Wer nichts weiß, muss alles glauben
26. November 2007 um 00:05 4 KommentareVor genau einem halben Jahr schrieb ich über das Verhältnis von Wikipedia und Titanic-Magzin. Mit dem aktuellen Dezember-Heft (Nr. 338) ist auf Seite 40/41 eine doppelseitige Wikipedia-Anzeige hinzugekommen – ich weiß nicht, was sowas normal kosten würde, in jedem Fall Danke für die Sachspende! Abgebildet ist das historische Händehalten von Mitterrand und Kohl am 11. November 1984 in Verdun (mit dem auch schon ein Schwulen-Sender Werbung gemacht hat) – nur dass statt Mitterand der Kopf des wunderbaren Louis de Funès einmontiert wurde. Unten rechts findet sich neben dem Wikipedia-Logo der Spruch „Wer nichts weiß, muss alles glauben“, der vermutlich von Marie von Ebner-Eschenbach (1830-1916) stammt, was ich einfach mal so glauben muss, obgleich Zitate besonders gerne falsch überliefert werden. Wer nichts weiß und/oder nicht selber recherchieren und Quellen einschätzen kann, muss halt alles glauben. Oder er glaubt nichts – das wird man ja wohl noch glauben dürfen (super-sicheres Originalzitat von Karl Valentin).
Noch interessanter finde ich in dieser Ausgabe den zweitiligen Artikel von Christian Meurer über die deutsche Figur Horst Mahler. Dessen Lebenslauf mit prominenten Stationen von RAF bis NPD und vielen illustren Zeitgenossen dürfte sich hervorragend dazu eignen, die Bundesdeutsche Geschichte der Nachkriegszeit darzustellen: Andreas Baade (gähn), Hans-Christian Ströbele (inzwischen ohne Mahler einziger direkt in den Bundestag gewählter Grüner), Otto-„BigBrother-Lifetime-Award“-Schily, Gerhard Schröder (Kennt den noch jemand? Ich muss mal in Moskau nachfragen!), Wolf Biermann (Musiker?), Georg Wilhelm Friedrich Hegel (doppelgähn), Günter Rohrmoser (der nicht zu den sympatischen Menschen gehört, die das Bundesverdienstkreuz abgelehnt haben), Erich-„Paolo Pinkas“-Friedmann etc. Bei so vielen lustigen Deutschen könnte doch mal ein „Schlussstrich“ unter die ollen Adolf-Witze gezogen werden: die BRD übertrifft das 3. Reich auch an Witzfiguren und komischen Begebenheiten, also her mit der Mahler-Biografie.
Ergo: Titanic ist lehrreich und unterhaltsam, gerade aufgrund all der ernsthhaften Themen, die im Heft zu finden sind. Wahrscheinlich ist guter Humor sowieso nur zu ernsthaften Themen möglich. Macht es lieber nicht, wie die Universität der Bundeswehr, die der Zeitschriftendatenbank nach ihr seit dem Gründungsjahr (1979) laufendes Titanic-Abonnement 1991 einfach einstellte, während vorbildhaft die Bibliothek der Friedrich Ebert-Stiftung die Jahrgänge bis 2005 auf Mikrofilm bereithält. In diesem Sinne: Viel Spaß noch!
GBV verlinkt auf Wikipedia mit SeeAlso-Linkserver
14. November 2007 um 17:17 8 KommentareDa es anscheinend bisher niemand in der Biblioblogosphere gemerkt hat und da ich es gerade auf dem Sun-Summit in Frankfurt vorgestellt habe, möchte ich hiermit auf einen neuen Webservice des GBV hinweisen: Mit SeeAlso werden seit Ende letzter Woche dynamisch im GBV-Katalog Links auf Wikipedia-Artikel eingeblendet, in deren Literaturangaben ISBN-Nummern enthalten sind: hier ein Beispiel. Das ganze läuft zunächst als Beta-Test und daher noch etwas langsam – dafür können die Linkserver hier ausprobiert werden; unter Anderem gibt es auch Links auf LibraryThing und VD17. Ideen für weitere Linkserver nach dem SeeAlso–Prinzip sind herzlich willkommen. Sobald die Server-Software als Open Source publiziert wird, können auch andere Einrichtungen eigene Linkserver anbieten. Die Einbindung in eigene Anwendung (vor allem Kataloge) funktioniert schon jetzt – happy mashuping!
Neuigkeiten aus dem Wikipedia-Projekt
2. Oktober 2007 um 12:23 Keine KommentareSoeben ist der erste KIM-DINI-Technology-Watch-Report (ISSN 1865-3839) herausgekommen, in dem auf 35 Seiten aktuelle Entwicklungen aus dem Bereich Standards und Standardisierungender digitalen Informationsversorgung zusammengefasst werden. Ich habe einen Beitrag zu aktuellen Neuigkeiten aus dem Wikipedia-Projekt beigesteuert, den ich an dieser Stelle ebenfalls veröffentlichen möchte. Genannt werden Maßnahmen zur Qualitätssicherung und die Extraktion von Daten aus Wikipedia für das Semantic Web:
Beitrag Neuigkeiten aus dem Wikipedia-Projekt weiterlesen…
Quality studies at Wikimania2007
4. August 2007 um 05:38 Keine KommentareI just participated in a Wikimania 2007 session with two very smart talks about quality studies in Wikipedia. Both were examples of rare (but hopefully growing) number of scientific studies with knowledge of Wikipedia internals and relevance to the practical needs of Wikipedia. Last but not least they both include working implementations instead of ideas only.
First there is Using Natural Language Processing to determine the quality of Wikipedia articles by Brian Mingus, Trevor Pincock and Laura Rassbach. Brian, an undergraduate student at Colorado, presented a rating system that was trained by existing Quality assesments of Wikipedia articles and a large set of features that may possible be related to quality, mainly computed by methods of natural language processing. Machine classification could predict ratings very well. Brian believes (and convinced me) that the best approach to determining article quality is a combination of human ratings and machine classifications. Human ratings serve as training data and algorithms can reverse engineer the human ratings. You should not think that binary, top-down ratings like the upcoming stable versions done by expert are the definite solution – but they may be additional information to predict quality and to train automatic systems that reproduce and summarize quality ratings. I will publish links to Brian’s slides, paper and code as soon as I get them (we collect all slides). A preliminary paper is in the Wikimania Wiki.
In the second talk Luca De Alfaro presented A Content-Driven Reputation System for the Wikipedia. The basic idea of his clever algorithm to predict trustability of Wikipedia texts is that authors of long-lived contributions gain reputation and authors of reverted contributions lose reputation. The detection and rating of remaining, changed, and reverted contributions is similar to WikiBlame but much more elaborated. Based on the analysis of the whole English, Italian, and French Wikipedia paragraphs and words can be coloured: text that is likely to be trusted is white while text that better should be checked is more orange. See the demo and the paper presented at WWW2007 (slides will follow).
I hope that Wikipedians and local Wikimedia chapters will catch up these efforts to get the tools usable in practise, for instance at Wikimedia Toolserver. Wikipedians, developers, Wikimedia organizations, and scientists need to work together tightly to bring smart ideas in Wikipedia quality research to real applications.
Wikipedia-Verlinkung und Artikelstruktur als Mindmap
6. Juni 2007 um 12:22 Keine KommentareAls Such- und Navigationshilfe für Wikipedia wird momentan Wikimindmap in diversen Blogs angepriesen. Um sich einen ersten Überblick zu verschaffen, ist das Programm zur Darstellung der Wikipedia-Verlinkung und Artikelstruktur als Mindmap möglicherweise praktisch – so gut wie das leider nur für Mac verfügbare Pathway (siehe screenshot) ist es aber nicht und zum Suchen in Wikipedia sind Suchmaschinen wie Exalead, WikiSeek und Web.de besser geeignet. Noch besser lässt sich Wikipedia übrigens nutzen, indem man anstatt wild herumzuklicken und zu browsen, mal Artikel aufmerksam Satz für Satz liest, versucht die Aussagen vollständig zu verstehen und danach unklare, unvollständige oder unverständliche Stellen selber ergänzt, verbessert und/oder zusammenfasst. Da bleibt einiges mehr hängen als beim passiven Wikipedia-Genuss. [via Nordenham u.A.]
{kind=link}
Freie Geoinformationen in Wikipedia und OpenStreetMap
2. Juni 2007 um 15:11 3 KommentareAuf dem LinuxTag Berlin habe ich mich nach seinem Vortrag mit Ralf Zimmermann von OpenStreetMap (siehe Wikipedia-Artikel) unterhalten. Ziel des OpenStreetMap-Projekts ist es, gemeinsam eine „Freie Karte der Welt“ zu erstellen. Dazu sind seit 2004 mehr als 6500 Freiwillige mit GPS-Geräten unterwegs und kartieren die Erde.
Im Gegensatz zu kommerziellen Karten wie Google Maps sind die Daten von OpenStreetMap unter CC-BY-SA frei verwendbar. OpenStreetMap ist damit eine ideale Ergänzung zu Wikipedia, wo ebenfalls schon seit einiger Zeit Geodaten gesammelt werden (siehe WikiProjekt Georeferenzierung). Allerdings ist die MediaWiki-Software eher für Texte als für Geodaten angelegt, so dass die Möglichkeiten begrenzt sind – so können praktisch nur Punktkoordinaten gesammelt werden, während OpenStreetMaps erfolgreich Straßen, Flüsse, Küstenlinien etc. als Vektordaten bereitstellt.
In der englischsprachigen Ausgabe haben sich schon einige Wikipedianer mit Interesse an OpenStreetMap zusammengetan. In der deutschsprachigen Wikipedia gibt es zwar auch viele gute Geoprojekte wie beispielsweise der WikiMiniAtlas; durch eine Zusammenarbeit mit OpenStreetMap könnte die Qualität freier Geoinformationen allerdings deutlich verbessert und Doppelarbeit vermieden werden. Die Verbindung von Wikipedia und OpenStreetMaps sollte dabei durch Identifier statt auf Basis von Koordinaten geschehen: Jeder Wikipedia-Artikel mit geographischem Bezug kann so eindeutig mit dem entsprechenden Vektorobjekt in OpenStreetMap verbunden werden.
Ein Problem für die Zusammenarbeit ist leider die Inkompatibilität der GFDL-Lizenz der Wikipedia mit CC-BY-SA. Aus Urheberrechts- und Qualitätsgründen dürfen in OpenStreetMaps nur selbst-überprüfte Daten aufgenommen werden, das kopieren aus anderen Karten oder Wikipedia ist deshalb tabu. Hier lassen sich aber sicherlich Wege finden, z.B. indem Wikipedia-Autoren die von ihnen gesammelten Geokoordinaten unter CC-BY-SA doppelt lizensieren oder gleich als Public Domain freistellen.
Ich werde mich jedenfalls erstmal nach einen GPS-Empfänger umsehen; neben der Sammlung freier Geodaten kann man damit zum Beispiel auch Geocaching (Schatzsuche/Wandern) betreiben und Confluenzen besuchen.
Update: In England und Wales gibt es seit August 2006 die OpenStreetMap Foundation. OpenStreetMap ist meiner Meinung nach etwas paranoid, was die Lizenzfrage betrifft – es gibt viele freie Quellen wie zum Beispiel Satellitenbilder, aus denen sich Karten erstellen ließen, aber auf Basis eines US-militärischen Navigationssystems (GPS) von Laien Karten zu erstellen, macht anscheinend mehr Spaß. Weitere Informationen zu Geoinformatik gibt es im GIS Wiki, das auch die GFDL verwendet.
Wikipedia in der Titanic-Humorkritik – fast
26. Mai 2007 um 03:06 6 KommentareSeit einigen Jahren warte ich schon auf eine angemessene Auseinandersetzung der Titanic mit der Wikipedia (nicht umgekehrt!) – schließlich können bei beiden jeder „Hans“ und „Fritz“ (gerne auch „Oliver“, „Martin“ und „Thomas“) einfach so mitschreiben und im Besten Fall dem „Ausgang des Menschen aus seiner selbst verschuldeten Unmündigkeit“ behilflich sein. Nach einem albernen Vandalismus-Aufruf beim Titanic-Parasiten „Partner Titanic“ (gähn, Quatsch in Wikipedia-Artikel reinschreiben, wie originell…) hat es Wikipedia – wenn auch nur randthematisch – ins Herz der Satirezeitschrift geschafft. Unter der Überschrift „Über das Volksvermögen“ widmet sich Adorno Hans Mentz den Wikipedia-Ablegern Kamelopedia, Stupipedia und Uncyclopedia. Die Kamelopedia kommt dabei nicht so gut weg (während ich nicht nur wegen meiner Vorliebe fürs Dadaistische, schon vor allem wegen der Erfindung des Bevölkerungsdöner da nicht zustimmen kann), dafür wird Uncyclopedia empfohlen, weil „die Seite international ist und Beiträge in rund vierzig Sprachen enthält“ – wo findet man beispielsweise sonst wissenswertes zu Hitler in so vielen Sprachen?
Weniger offensichtlich ist, dass Wikipedia selbst eine Fülle von komischen Inhalten, Diskussionen und Begebenheiten bereithält, wie zum Beispiel das Best of OTRS oder meine (bislang erfolglosen) Versuche, den Begriff „Humorkritik“ vor einer Löschung zu bewahren. Hier die letzte Version aus meiner Feder, falls sich jemand traut, das Thema doch noch mal in Wikipedia zu behandeln, einfach kopieren:
Beitrag Wikipedia in der Titanic-Humorkritik – fast weiterlesen…
ARD/ZDF-Online-Studie 2007
21. Mai 2007 um 19:08 2 KommentareWie aus der ARD/ZDF-Online-Studie 2007 vom Anfang diesen Monats hervorgeht, nutzen in Deutschland mit 40,8 Millionen inzwischen 62,7 Prozent der Bevölkerung das Internet. Dabei ist die absolute Zahl der surfenden Senioren (über 60) mit 5,1 Millionen (25,1 Prozent) höher als die der 14-19-Jährigen mit 4,9 Millionen (95,8 Prozent). Allerdings sind Frauen sind noch immer sowohl weniger (17,7 statt 21 Millionen) als auch kürzer online (93 statt 139 Minuten pro Woche). Ob allerdings alle diese Menschen bereit sind, täglich neue Web 2.0-Dienste auszuprobieren, zumal mehr als die Hälfte (52 Prozent) keinen Breitband/DSL-Anschluss verwenden, wage ich zu bezweifeln.

Unter dem Titel „Web 2.0“ (Seite 18/19) werden das „Interesse an der Möglichkeit, aktiv Beiträge zu verfassen und ins Internet zu stellen“ (sehr bis gar nicht interessant, siehe Grafik rechts), „Genutzte Internetangebote zu Web 2.0“ (Wikipedia, Weblogs und Fotogalierien) und die „Häufigkeit der Nutzung von Web 2.0-Angeboten“ (häufig, gelegentlich, selten) ausgewertet. Ich habe die Daten mal bei manyeyes hochgeladen. Interesse an Wikipedia haben etwa ein Viertel aller Onliner (häufig: 14, gelegentlich: 11, selten: 7) Die Studie wird seit 1997 vom Institut für Medien- und Marketingforschung erstellt und enthält noch weitere interessante Ergebnisse z.B. zur Sozialstruktur. Befragt wurden 1820 wahrscheinlich repräsentative Personen (2006). Wie die meisten Leser dieses Blogs gehöre ich wahrscheinlich der in der in der Studie beschriebenen Klasse der „Jungen Hyperaktiven“ (Durchschnittsalter 27 Jahre, 77 Prozent männlich, Internetnutzungsdauer pro Tag mehr als vier Stunden, Anteil der Onliner 2006: 8,1 Prozent) an.
ISBN in Wikipedia – eine Analyse
19. Mai 2007 um 21:05 1 Kommentar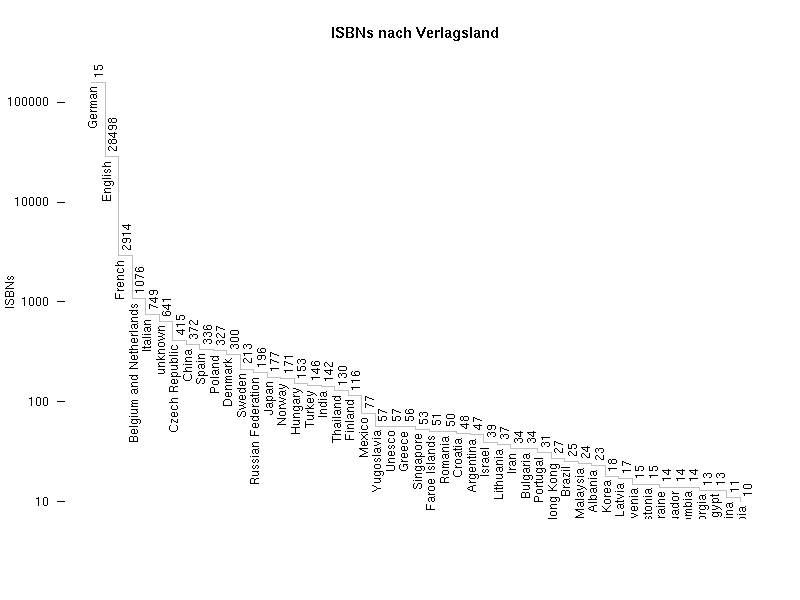
Mathias beschäftigt sich in letzter Zeit intensiv mit den ISBNs, die den Literaturangaben von Wikipedia-Artikeln vorhanden sind und betreibt mit Weiterführende Literatur einen eigenen Blog über „Bücherreferenzierung in der Wikipedia“. Damit hat er mich so angesteckt, dass ich heute den gesamten Tag damit verbracht habe, mit den verfügbaren Daten herumzuspielen. Zunächst werden mit einem Skript von Lars Aronsson alle ISBN-Nummern aus dem Dump einer Wikipedia extrahiert. Mit dem CPAN-Modul Business::ISBN lassen sich dann die Nummern analysieren und mit weiteren Skripts auswerten. Für die Fehlerkorrektur und Statistiken habe ich in Wikipedia die Seite ISBN-Auswertung mit ersten Ergebnissen angelegt. Dabei ist unter Anderem eine Statistik der Länder, in denen die Verlage mit den meisten ISBNs in Wikipedia sitzen (Visualisierung bei many eyes) – gut 80% kommen aus dem deutschen Sprachraum (kein Wunder, ist ja auch die deutschsprachige Wikipedia). Außerdem habe ich die ISBNs mit thingISBN-Daten von LibraryThing verglichen, wodurch ich nicht nur die Abdeckung von Wikipedia-Referenzen in LibraryThing ermitteln kann (20%) sondern gleichzeitig eine FRBRisierung bekomme. Tim Spalding hatte im Februar bereits ähnliches mit der englischen Wikipedia unternommen und Verweise zu Wikipedia in LibraryThing eingebaut (siehe auch mein letzter Beitrag zu LibraryThing für Bibliotheken). Weitere Ideen für Auswertungen? [danke an Mathias, Lars und Tim]
Update: Ich habe mit R (einem ebenso mächtigen wie fast schon benutzerfeindlichen Werkzeug) ein weiteres Diagram der ISBNs nach Verlagsländern erstellt.
Mit Creative Commons 3.0 aus der GFDL-Sackgasse
13. Mai 2007 um 16:48 4 KommentareObwohl sowohl die in Wikipedia genutzte GFDL als auch die Creative-Commons-Lizenzen (in den Varianten, bei denen kommerzielle Verwertung und Bearbeitung erlaubt ist) Lizenzen für freie Inhalte sind, sind sie leider bisher miteinander inkompatibel. So können beispielsweise Wikipedia-Inhalte (da GFDL) nicht mit CC-lizensierten Werken gemischt werden und das Einstellen von CC-lizensierten Inhalte in Wikipedia ist ebenfalls nicht möglich. Mit der Ende Februar erfolgten Veröffentlichung der Version 3.0 der CC-Lizenzen ist jedoch ein wichtiger Schritt in Richtung GFDL-CC-Kompatibilität getan. Wie hier beschrieben werden in Zukunft unter http://creativecommons.org/compatiblelicenses BY-SA-kompatible Lizenzen aufgeführt werden. Dazu könnte in Zukunft auch die GFDL gehören. Jetzt ist die Free Software Foundation am Zug, die ebenfalls eine neue Version der GFDL herausgeben muss, um dies zu erreichen. Die Diskussion zur GFDL 2.0 hat im September letzten Jahres begonnen, ob dabei endlich GFDL/CC-BA-SA-Kompatibilität erreicht werden wird, ist noch unklar.
Übrigens: Wie bei der Digitalen Allmend zu lesen können in der Schweiz wahrscheinlich auch CC-lizensierte Werke gleichzeitig über die Verwertungsgesellschaft Suissimage verwertet werden – ob und wie freie Inhalte in Deutschland über die Verwertungsgesellschaften abgerechnet werden können, ist meines Wissens noch nicht geklärt. Bis also Deutsche Wikipedia-Autoren für ihre Artikel eine Vergütung von VG Wort bekommen können, ist also noch einiges zu tun, aber es liegt im Bereich des Möglichen.
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare