Verweise auf passende Rezensionen
5. Dezember 2007 um 16:35 4 KommentareNachdem ich in einer Fortbildung (siehe slides) am Rande die Realisierung von Links auf Wikipedia mittels des SeeAlso-Protokolls vorgestellt habe, kam von einer Teilnehmerin die Idee, auf die selbe Weise auf Rezensionen zu verweisen. Neben Amazon (wo Rezensionen manipuliert werden) und LibraryThing gibt es eine Vielzahl von Rezensionsdiensten von Fachreferenten und Wissenschaftlern. Leider bekommt dies außerhalb enger Fachcommunities kein Schwein mit, da Rezensionen weder systematisch erschlossen werden, noch praktikabel recherchierbar sind – dies gilt anscheinend auch für Rezensionen in Zeitungen, z.B. bei der ZEIT. Die Idee, über einen Linkserver Verweise auf passende Rezensionen zu liefern, finde ich wunderbar, weshalb ich gleich mal ein Konzept erstellt habe. Hier nur das Diagram, ausführlich im GBV-Wiki:
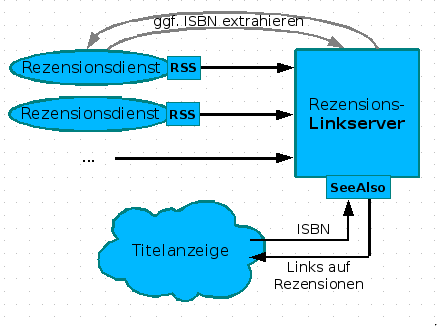
Leider hinken die meisten Rezensionsdienste dem Stand der Technik hinterher und bieten keine (oder kaputte) Feeds an. Wollen die nicht gelesen werden? Nun ja, vielleicht wachen Sie noch auf. Kennt jemand weitere Rezensionsdienste mit benutzbaren Feeds? So lange nicht genügend Rezensionsdienste verfügbar sind, ist der skizzierte Linkserver den Aufwand nicht wert, aber das kann ja noch kommen. Bitte mehr solcher Ideen! Wer nicht weiß, was Feeds sind und sich nicht vorstellen kann, wie ein Linkserver funktioniert, oder den Unterschied zwischen Indexbasierter und Metasuchmaschine nicht einigermaßen verinnerlicht hat, wird auch nicht auf die Ideen kommen, die notwendig sind, damit Bibliotheken nicht in der Bedeutungslosigkeit verschwinden. Deshalb sind Fortbildung und genügend freie Zeit zum Experimentieren so wichtig – zum Beispiel mit diesen Web 2.0-Diensten!
P.S: Neben Rezensionen und Lins auf Wikipedia können auch andere Informationen zu einem Werk von Interesse sein, z.B. Zusammenfassungen, Erwähnungen in Blogs etc.
Social Cataloging in Wikipedia
5. Dezember 2007 um 01:19 Keine KommentareLast week I gave an introduction into social tagging and cataloging for librarians (some German slides here at Slideshare). In a discussion on German Wikipedia about COinS I was pointed to the French Wikipedia: They have a special namespace référence to store more detailled bibliographic information (see MediaWiki-namespaces in general), some more information is collected in Projet:Références, but my French is too little to find out much. This example may demonstrate the concept:
The article „Première période intermédiaire égyptienne“ cites the source „Nicolas Grimal, Histoire de l’Égypte ancienne, 1988“. The citation provides a link to on a special page that lists several editions of the work. Actually this is another implementation of FRBR.
I like the idea of seggregating full bibliographic record and reference in the Wikipedia article, but the concrete solution is too complicated and limited. Wikipedia with flat text is just not the right tool to store bibliographic data. Maybe Semantic MediaWiki can help, but a multilingual approach like LibraryThing does is better. French Wikipedians should not have to duplicate cataloging efforts, but just point to LibraryThing, WorldCat or whatever bibliographic authority is usable. By the way most library catalouges are not usable in this sense – on the Web noone cares how good you data is if you cannot directly link to it and use it in other context.
Wikipedia-Wortschatz-Analyse aktualisiert
3. Dezember 2007 um 00:55 Keine KommentareWie Matthias Richter mitteilt, hat er die Wikipedia-Datenbasis im Deutschen Wortschatz-Portal aktualisiert. Neben statistisch signifikant häufig in einem Satz vorkommenden Wörtern, wird unter http://wortschatz.uni-leipzig.de/WP/ nun auch die Linkstruktur zwischen den Artikel analysiert. Siehe da: Internet wird signifikant häufiger zusammen mit Bibliothek verlinkt – noch häufiger aber sind Archiv und Museum. Ich schließe daraus unwissenschaftlicherweise, dass noch nicht ausgemacht ist, ob Bibliotheken irgendwann nur noch Archive und Museen sein werden oder im Internet auch in Zukunft für die Informationsversorgung relevant sein werden 😉

Weblog-Kurse im Kommen
15. November 2007 um 12:48 3 KommentareBald bloggt jeder Bibliothekar. Während ich in Göttingen einen Workshop gebe, scheint gleichzeitig Lambert in Berlin ebenfalls fortzubilden. 🙂 Hoffentlich schaltet er schnell mal unsere Kommentare frei.
GBV verlinkt auf Wikipedia mit SeeAlso-Linkserver
14. November 2007 um 17:17 8 KommentareDa es anscheinend bisher niemand in der Biblioblogosphere gemerkt hat und da ich es gerade auf dem Sun-Summit in Frankfurt vorgestellt habe, möchte ich hiermit auf einen neuen Webservice des GBV hinweisen: Mit SeeAlso werden seit Ende letzter Woche dynamisch im GBV-Katalog Links auf Wikipedia-Artikel eingeblendet, in deren Literaturangaben ISBN-Nummern enthalten sind: hier ein Beispiel. Das ganze läuft zunächst als Beta-Test und daher noch etwas langsam – dafür können die Linkserver hier ausprobiert werden; unter Anderem gibt es auch Links auf LibraryThing und VD17. Ideen für weitere Linkserver nach dem SeeAlso–Prinzip sind herzlich willkommen. Sobald die Server-Software als Open Source publiziert wird, können auch andere Einrichtungen eigene Linkserver anbieten. Die Einbindung in eigene Anwendung (vor allem Kataloge) funktioniert schon jetzt – happy mashuping!
Was ist eigentlich Shibboleth?
8. November 2007 um 15:59 4 KommentareShibboleth wird zunehmend in Bibliotheken eingesetzt, so dass zum Beispiel Nutzer mit ihren normalen Account von Überall auf Nationallizenzen zugreifen können. Die TU-Chemnitz verwendet sogar Shibboleth für alle ihre Dienste (Gruß an ronsc). Jenni Krueger hat eine kurze Einführung erstellt, die zum Einsteig in die Materie ganz hilfreich ist. Zusätzliche Quellen gibt es dazu bei bibsonomy. Zum Vergleich von OpenID und Shibboleth habe ich auch nicht viel gefunden, dieser Vortrag von Leigh Dodds ist ganz nett (auch mit weiteren Quellen). Relevant wird vielleicht in Zukunft vielleicht noch OAuth.
Shibboleth ist ein Projekt des Internet2-Konsortiums und eine Open Source Anwendung zur Authentifizierung und Autorisierung für webbasierte Anwendungen und Services, die auf dem SAML-Standard basiert. Die Grundidee von Shibboleth ist es, dass jeder Benutzer sich nur einmal bei seiner Heimateinrichtung identifizieren muss, um die Dienste verschiedener Anbieter ortsunabhängig nutzen zu können. Dieses Prinzip nennt man „Single Sign-On“. Dadurch wird das Problem vieler verschiedener Nutzernamen und Passwörter für unterschiedliche Services oder lizensierte Materialien gelöst und ihre Nutzung wesentlich vereinfacht.
Wenn ein Benutzer über eine beliebige Internetverbindung auf einen Service oder eine geschützte Quelle zugreifen möchte, dann muss zunächst geprüft werden, ob er schon authentifiziert ist. Wenn das nicht der Fall ist, leitet der Service-Provider den Nutzer an einen Lokalisierungsdienst weiter, der die Heimateinrichtung des Nutzers ermittelt. Dort muss sich der Benutzer beim Identity-Provider der Heimateinrichtung mit Nutzernamen und Passwort identifizieren. Nach erfolgreicher Identifikation wird der Nutzer zurück zum Anbieter geleitet. Wenn der Service-Provider noch weitere Informationen benötigt, kann er beim Identity-Provider bestimmt Rechte oder Zugehörigkeiten erfragen, um zu ermitteln, ob der Nutzer autorisiert ist.
Die Authentifizierungs- und Autorisierungsinformationen können während der Sitzung in einem Cookie gespeichert werden, dadurch ist dann die Möglichkeit des Single Sign-On gegeben und der Nutzer spart sich bei einem weiteren Serviceanbieter erneute Anmeldeschritte. Voraussetzung für dieses ganze System ist, dass die Heimateinrichtung eine Instanz des Identity-Providers betreibt und die Serviceanbieter der angefragten Quelle den Service-Provider von Shibboleth betreiben.
Angestrebt ist ein flächendeckender und vielleicht sogar europaweit einheitlicher Einsatz von Shibboleth. Ab einer gewissen Größe des Einsatzgebietes übernimmt eine sogenannte Föderation die Organisation. Die Föderation soll alle Identity-Provider und Service-Provider in einer Dachorganisation vereinen und alle Standards des Verfahrens einheitlich für alle Mitglieder regeln. Außerdem soll sie den Lokalisierungsdienst für alle Mitglieder betreiben. In Deutschland wurde eine solche Föderation (DFN-AAI) vom Deutschen Forschungsnetz (DFN) in Zusammenarbeit mit der Universität Freiburg gegründet und auch in anderen Ländern gibt es schon Föderationen zur Leitung des Einsatzes von Shibboleth:DK-AAI (Dänemark), HAKA (Finnland), CRU (Frankreich), UKFederation (Großbritannien), SWITCH (Schweiz).
Die Unterschiede zu anderen Programmen wie OpenID (ähnlich wie Shibboleth, aber Konzept der URL-basierten Identität, eher für Unternehmen) und LDAP („Leihtweight Directory Access Protocol“, Einsatz bei Verzeichnisdiensten, Client/Server-Modell, Informationen auf Abfrage) liegt unter anderem darin, dass der Zugriff auf eine zugriffsgeschützte Quelle nicht mehr an einen Rechner gebunden ist, sondern an die Person, die auf die Quelle zugreifen möchte. Nutzer erhalten eine elektronische Identität mit Attributen, die die Grundlage für die Autorisierung und Zugriffskontrolle mit Shibboleth bilden. Shibboleth soll durch die stärkere Trennung von Personendaten und Services den bisherigen IP-Nummern-basierten Zugriff möglichst ganz ersetzen und ein organisationsübergreifendes Identity-Management schaffen.
Shibboleth wird bereits in verschiedenen Bereichen eingesetzt, vor allem in der Wissenschaft und Lehre, denn an vielen Bibliotheken oder Universitäten gibt es mittlerweile eine Vielzahl an elektronischen Diensten, Angeboten und lizensierten Materialen, für die eine komfortable und zugleich sichere Zugangsverwaltung und –kontrolle notwendig ist. In Deutschland beteiligen sich beispielsweise: Uni Freiburg, Uni Regensburg, Vascoda, das FIZ-Technik, Genios, der GBV und Springer. Auf der offiziellen Website gibt es eine relativ lange Liste von Anwendungen und Services, in denen Shibboleth integriert ist oder gerade integriert wird, zum Beispiel EBSCO Publishing, ExLibris, OCLC, Moodle und Napster. Außerdem findet man auf der gleichen Seite die Links zu den Föderationen im Ausland.
Karten im Netz
7. November 2007 um 18:11 6 KommentareGoogle Maps kennt inzwischen jeder, aber was gibt es darüber hinaus und wie stellen Bibliotheken ihre Karten im Netz dar? Die folgende Ausarbeitung von Tatjana Frolow zeigt, dass hier noch viel Entwicklungspotential besteht. Weitere Quellen zum Thema gibt es in der Literaturliste.
Die Entwicklung des Internets und der allgemeine Fortschritt der Informations- und Kommunikationstechnologie treiben die Nachfrage nach geokodierten Daten an und machen die neuen Karten zu einem Werbemedium der Zukunft. Beispiele für Karten in Netzen sind Map24, Google Maps , Yahoo Maps , ViaMichelin und viele andere. Ähnlich bei allen Anbietern ist die Oberfläche, die eine Adresssuche, einen Routenplaner die elektronische Karte selbst und ggf. standardbezogene Informationen (Hotels usw.) zur Verfügung stellt. Die Landkarten werden meistens in den drei Ansichten der reinen Straßenkarte, der Satellitenansicht und der Hybridansicht, einer Komination aus reiner Straßenkarte und Satellitenansicht, präsentiert. Trotz vieler Gemeinsamkeiten gibt es jedoch auch Unterschiede nicht nur in den Funktionen, sondern vor allem auch in der Qualität. So bietet ViaMichelin z.B. nur die Ansicht einer reinen Straßenkarte , Yahoo Maps lässt bei der Satellitenansicht nicht nah genug ranzoomen und Map24 beschreibt die Route in ganzen Sätzen, andere Anbieter nur stichwortartig. Eine besondere Funktion bei Google Maps ermöglicht es die Route mit der Maus per Drag and Drop zu verändern. Automatisch ändert sich dadurch auch der Beschreibungstext zur Route samt Kilometerzahl und Fahrtdauer. Eine Änderung der Route ist bei der Konkurrenz nur via Eingabemaske möglich. Google Maps und Map24 sind sowohl von der Schnelligkeit, als auch von der Grafik qualitativ am besten. Beide basieren auf Vektorgrafiken, (Computerbilder aus Kreisen, Linien und Polygonen), und liefern somit realistischere Ergebnisse als bei der Pixelgrafik. Das zu übertragende Datenvolumen ist geringer, das Laden der Karten schneller und das Zoomen flüssiger.
Neu im Kartenbusiness ist das Interaktive Mapping, dass jedem Nutzer ermöglicht seine eigene Karte zu entwerfen, eigene Informationen einzusetzen, zu speichern und anderen zur Verfügung stellen. Karteninformationen können also mit eigenen Informationen verknüpft werden. Einen Boom erlebte diese Bewegung mit Google Maps: In den USA gibt es bereits die unterschiedlichsten Google Maps-Mashups, wie z.B. den Ride Finder, mit dem Taxis und Shuttles in Echtzeit lokalisiert werden können und man mit einem Klick auf das Taxisymbol die Nummer des Transportunternehmens erhält. Ein weiteres Beispiel sind die Housing Maps. Dabei gibt man in die Suchmaske den gewünschten Ort und den Betrag ein, den man für die monatliche Miete aufbringen möchte und findet freie Wohnungen und Häuser aus dem Immobilenkatalog Craigslist.
Trotz der Landkartenbewegung im Internet sollte nicht vergessen werden, dass auch Bibliotheken Karten besitzen, die sich über Bibliothekskataloge, Verbundkataloge, wie z.B. GBV oder im Katalog der Deutschen Nationalbibliothek recherchieren und bestellen lassen. Zwar liegen diese vorwiegend nur im Papierformat vor, jedoch bieten Bibliotheken im Vergleich zu Google Maps und Co. neben geographischen auch historische und thematische Karten jeglicher Art an, wie z.B. Artenschutzkarten u. ä. Die Staats- und Unibibliothek Göttingen sammelt im Rahmen des Sondersammelgebietplans der DFG thematische, geographische, geologische und meteorologische Karten und ist damit gute Anlaufstelle bei der Kartenrecherche. Mittlerweile haben auch die Biblioteheken die Nachfrage der Benutzer erkannt schnell und unkompliziert auf Medien zugreifen zu können. Das Göttinger Digitalisierungszentrum z.B. digitalisiert analoge Medien und macht sie im Internet verfügbar. Allerdings befinden sich in der digitalen Bibliothek zur Zeit nur 13 Landkarten. Auch die Staats- und Unibibliothek Bremen stellt online eine elektronische Bibliothek bereit, aber auch hier ist die Anzahl der Karten eher gering.
Abschließend lässt sich sagen, dass der Trend eindeutig in Richtung 3D/Virtual Reality-Karten und Mashups geht und dass Bibliotheken meiner persönlichen Einschätzung nach intensiver mitziehen müssen, um weiterhin als wichtiger Informationsdienstleister zu funktionieren.
P.S: Ein schönes Mashup zur Suche nach historischen Bildern ist HistoGrafica [via Nando]
Library Software Manifesto
7. November 2007 um 11:23 Keine KommentareAuf CODE4LIB, einer Mailingliste für Programmierung im Bibliotheks- und Informationsbereich, hat Roy Tennant den Entwurf eines „Library Software Manifesto“ veröffentlicht:
Consumer Rights:
– I have a right to use what I buy
– I have a right to the API if I’ve bought the product
– I have a right to accurate, complete documentation
– I have a right to my data
– I have a right to not have simple things needlessly complicatedConsumer Responsibilities:
– I have a responsibility to communicate my needs clearly and specifically
– I have a responsibility to report reproducible bugs in a way as to
facilitate reproducing it
– I have a responsibility to report irreproducible bugs with as much detail
as I can provide
– I have a responsibility to request new features responsibly
– I have a responsibility to view any adjustments to default settings
critically
Bemerkenswert ist, dass sowohl „Consumer Rights“ als auch „Consumer Responsibilities“ aufgeführt werden. Letztere werden aus Entwicklersicht momentan sogar stärker diskutiert. Aus meiner eigenen Erfahrung kann ich bestätigen, dass in Bibliotheken Software noch immer zu oft passiv als fertiges Produkt verstanden wird, anstatt als Werkzeugkasten, mit dem man sich auseinandersetzen muss.
Meine Lehrveranstaltung „Digitale Bibliothek“
6. November 2007 um 03:03 3 KommentareMeine erste Lehrveranstaltung als Hochschuldozent hat inzwischen praktisch schon die Halbzeit erreicht und es liegen erste Ergebnisse vor, so dass ich mich traue, auch an dieser Stelle darauf hinzuweisen. Im Wintersemester 2007/2008 lehre ich an der Fachhochschule Hannover im Bachelor-Studiengang Informationsmanagement das Modul „Digitale Bibliothek“. Hier der Semesterplan:
01.10.07 Grundlagen des WWW
08.10.07 Weblogs, RSS & Syndication
15.10.07 JavaScript und Mashup-Programmierung
22.10.07 Kommunikationsformen und Communities
29.10.07 Grundformen Digitaler Bibliotheken
05.11.07 Grundlagen Datenformate und Standards
19.11.07 Schnittstellen und Webservices
26.11.07 Webservices und Datenformate
03.12.07 Tagging und Social Cataloging
10.12.07 Semantic Web und Identifikatoren
17.12.07 Semantic Web II: FRBR & Co
07.01.08 Zusammenfassung und Zukunftsprognosen
Die hier verlinkten Vortragsfolien, die jeweils als Gerüst und Erinnerungshilfe dienen, habe ich bei Slideshare online gestellt und mit dem Tag fhhdb07 versehen. Für die Sklavenarbeit Leistungsnachweise musste konnte ich mir selber etwas ausdenken:
Gefordert ist ein 10-Minütiger Vortrag in freier Rede (ggf. mit Tafel) zu einem vorgegebenem Thema. Zusätzlich muss innerhalb von einer Woche eine kurze Ausarbeitung (etwa eine Seite) als Hypertext (BTW: Moodle sucks) und eine kommentierte Quellenliste in maschinenlesbarem Format abgegeben werden. Für die Quellen hat sich Bibsonomy durchgesetzt, im Idealfall sieht das dann zum Beispiel so aus.
Damit nicht nur meine wissensdurstigen Studenten (und zukünftigen Kollegen!) etwas von ihren Ausführungen haben, werde ich als Gastbeitrag einige Beispiele von Ausarbeitungen veröffentlichen. Bis jetzt bin ich (trotz der ausufernden Vor- und Nachbereitungs- sowie Fahrzeit) zufrieden mit der Veranstaltung. Vielleicht werden es das nächste Mal (falls es das gibt) gleich Wikipedia-Artikel statt einer Hausarbeit, mal schauen.
GBV bietet COinS an
1. November 2007 um 16:12 3 KommentareWie ich eben in INETBIB schrieb, beginnt der GBV jetzt damit, für seine Kataloge COinS anzubieten. Damit können bibliographische Metadaten einfach aus dem Katalog in eigene Anwendungen übernommen werden. Zu den populären Anwendungen zur Literaturverwaltung gehört das Firefox-Plugin Zotero, welches soeben ein Jahr alt georden und in der Version 1.0 herausgekommen ist. Wie Zotero zusammen mit anderen Social-Software-Werkzeugen und dem Firefox-Abkömmling Flock in eine hocheffizienten Arbeitsplatz integriert werden kann, zeigt dieses Video. Eine anderes Bibliographiewerkzeug, dass COinS unterstützen soll ist Citavi.
Wie Patrick bemerkte ist es bereits seit Anfang August möglich, mit Zotero Daten aus dem GBV zu übernehmen. Dazu hatte der Zotero-Entwickler Ramesh Srigiriraju einen „Scraper“ in JavaScript geschrieben, der das RIS-Format interpretieren kann, welches von der PSI-Katalogsoftware mit dem Parameter PRS=RIS exportiert wird – wer genauer sehen möchte, wie so etwas funktioniert, sollte im Quelltext nach „GSO“ suchen.
Das Angebot von Daten via COinS ist wesentlich leichter nutzbar – sucht im im GSO-Katalog einfach mal nach einem Titel und schaut dann im HTML-Quelltext nach der Zeichenkette „Z3988“. Damit das Angebot auch in lokalen OPACs nutzbar ist, sollten meiner Meinung nach die einzelnen GBV-Bibliotheken erstmal selber Zotero ausprobieren und überlegen, wie sie das Angebot ihren Benutzern am Besten bekannt machen können.
Für die ganz harten Bibliothekshacker hier ein Stück Perl, um COinS für eigene Anwendungen aus beliebigen Webseiten auszulesen:
use HTML::TreeBuilder::XPath;
use LWP::UserAgent;
use URI::OpenURL;
use URI;
my $url = URI->new(shift @ARGV) or die "Please specify an URL!";
my $ua = LWP::UserAgent->new();
my $res = $ua->get($url);
my $html = $res->decoded_content;
my $tree= HTML::TreeBuilder::XPath->new_from_content( $html );
my @coins = $tree->findnodes( '//span[@class="Z3988"]/@title');
@coins = map { URI::OpenURL->new("?" . $_->getValue() ); } (@coins);
foreach my $c (@coins) {
print $c->canonical->dump() . "\n";
}
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare