VZG tritt mit Shibboleth DFN-Föderation bei
11. Januar 2008 um 14:22 Keine Kommentare
Seit Weihnachten ist die VZG offiziell Mitglied der DFN-Föderation zu Shibboleth. Bei Shibboleth handelt es sich nicht um eine Rasse im Star-Trek-Universum (so wie die Ferengi, Borg oder Vulkanier), sondern um ein Verfahren für eine „Authentifizierungs- und Autorisierungs-Infrastruktur“ (AAI). Das Identity-Management mit Shibboleth ist vergleichbar mit OpenID, geht aber darüber hinaus. Geregelt werden vor allem nicht nur technische, sondern auch organisatorische Belange. Während bei OpenID hinter jeder Identität letzendlich nur eine URL steht, stellt die DFN-Föderation sicher, dass hinter den verwalteten Identitäten tatsächliche Personen stehen. Die Mitglieder der Föderation garantieren als „Identity-Provider“ die Authentizität und Aktualität ihrer Nutzerdaten und einigen sich auf eine Menge von Attributen wie Nachname, Heimatorganisation, Art der Zugehörigkeit und Berechtigungen. Diese Attribute können beim Single-Sign-On an einen „Service-Provider“ weitergegeben werden – wobei der Datenschutz hohe Priorität hat. In der Regel wird nicht einmal der Name, sondern nur die Zugehörigkeit und/oder Berechtigung übertragen. Der Anbieter eines Dienstes bekommt vom Identity-Provider also lediglich die Information, dass sich eine Person erfolgreich authentifiziert hat und ihr Identity-Provider eine bestimmte Berechtigung garantiert. Die VZG ist im Rahmen der DFN-Föderation sowohl Identity-Provider (für Einzelnutzer von Nationallizenzen) als auch Service-Provider (mit einem Proxy zum Zugriff auf Nationallizenz-Angebote). In Zukunft sollen weitere Universitäten als Identity-Provider und weitere Verlage direkt als Service-Provider auftreten. Weitere Informationen zu Shibboleth – bspw. Hilfen zur Installation und Konfiguration gibt es auf den Seiten zum Projekt AAR an der Uni Freiburg.
Von Göttinger Tier-Feeds und Hannoveraner Bibliotheks-Mashups
6. Dezember 2007 um 17:32 1 KommentarWährend der soeben beendeten, zweiten VZG-Fortbildung zu RSS, Feeds und Content Syndication (die Folien sind schon mal bei Slideshare) wollte ich bei Feedblendr zur Demonstration einen aggregierten Feed zur Stadt Göttingen zusammenstellen. Als erster Treffer bei Google Blogsearch kam dazu zufälligerweise eine Mitteilung über die in Hamm, Oldenburg und Göttingen verfügbare Onleihe (von der Göttinger Stadtbücherei hatte ich dazu schon gestern eine Mail bekommen). Zu den weiteren Entdeckungen gehört, das Göttinger „Tierheim 2.0„, wo Hunde, Katzen und Kleintiere per RSS-Feed abonniert werden können: „Feed the animals„!
Bei einer Google-Suche nach der (leider etwas schwer auffindbaren) Seite der Bibliothek im Kurt-Schwitters-Forum Hannover bin ich dann auf das Weblog Bibliotheken in Hannover gestoßen, in dem Christian Hauschke und Manfred Nowak vom Workshop „Social Software in hannoverschen Bibliotheken“ berichten. Christians Ausführungen zu Lageplänen mit Google Maps (einen Lageplan in Google Maps einzuzeichnen, dauert auch ohne Vorkenntnisse höchstens zwanzig Minuten) möchte ich um eine Mashup-Idee ergänzen, die ich bereits neulich in meiner Lehrveranstaltung vorgestellt habe: Mit dem Perl-Modul PICA::Record lässt sich der Gesamtkatalog Hannover über SRU nach Bestandsdaten durchsuchen – dazu ist lediglich in diesem Beispielskript die Datenbank 2.92 statt 2.1 auszuwählen. Die so ermittelten Bibliotheken können dann mit etwas Bastelei in Google Maps angezeigt werden. Statt oder neben einer Liste der Bestandsnachweise wird dann zu einem Titel geografisch angezeigt, in welcher Bibliothek das Buch vorhanden ist. Mit Zugriff auf die Exemplardaten in den einzelnen OPACs könnte sogar noch angezeigt werden, ob ausleihbare Exemplare gerade vorhanden sind – wie das im Ansatz geht, steht in diesen Folien.
Linking to Wikipedia via ISBN
5. Dezember 2007 um 19:52 2 KommentareTwo weeks ago I announced a new beta webservice for linking from title data to German Wikipedia articles that cite a given work by ISBN. Now Lambert pointed me to a message by Eric Hellmann about xISBN supporting links to the English Wikipedia since last week. This makes GBV one week earlier then OCLC and both of us ten month later then LibraryThing. The idea is not new but based on the work of Lars Aronsson, Spiritus rector of future library systems.
The three services have been developed partly parallel based on some same code. Here are two examples of the xISBN service by Xiaoming Liu and the GBV service that I am developing. xISBN is based on a powerfull API with many query parameters and planned to be part of WorldCat Grid Services (more about this maybe here, here, here, and here), while my service is based on a simple API called SeeAlso which is based on OpenSearch Suggestions and unAPI. Both approaches have their pros and cons. I will provide more information as soon as our server is more stable and the scripts are clean enough to get published at CPAN. Meanwhile I encourage everyone to play with OCLC’s xISBN (via an API of its own), WorldCat Idenities (via SRU), LibraryThing for Libraries (via an API of its own), available catalouges (via Z39.50, via SRU and via other APIs), the Wikipedia Query API, and the growing number of other services. Let’s mash up the library systems for the future!
Verweise auf passende Rezensionen
5. Dezember 2007 um 16:35 4 KommentareNachdem ich in einer Fortbildung (siehe slides) am Rande die Realisierung von Links auf Wikipedia mittels des SeeAlso-Protokolls vorgestellt habe, kam von einer Teilnehmerin die Idee, auf die selbe Weise auf Rezensionen zu verweisen. Neben Amazon (wo Rezensionen manipuliert werden) und LibraryThing gibt es eine Vielzahl von Rezensionsdiensten von Fachreferenten und Wissenschaftlern. Leider bekommt dies außerhalb enger Fachcommunities kein Schwein mit, da Rezensionen weder systematisch erschlossen werden, noch praktikabel recherchierbar sind – dies gilt anscheinend auch für Rezensionen in Zeitungen, z.B. bei der ZEIT. Die Idee, über einen Linkserver Verweise auf passende Rezensionen zu liefern, finde ich wunderbar, weshalb ich gleich mal ein Konzept erstellt habe. Hier nur das Diagram, ausführlich im GBV-Wiki:
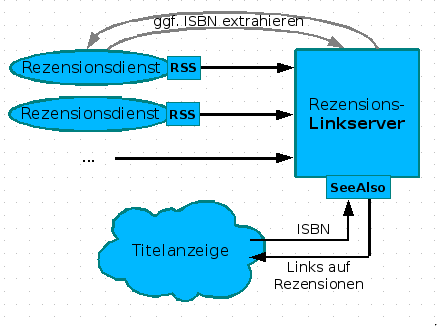
Leider hinken die meisten Rezensionsdienste dem Stand der Technik hinterher und bieten keine (oder kaputte) Feeds an. Wollen die nicht gelesen werden? Nun ja, vielleicht wachen Sie noch auf. Kennt jemand weitere Rezensionsdienste mit benutzbaren Feeds? So lange nicht genügend Rezensionsdienste verfügbar sind, ist der skizzierte Linkserver den Aufwand nicht wert, aber das kann ja noch kommen. Bitte mehr solcher Ideen! Wer nicht weiß, was Feeds sind und sich nicht vorstellen kann, wie ein Linkserver funktioniert, oder den Unterschied zwischen Indexbasierter und Metasuchmaschine nicht einigermaßen verinnerlicht hat, wird auch nicht auf die Ideen kommen, die notwendig sind, damit Bibliotheken nicht in der Bedeutungslosigkeit verschwinden. Deshalb sind Fortbildung und genügend freie Zeit zum Experimentieren so wichtig – zum Beispiel mit diesen Web 2.0-Diensten!
P.S: Neben Rezensionen und Lins auf Wikipedia können auch andere Informationen zu einem Werk von Interesse sein, z.B. Zusammenfassungen, Erwähnungen in Blogs etc.
GBV verlinkt auf Wikipedia mit SeeAlso-Linkserver
14. November 2007 um 17:17 8 KommentareDa es anscheinend bisher niemand in der Biblioblogosphere gemerkt hat und da ich es gerade auf dem Sun-Summit in Frankfurt vorgestellt habe, möchte ich hiermit auf einen neuen Webservice des GBV hinweisen: Mit SeeAlso werden seit Ende letzter Woche dynamisch im GBV-Katalog Links auf Wikipedia-Artikel eingeblendet, in deren Literaturangaben ISBN-Nummern enthalten sind: hier ein Beispiel. Das ganze läuft zunächst als Beta-Test und daher noch etwas langsam – dafür können die Linkserver hier ausprobiert werden; unter Anderem gibt es auch Links auf LibraryThing und VD17. Ideen für weitere Linkserver nach dem SeeAlso–Prinzip sind herzlich willkommen. Sobald die Server-Software als Open Source publiziert wird, können auch andere Einrichtungen eigene Linkserver anbieten. Die Einbindung in eigene Anwendung (vor allem Kataloge) funktioniert schon jetzt – happy mashuping!
GBV bietet COinS an
1. November 2007 um 16:12 3 KommentareWie ich eben in INETBIB schrieb, beginnt der GBV jetzt damit, für seine Kataloge COinS anzubieten. Damit können bibliographische Metadaten einfach aus dem Katalog in eigene Anwendungen übernommen werden. Zu den populären Anwendungen zur Literaturverwaltung gehört das Firefox-Plugin Zotero, welches soeben ein Jahr alt georden und in der Version 1.0 herausgekommen ist. Wie Zotero zusammen mit anderen Social-Software-Werkzeugen und dem Firefox-Abkömmling Flock in eine hocheffizienten Arbeitsplatz integriert werden kann, zeigt dieses Video. Eine anderes Bibliographiewerkzeug, dass COinS unterstützen soll ist Citavi.
Wie Patrick bemerkte ist es bereits seit Anfang August möglich, mit Zotero Daten aus dem GBV zu übernehmen. Dazu hatte der Zotero-Entwickler Ramesh Srigiriraju einen „Scraper“ in JavaScript geschrieben, der das RIS-Format interpretieren kann, welches von der PSI-Katalogsoftware mit dem Parameter PRS=RIS exportiert wird – wer genauer sehen möchte, wie so etwas funktioniert, sollte im Quelltext nach „GSO“ suchen.
Das Angebot von Daten via COinS ist wesentlich leichter nutzbar – sucht im im GSO-Katalog einfach mal nach einem Titel und schaut dann im HTML-Quelltext nach der Zeichenkette „Z3988“. Damit das Angebot auch in lokalen OPACs nutzbar ist, sollten meiner Meinung nach die einzelnen GBV-Bibliotheken erstmal selber Zotero ausprobieren und überlegen, wie sie das Angebot ihren Benutzern am Besten bekannt machen können.
Für die ganz harten Bibliothekshacker hier ein Stück Perl, um COinS für eigene Anwendungen aus beliebigen Webseiten auszulesen:
use HTML::TreeBuilder::XPath;
use LWP::UserAgent;
use URI::OpenURL;
use URI;
my $url = URI->new(shift @ARGV) or die "Please specify an URL!";
my $ua = LWP::UserAgent->new();
my $res = $ua->get($url);
my $html = $res->decoded_content;
my $tree= HTML::TreeBuilder::XPath->new_from_content( $html );
my @coins = $tree->findnodes( '//span[@class="Z3988"]/@title');
@coins = map { URI::OpenURL->new("?" . $_->getValue() ); } (@coins);
foreach my $c (@coins) {
print $c->canonical->dump() . "\n";
}
GBV-Verbunddaten weiterverarbeiten mit SRU-Schnittstelle und Perl
20. August 2007 um 14:58 2 KommentareEnde Juli habe ich im Rahmen meiner Arbeit bei der VZG mit PICA::Record eine Perl-API zur Verarbeitung von PICA+-Daten veröffentlicht. PICA+ ist das interne Katalogformat von PICA-Bibliothekssystemen, die neben dem GBV und den Verbünden HeBIS und SWB auch bei der Deutschen Nationalbibliothek und für Zentralsysteme in den Niederlanden, Australien, Frankreich und England eingesetzt werden. Inzwischen ist PICA übrigens eine vollständige OCLC-Tochterfirma. Mehr zum PICA+ Format findet sich in den jeweiligen Katalogisierungsrichtlinien, zum Beispiel beim GBV und in dieser kurzen Einführung.
PICA::Record ist sozusagen ein Pendant zu Mike Rylanders CPAN-Modul MARC::Record, das bereits seit einigen Jahren bei MARC-Anwendern genutzt und in der Mailingliste perl4lib diskutiert wird. Feedback in Form von Anwendungen, Ideen, Bugreports etc. ist sehr willkommen – zum Beispiel öffentlich bei der Dokumentation im GBV-Wiki. Neben der Erzeugung von Datensätzen in PICA+, um diese in Katalogsysteme einzuspielen, eignet sich PICA::Record auch für die umgekehrte Richtung. Dazu ist ein einfacher SRU-Client implementiert; die entsprechende SRU-Schnittstelle bietet der GBV seit einiger Zeit inoffiziell und nun auch öffentlich an. Für Bibliotheks-Mashups ist die SRU-Schnittstelle ein Baustein und die Perl-API ein mögliches Bindemittel. Natürlich kann der Webservice auch mit anderen Methoden als mit Perl abgefragt werden.
Beispiele und Anleitungen gibt es unter Anderem in der API-Dokumentation, im Quelltext oder hier.
Tagging, Umfrage, Buch, Vortrag
12. Juli 2007 um 00:22 4 KommentareDrei kleine Hinweise zum Thema Tagging:
1. Tobias Kowatsch führt für seine Abschlussarbeit eine Web-Experiment-Umfrage zum Thema Tagging durch. Die Auswahl fand ich teilweise etwas komisch aber ich bin ja nur Versuchsperson, also nehmt euch die 13 Minuten und probiert es selber aus!
2. Sascha Carlin hat ein Buch über Social Tagging geschrieben, das vermutlich auf seiner Diplomarbeit basiert. Ich bin gespannt und werde es nach Erscheinen mal genauer unter die Lupe nehmen.
3. Auf der GBV Verbundkonferenz im September werde ich unter anderem über Social Tagging und Bibliotheken und die konkreten Planungen zur Tagging-Unterstützung im GBV referieren.
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare