Katalog 2.0-Projekt Beluga mit eigenem Blog
13. September 2007 um 17:50 Keine KommentareAuf der 11. GBV-Verbundkonferenz wurde unter anderem das Hamburger Projekt Beluga vorgestellt. Aktuelles gibt es im Beluga-Blog, wo Anne Christensen verschiedene Katalog 2.0-Projekte vorstellt. Wie sie selbst in netbib schreibt polarisiert das Label “Katalog 2.0″ jedoch und hält zu sehr von einer Diskussion um das Wesentliche ab. Ich würde es folgendermaßen auf den Punkt bringen:
Es geht nicht darum, einen „Katalog 2.0“ zu schaffen, sondern bestehenden Kataloge der fortschreitenden Entwicklung anzupassen und diese mitzugehen und zu gestalten. Wie Markus Krajewski ebenso unterhaltsam wie lehrreich in seinem Buch „Zettelwirtschaft“ (ISBN 3-931659-29-1) darstellt, war auch der Weg zum Zettelkatalog mühsam. Ebenso ist mit der Einführung des OPAC das Bibliothekarische Abendland nicht untergegangen. Katalog 2.0 ist auch nichts, was von heute auf morgen eingeführt wird oder das es bei irgendeiner Firma fertig zu kaufen gibt. Wie der Katalog in 20 Jahren aussehen wird, kann niemand vorhersagen, aber dass er sich ändert halte ich für unzweifelhaft. Die Aufgabe eines Bibliothekars besteht nun darin, sich darüber Gedanken zu machen, was geändert werden kann und soll und diese Änderungen umzusetzen. Wer ganz vorne bei der Diskussion dabei sein möchte, sollte sich die seit letztem Jahr bestehende Mailingliste Next Generation Catalogs for Libraries (NGC4Lib) zu Gemüte führen.
Feedback aus der Blogosphäre zur Beluga-Ankündigung gibt es unter anderem bei Text & Blog, Wortgefecht und Blognation [en] – mehr gibt es über einen Suchfeed.
Eingeschlossene Nutzer im Datengrab Web 2.0
28. August 2007 um 00:51 1 KommentarGestern Nacht hat überraschend Blogscout seinen Dienst eingestellt. Ich hatte den kostenlosen, privaten Dienst bei Markus kennengelernt und gerne genutzt, um zu schauen, von wo und wie oft mein Blog aufgerufen wird und über welche Suchanfragen and Referrer die Besucher kommen – beispielsweise wollen sie wissen, wer Bundeskanzler ist. Jetzt sind diese ganzen Statistiken weg. Das Beispiel erinnert mich daran, dass inzwischen statt Software Webservices und Daten im Zentrum stehen. Die wenigsten Webanwendungen bieten jedoch eine vollständige Exportfunktion, um die Daten auch wieder herauszubekommen. Und selbst dann ist der vollständige Umstieg auf einen anderen Dienst problematisch. Für Backups ist anscheinend der Anbieter des Webservices da (im Zweifellsfall haben die Amerikaner und Chinesen jeweils noch eine Kopie). Ein wenig erinnert mich das an die Microsoft-Produkte, deren Dateiformate den Softwarewechsel auch stark behindert haben. Tim O`Reilly hat es in einem Wired-Interview im April auf den Punkt gebracht: Web 2.0 Is About Controlling Data (aufgegriffen aber bisher nicht viel weitergesponnen von einigen Bibliotheken).
Idealerweise sollten nicht nur die Daten wieder aus dem Webdienst heraus und in eine eigene Anwendung hereinkommen sonder gleich die ganze Webanwendung frei sein. Ein Beispiel dafür ist LiPost, das man sich auch auf dem eigenen Server installieren kann. Für freie Software, die unter der Affero GPL (AGPL) lizensiert ist, ist die Zur-Verfügung-Stellung des Quelltextes bei einer Anwendung als Webdienst sogar zwingend.
Eine ausführlichere Auseinandersetzung mit dem Problem, dass Web 2.0 die durch Freie Software gewonnene Freiheit bedroht, findet sich im Artikel Free Software and the Web von Alejandro Forero Cuervo.
Wird dem Theseus-Projekt (100 Millionen) Geld für eine Begleitstudie hinterhergeworfen?
21. August 2007 um 23:48 1 KommentarBis zum 15.9. läuft eine Ausschreibung des Bundesministerium für Wirtschaft und Technologie zu einer „Begleitforschung für das Forschungsprogramm THESEUS“ (ich berichtete bereits letzten Monat). Mit der Begleitforschung soll „sichergestellt werden, dass die Fördermaßnahme mit hoher Effizienz umgesetzt, die Qualität der wissenschaftlichen Arbeiten gesichert und das im Rahmen von THESEUS gewonnene Know-How schnell verbreitet wird“. Ich stelle hiermit meine folgende Begleitstudie dem BMWi vorab und kostenlos zur Verfügung:
Im Projekt THESEUS wurden mit Hilfe vieler Buzzwords zahlreiche Berichte, Studien und Prototypen erstellt und 100 Millionen Euro Forschungsgelder an 30 Partner aus Industrie, Wissenschaft und Forschung verteilt. Ende der Studie.
Mal im Ernst: Evaluation ist ja eine gute Idee, aber ich Frage mich, ob einem Großprojekt (bei dem jeder Teilnehmern hauptsächlich für sich möglichst viel Renommee und Geld abgreifen möchte aber am Ende für nichts in die Verantwortung genommen wird), mit solch zusätzlicher Metaforschung (bei der doch wieder die Freunde und Bekannten der Auftragnehmer im Boot sitzen) beizukommen ist. Wenn schon großspurig in der Projektbeschreibung von Web 2.0 und Web 3.0 die Rede ist, dann sollte das auch bei der Planung und Begleitung des Projektes deutlich werden. Wie wäre es statt einer aufwendigen und intransparenten Begleitstudie (die eigentlich ja auch wiederum evaluiert werden müsste) mit einigen wenigen, klaren Regeln für alle Beteiligten:
§ 1) alle im Rahmen von Theseus entwickelten Computerprogramme und Programmbibliotheken werden als Freie Software veröffentlicht und im Laufe des Projektes als Open Source zur Verfügung gestellt, so dass sie von unabhängiger Seite evaluiert, weitergenutzt und weiterentwickelt werden können.
§ 2) alle im Rahmen von Theseus erstellten Dokumente (Berichte, Anleitungen, Dokumentationen, Digitalisate etc.) werden im Laufe des Projektes als Freie Inhalte veröffentlicht, so dass sie von unabhängiger Seite evaluiert, weitergenutzt und weiterentwickelt werden können.
§ 3) die unter § 2 genannten Dokumente umfassen insbesondere auch alle im Rahmen des Theseus-Projektes anfallenden Verträge, Protokolle, Absprachen und Standards, für die zusätzlich eine zeitnahe Veröffentlichung bindent ist, so dass die innerhalb des Projektes getroffenen Entscheidungen von unabhängiger Seite kommentiert und ihre Einhaltung kontrolliert werden können sowie Geldverschwendung und Korruption durch Transparenz vermieden werden.
§ 4) bei Verstößen gegen §§ 1-3 werden den Beteiligten Projektpartern die Fördermittel gekürzt.
Zu einfach? Naiv? Undurchsetzbar? Na dann fällt bei 100 Millionen das Geld zur Augenwischerei in Form einer konsequenzlosen Begleitstudie ja auch nicht mehr ins Gewicht.
Apropos naiv: Das BMWi fordert, dass „Für die Darstellung von Ergebnissen [der Begleitstudie] […] die bestehende Internetseite http://theseus-programm.de in Absprache mit der hierfür vom THESEUS-Programm-Büro beauftragten Agentur genutzt werden [soll]“.
Abgesehen davon, dass jede qualifizierte Studie angesichts dieser Forderung zum Ergebnis kommen sollte, dass Geld für eine „Agentur“ rausgeschmissen wurde, weil die Projektpartner zu inkompetent waren, ein CMS bzw. eine gemeinsame Kommunikations- und Publikationsplattform zu nutzen, wird diese Agentur bzw. das „THESEUS-Programm-Büro“ wohl kaum relevante Kritik auf der eigenen Seite ermöglichen. Oder veröffentlicht die Chinesische Nachrichtenagentur Xinhua plötzlich auch Nachrichten über Menschenrechtsverletzungen in China?
P.S: Letzten Freitag wurde Theseus auf der Veranstaltung „Wag the long tail“ des Verbandes der deutschen Internetwirtschaft e.V Theseus „erstmals der Öffentlichkeit vorgestellt“. Die dazugehörige Pressemitteilung wurde an verschiedener Stelle (u.A. heise) rezipiert – was die viertelstündige (sic!) Vorstellung durch Stefan Wess (Geschäftsführer der Bertelsmann-Tochter Empolis) enthielt, erfährt die Öffentlichkeit aber nicht. Bei Linuxworld schreibt schreibt dazu John Blau, der anscheinend dabei war.
Von ISBD zum Web 2.0 mit Mikroformaten
26. Juli 2007 um 14:18 15 KommentareDen folgenden Beitrag habe ich bereits in ähnlicher Form in INETBIB gepostet. Um ihn in die Blogosphäre einzubinden, poste ich ihn hier nochmal als Blogeintrag.
Um sich nicht im Sommerloch langweilen zu müssen, habe ich hier eine kleine Aufgabe für ISBD-Experten, Bibliothekare und andere Zukunftsinteressierte: Es geht um nicht weniger als die die Entwicklung eines bibliothekarischen Datenformates. Da der Beitrag etwas länger ist, hier eine
Zusammenfassung
1. Im Web sind mehr und mehr Daten direkt und in standardisierten Formaten zur Weiterverarbeitung verfügbar
2. Durchsetzen wird sich am Ende das, was im Browser ohne Plugin unterstützt wird
3. So wie es aussieht, werden dies Mikroformate sein
4. Für Bibliographsche Daten fehlt bislang ein Mikroformat
5. Wenn sich Bibliothekare nicht mit ihrem Sachverstand an der Entwicklung eines solchen Formates beteiligen, tun es andere – und das nicht unbedingt nach bibliothekarischen Gesichtspunkten.
Worum geht es?
Beitrag Von ISBD zum Web 2.0 mit Mikroformaten weiterlesen…
Tagging, Umfrage, Buch, Vortrag
12. Juli 2007 um 00:22 4 KommentareDrei kleine Hinweise zum Thema Tagging:
1. Tobias Kowatsch führt für seine Abschlussarbeit eine Web-Experiment-Umfrage zum Thema Tagging durch. Die Auswahl fand ich teilweise etwas komisch aber ich bin ja nur Versuchsperson, also nehmt euch die 13 Minuten und probiert es selber aus!
2. Sascha Carlin hat ein Buch über Social Tagging geschrieben, das vermutlich auf seiner Diplomarbeit basiert. Ich bin gespannt und werde es nach Erscheinen mal genauer unter die Lupe nehmen.
3. Auf der GBV Verbundkonferenz im September werde ich unter anderem über Social Tagging und Bibliotheken und die konkreten Planungen zur Tagging-Unterstützung im GBV referieren.
Dänische Nationalbibliothek kooperiert mit LibraryThing
24. Juni 2007 um 13:27 2 KommentareWie Bernd Wunsch in der Mailingliste NGC4LIB mitteilt, will die Dänische Nationalbibliothek in Zukunft mit LibraryThing kooperieren. Die Anzahl der von zahlreichen Buchliebhabern in LibraryThing eingetragen Titel hat inzwischen die 15 Million überschritten (zum Vergleich: im GBV-Verbundkatalog sind momentan über 27 Millionen Titel, die Library of Congress hat etwa 30 Millionen Titel).
Vorraussichtlich nach der Sommerpause sollen in Dänischen Verbundkatalog unter http://bibliotek.dk/ Funktionen von LibraryThing verfügbar sein. Im DNLA newsletter, der sich allgemein dem Thema Web 2.0 widmet, wird die Motivation für diese Entscheidung erklärt: Anstatt einen erfolgreichen Dienst mit großem Aufwand zu kopieren, ist es viel sinnvoller, mit LibraryThing zu kooperieren. So können den Benutzern direkt
- Bücher bewerten, kommentieren und diskutieren und die Bewertungen, Kommentare und Diskussionen anderer Nutzer einsehen
- Bücher mit eigenen Tags versehen, die Tags anderer Nutzer einsehen per Tags Suchen
- Eigene Büchersammlungen anlegen
Zur Umsetzung wird der Dänische Verbundkatalog als Datenquelle in LibraryThing eingebunden (der GBV ist dort übrigens bereits vorhanden) und wie ich vermute die Benutzeroberfläche des Dänischen Katalogs mit Links auf und Inhalten von LibraryThing angereichert.
Ich hoffe, dass wir vergleichbare Kooperationen auch bald mit deutschen Bibliotheken und Bibliotheksverbünden bekommen. Möglichkeiten zur Diskussion dieser Möglichkeiten und der dazu notwendigen Schritte wird es unter anderem auf dem nächsten Berliner Bibliothek 2.0-Stammtisch, einer angedachten Bibliotheks-Unkonferenz und der GBV-Verbundkonferenz in Bremen geben. Zur nächsten Inetbib-Tagung in Würzburg sollte es dann hoffentlich schon einige Ergebnisse geben.
[Hinweis via IB Weblog, danke an Lene für die Übersetzung aus dem Dänischen]
ARD/ZDF-Online-Studie 2007
21. Mai 2007 um 19:08 2 KommentareWie aus der ARD/ZDF-Online-Studie 2007 vom Anfang diesen Monats hervorgeht, nutzen in Deutschland mit 40,8 Millionen inzwischen 62,7 Prozent der Bevölkerung das Internet. Dabei ist die absolute Zahl der surfenden Senioren (über 60) mit 5,1 Millionen (25,1 Prozent) höher als die der 14-19-Jährigen mit 4,9 Millionen (95,8 Prozent). Allerdings sind Frauen sind noch immer sowohl weniger (17,7 statt 21 Millionen) als auch kürzer online (93 statt 139 Minuten pro Woche). Ob allerdings alle diese Menschen bereit sind, täglich neue Web 2.0-Dienste auszuprobieren, zumal mehr als die Hälfte (52 Prozent) keinen Breitband/DSL-Anschluss verwenden, wage ich zu bezweifeln.

Unter dem Titel „Web 2.0“ (Seite 18/19) werden das „Interesse an der Möglichkeit, aktiv Beiträge zu verfassen und ins Internet zu stellen“ (sehr bis gar nicht interessant, siehe Grafik rechts), „Genutzte Internetangebote zu Web 2.0“ (Wikipedia, Weblogs und Fotogalierien) und die „Häufigkeit der Nutzung von Web 2.0-Angeboten“ (häufig, gelegentlich, selten) ausgewertet. Ich habe die Daten mal bei manyeyes hochgeladen. Interesse an Wikipedia haben etwa ein Viertel aller Onliner (häufig: 14, gelegentlich: 11, selten: 7) Die Studie wird seit 1997 vom Institut für Medien- und Marketingforschung erstellt und enthält noch weitere interessante Ergebnisse z.B. zur Sozialstruktur. Befragt wurden 1820 wahrscheinlich repräsentative Personen (2006). Wie die meisten Leser dieses Blogs gehöre ich wahrscheinlich der in der in der Studie beschriebenen Klasse der „Jungen Hyperaktiven“ (Durchschnittsalter 27 Jahre, 77 Prozent männlich, Internetnutzungsdauer pro Tag mehr als vier Stunden, Anteil der Onliner 2006: 8,1 Prozent) an.
ISBN in Wikipedia – eine Analyse
19. Mai 2007 um 21:05 1 Kommentar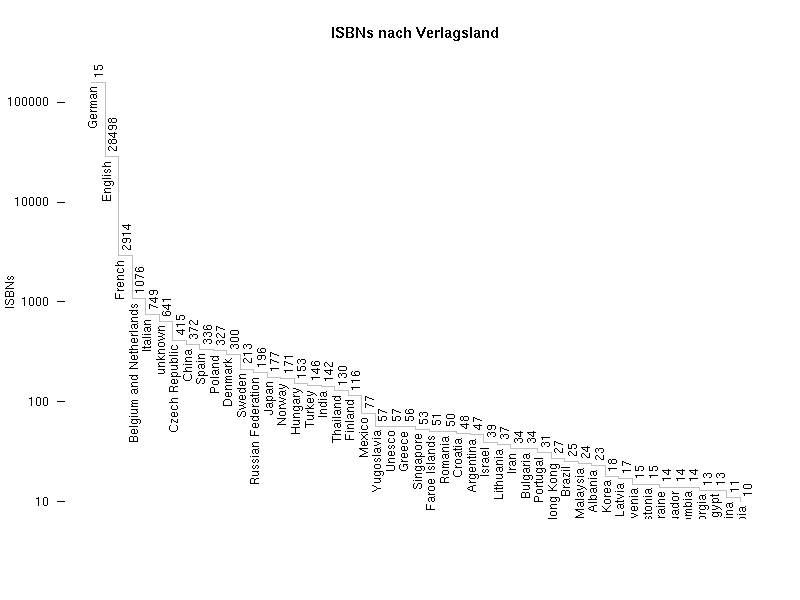
Mathias beschäftigt sich in letzter Zeit intensiv mit den ISBNs, die den Literaturangaben von Wikipedia-Artikeln vorhanden sind und betreibt mit Weiterführende Literatur einen eigenen Blog über „Bücherreferenzierung in der Wikipedia“. Damit hat er mich so angesteckt, dass ich heute den gesamten Tag damit verbracht habe, mit den verfügbaren Daten herumzuspielen. Zunächst werden mit einem Skript von Lars Aronsson alle ISBN-Nummern aus dem Dump einer Wikipedia extrahiert. Mit dem CPAN-Modul Business::ISBN lassen sich dann die Nummern analysieren und mit weiteren Skripts auswerten. Für die Fehlerkorrektur und Statistiken habe ich in Wikipedia die Seite ISBN-Auswertung mit ersten Ergebnissen angelegt. Dabei ist unter Anderem eine Statistik der Länder, in denen die Verlage mit den meisten ISBNs in Wikipedia sitzen (Visualisierung bei many eyes) – gut 80% kommen aus dem deutschen Sprachraum (kein Wunder, ist ja auch die deutschsprachige Wikipedia). Außerdem habe ich die ISBNs mit thingISBN-Daten von LibraryThing verglichen, wodurch ich nicht nur die Abdeckung von Wikipedia-Referenzen in LibraryThing ermitteln kann (20%) sondern gleichzeitig eine FRBRisierung bekomme. Tim Spalding hatte im Februar bereits ähnliches mit der englischen Wikipedia unternommen und Verweise zu Wikipedia in LibraryThing eingebaut (siehe auch mein letzter Beitrag zu LibraryThing für Bibliotheken). Weitere Ideen für Auswertungen? [danke an Mathias, Lars und Tim]
Update: Ich habe mit R (einem ebenso mächtigen wie fast schon benutzerfeindlichen Werkzeug) ein weiteres Diagram der ISBNs nach Verlagsländern erstellt.
LibraryThing für Bibliotheken
18. Mai 2007 um 00:58 2 KommentareDer bereits im April von Tim Spalding angekündigte Dienst LibraryThing for Libraries nimmt erste konkrete Formen an: Der erste OPAC, in den Dienste von LibraryThing darüber eingebunden sind, ist der Danbury Library’s catalog. Es gibt darüber inzwischen eine zunehmende Anzahl von Berichten, aber am Besten beschreibt es Tim selbst.
Ich überlege übrigens seit einiger Zeit, wie sich LibraryThing in deutschen Bibliotheken (speziell PICA-Systemen) einsetzen lassen kann und was dazu konkret zu tun ist. Ich befürchte allerdings, dass die Schnittmenge zwischen wissenschaftlichen Bibliotheken und LibraryThing nicht ganz so groß ist. Sollten Bibliotheken ihre Bestände in LibraryThing einspielen? Was soll im OPAC zusätzlich angezeigt werden? Wer sollte das Umsetzen und wo wird welche Hilfestellung benötigt? Anregungen sind sehr willkommen, je genauer, desto besser!
Ein Anwendungsbeispiel habe ich schon: 1.) In einem OPAC wird ein Titel angezeigt. 2.) Mit thingISBN werden ISBN-Nummern von gleichen Werken ermittelt. 3.) Es wird ermittelt, welche Titel der ISBN-Liste ebenfalls im OPAC vorhanden sind (mit Kurztitel und Link) 4.) Die Titel werden zusätzlich angezeigt. Wenn die dafür notwendigen Daten erstmal einfach verfügbar vorhanden sind (sic!) ist sowas ziemlich schnell implementiert. Weitere Wünsche und Anregungen?
[via Infobib]
Vom Löschen und Betreuen neuer Wikipedia-Artikel
9. Mai 2007 um 16:30 3 KommentareÜber die Löschkandidaten in Wikipedia bin ich zufällig auf den Artikel über getAbstract gestolpert, der zur Löschung steht. Ein anderer neuer Wikipedia-Artikel, dessen vollzogene Löschung zur Zeit anderswo diskutiert wird ist der Verein BücherFrauen e.V. Beide Artikel waren eigentlich relativ stimmig, übersichtlich und einigermaßen informativ – trotzdem fanden sich in beiden Fällen wenig Befürworter für eine Beibehaltung in der Wikipedia. Was lässt sich daraus lernen?
Beitrag Vom Löschen und Betreuen neuer Wikipedia-Artikel weiterlesen…
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare