist, dass der OPAC BibTeX exportieren kann.
Und der Fairness halber auch die Hinweise auf APIs einiger anderer Social Bookmarking und Cataloging-Dienste:Connotea API, CiteULike hat noch keine API, LibraryThing in Ansätzen (und es gibt Datenbankauszüge zum Download!), Del.icio.us API, Mister Wong hat keine API, Digg hat eine…
Und dann bin ich bei der Recherche noch auf den tollen Backlink-Service Xinureturns.com gestoßen, die Nutzen wahrscheinlich statt APIs eher eigene Scraper, die Informationen aus HTML-Seiten extrahieren – das geht natürlich auch immer, ist aber meist aufwändiger und fehleranfälliger.
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare