Mashups zusammenklicken mit Mashup-Editoren
25. September 2007 um 01:17 Keine KommentareWie heise vermeldet (und viele andere, darunter Talis in einer Semantic-Web-Linkliste) gibt es mit Intels Mashup Maker nach Google Mashup Editor schon den zweiten großen (noch-)Vaporware-Mashup-Editor. Weitere dieser webbasierten, graphischen Benutzeroberflächen, mit denen sich verschiedene Datenquellen verknüpfen und relativ einfach Skripte zur automatischen Verarbeitung und Anreicherung von Daten erstellen lassen, sind Yahoo Pipes, Microsoft Popfly, QEDWiki und Piggy Bank – je weiter man die Definition fasst, desto mehr Tools zur Datenextraktion und Informationsintegration gibt es. Mit dem Trend, immer mehr Daten überhaupt irgendwie strukturiert (Microformats, unAPI etc.) oder sogar in einer gemeinsamen virtuellen Datenbank (Semantic Web) anzubieten, dürfte das Gemische noch mehr zunehmen – nach dem ersten großen Rausch sollte dann allerdings hoffentlich auch klar werden, dass Themen wie Informationsqualität und Data Lineage (=woher stammen die Daten eigentlich?), Datenvisualisierung und Interface-Design ebenfalls wichtig sind und dass Daten ohne (sozialen) Kontext erstmal keinen Mehrwehrt dastellen, egal wie toll sie gemischt werden.
In jedem Fall interessant zu sehen, dass nicht mehr nur Informatiker Daten hin- und herschieben können. Die Bibliothekare sind nicht die Einzige Zunft, deren praktische Tätigkeit mehr und mehr von Laien beherrscht wird, während der theoretische Hintergrund erstaunlich unbekannt bleibt 😉
P.S.: Bei all den verschiedenen Mashup-Diensten muss natürlich irgendwann wieder vereinheitlicht werden: Netvibes hat mit der Universal Widget API (UWA) eine JavaScript-API vorlgelegt, mit deren Hilfe Anwendungen auch bei iGoogle, Apple Dashboard u.A. eingesetzt werden können. Fehlt nur noch ein universeller Mashup-Editor, der UWA ausspuckt. Kommen jetzt nach dem Browserkrieg die Mashup-Kriege? [via heise]
Tagging enriched with controlled vocabularies
10. September 2007 um 03:36 7 KommentareFor Connotea there was published „Entity Describer“ (ED), an add-on tool that allows taggers to select terms from a controlled vocabulary such as MeSH. Background information can be found in the blog of its developer Benjamin Good. Up to now Entity Describer can only be used via a Greasemonkey script. [via Catalogoblog and netbib]
I bet soon there will be more tagging applications that support controlled vocabularies. For instance Sarah Hayman and Nick Lothian plan to extend the Education Network Australia (edna) with – how they call it – taxonomy-directed folksonomy. See their IFLA-Paper (that Patrick pointed me to) for more information.
Benjamin Good also wrote a paper about his work on ED and published it on his blog before even recieving reviewers comments. I like the following discussion on whether and how to publish it – a nice example of the changes in academic publishing. Now the paper is best available as preprint, identified with hdl:10101/npre.2007.945.1 and licensed under the Creative Commons Attribution 2.5 License (!). Thanks Benjamin and thanks to Nature for making this possible!
I already cited the work in an ongoing discussion about the Wikipedia-Article „Folksonomy. The discussion is mostly about words and I hate it. Good et al also contribute in confusion: Why do they have to introduce a new term („Semantic annotation means the association of a data entity with an element from a classification scheme“) instead of using existing vocabulary? A look at my typology of tagging systems could help clarification.
Well… or maybe tagging researchers just like to add synonyms and polysems because they are so used to them – a folksonomy will emerge anyhow so just call it how you like… 🙁
Blogtip und Programmtip
2. August 2007 um 20:30 Keine KommentareUnter www.microformats.dk betreibt Søren Johannessen ein kleines, feines Blog über Mikroformate und Mashups, auf dass ich dank Trackback gestoßen bin. Einiges versteht man vom Dänischen auch so und im Zweifel ist der persönliche Nachbarländer des Vertrauens zu fragen (eine Automatische Übersetzung Dänisch-Deutsch würde mich wundern, da ist einfach der Markt nicht groß genug). Dänen habe ich hier auf der Wikimania bisher nicht getroffen aber neben Taiwanesen viele andere Nationalitäten. Die Erfahrung, mal so völlig Ausländer zu sein, weder Sprache noch Schrift noch die besonderen Gewohnheiten zu verstehen, ist für mich doch noch etwas neues und sehr interessant. Heute habe ich fast den ganzen Tag damit verbracht, das Programm für morgen fertigzustellen (hier die Endversion als PDF) und mich danach noch an meinen eigenen Vortrag gesetzt. Dafür war das Abendessen in einem guten vegetarischen (sic!) Restaurant phänomenal. Mit umgerechnet 18 Euro war das überaus umfangreiche Buffet eher am oberen Ende der Preisskala, ich habe auch schon sehr lecker für etwa 1,50 mich an Dumplings sattgegessen. Das Taiwanesische Essen ist kurzgesagt unglaublich vielfältig und lecker.
Von ISBD zum Web 2.0 mit Mikroformaten
26. Juli 2007 um 14:18 15 KommentareDen folgenden Beitrag habe ich bereits in ähnlicher Form in INETBIB gepostet. Um ihn in die Blogosphäre einzubinden, poste ich ihn hier nochmal als Blogeintrag.
Um sich nicht im Sommerloch langweilen zu müssen, habe ich hier eine kleine Aufgabe für ISBD-Experten, Bibliothekare und andere Zukunftsinteressierte: Es geht um nicht weniger als die die Entwicklung eines bibliothekarischen Datenformates. Da der Beitrag etwas länger ist, hier eine
Zusammenfassung
1. Im Web sind mehr und mehr Daten direkt und in standardisierten Formaten zur Weiterverarbeitung verfügbar
2. Durchsetzen wird sich am Ende das, was im Browser ohne Plugin unterstützt wird
3. So wie es aussieht, werden dies Mikroformate sein
4. Für Bibliographsche Daten fehlt bislang ein Mikroformat
5. Wenn sich Bibliothekare nicht mit ihrem Sachverstand an der Entwicklung eines solchen Formates beteiligen, tun es andere – und das nicht unbedingt nach bibliothekarischen Gesichtspunkten.
Worum geht es?
Beitrag Von ISBD zum Web 2.0 mit Mikroformaten weiterlesen…
Warum Mikroformate noch nicht so toll sind
3. Juli 2007 um 01:54 3 KommentareChristian hat neulich seine Links zum Thema Mikroformate/Microformats zusammengefasst und merkte an, dass auf infobib das hcard-Mikroformat für Personendaten verwendet wird. Ich mag Microformats ja auch aber so ganz ausgereift scheint mit das doch noch nicht zu sein:
Web2.0-Junkies mögen ihre Freude an technischen Spezifikationen haben, aber normale Menschen interessiert sowas wie „Format“ doch zu Recht nicht die Bohne (ich darf mich hoffentlich je nachdem zu beiden Personengruppen zählen). Wenn sich schon jemand die Mühe macht, in einheitlicher Form eine maschinenlesbare „Visitenkarte“ auf seine Webseite zu bringen, dann erwarte ich sie mit einem einfachen Klick in meiner Adressverwaltung übertragen zu können. Dazu sind aber bislang folgende Hürden zu nehmen:
- Die Überwindung, sich mit Mikroformaten zu beschäftigen, während es eigentlich einfach nur „funktionieren“ soll.
- Die Wahl von Firefox als Webrowser und ein Microformats-Plugin wie zum Beispiel Operator, das die Mikroformate aus einer Webseite auslesen kann.
- Das Herumkonfigurieren am Plugin (in Operator sollte „display icon in status bar“ in den Plugin-Einstellungen aktiviert werden).
- Eine Anwendung, die mit dem entsprechenden Mikroformat (hier vCard) etwas anfangen kann.
- Die Erkenntnis, dass bisher sowieso nur wenige Webseiten Mikroformate anbieten.
Mir war es beim vorletzten Punkt zu viel: Thunderbird kann vCard zwar beigebracht werden, aber nicht direkt aus dem Browser heraus, also muss ich die Adressdaten mit dem Operator-Plugin erst als vCard-Datei speichern und dann die Datei in Thunderbird importieren.
Bei Software-Monokulturen wie Apple oder KDE mag der Austausch von Daten über Programme hinweg ja einwandfrei funktionieren, aber dafür werden eigentlich keine Mikroformate benötigt. Bis verschiedenste Informationen problemlos aus dem Netz in andere Anwendungen übernommen werden können, dauert es sicherlich noch etwas, zumal selbst die Web 1.0-Grundlage Mime-type (auch Content-Type in HTTP) oft nicht richtig verwendet wird.
Begriffssysteme, Ontologien und ihr gemeinschaftlicher Aufbau mit Wikis
27. Mai 2007 um 13:06 2 KommentareVor inzwischen gut 4 Jahren habe ich mich im Rahmen einer Studienarbeit im Diplomstudiengang Informatik mit verschiedenen Arten von Begriffssystemen beschäftigt. Ausgangspunkt war der mangelnde Austausch zwischen Informationswissenschaft und Informatik im Bereich der Wissensorganisation: Während die Informatiker plötzlich alles „Ontologie“ nannten und mit der unreflektierten Neuerfindung des Rades Forschungsgelder einkassierten, hinkten die Informationswissenschaftler der technischen Entwicklung um Jahre hinte (syptomatisch unter Anderem daran erkennbar, dass viele Thesauri bislang nur auf Papier erhältlich sind).
Die Situation bessert sich inzischen, wenn auch nur langsam. So ist beispielsweise beim Thema Tagging (früher: Indizierung/Indexierung) momentan Ähnliches zu beobachten, weshalb ich mit den Versuch einer umfassenderen Typologie von Indexierungssystemen gewagt habe. Im Tagungsband der letzten DGI-Online-Tagung ist nun ein feiner Artikel von Katrin Weller aus dem Ontoverse-Projekt zum „Kooperativen Ontologieaufbau“ erschienen, der sich in Bezug auf die Begriffsverwirrung in der Ontologieforschung und der Notwendigkeit einer Zusammenarbeit zwischen den Disziplinen meiner damaligen Beurteilung anschließt.
Der Artikel ist ebenso wegen Wellers Ausführungen zum gemeinschaftlichen Ontologieaufbau und der dafür angedachten Verwendung von Wikis zu empfehlen. Im Forschungsprojekt Ontoverse soll eine Wiki-Plattform zur gemeinschaftlichen Erstellung und Pflege von Ontologien entwickelt werden, die „inter-ontologische“ (Aufarbeitung von Wissen innerhalb eines abgegrenzten Themenbereiches) und „intra-ontologische“ (Interoperabilität zwischen verschiedenen Ontologien) Aspekte in Beziehung setzt und „die Konsensbildung und den Diskurs im Rahmen des Ontologieaufbaus unterstützt“. Zwar fehlen im Artikel etwas konkretere Beispiele und einige bereits existierende Ansätze wie beispielsweise Semantic MediaWiki oder bisherige Versuche, einfache Thesauri und Klassifikationen mit Wikis zu verwalten, bleiben unerwähnt, aber es handelt sich ja auch nur um eine erste Einführung.
Ich bin gespannt auf die Ergebnisse des Ontoverse-Projekts und hoffe, dass es nicht bei rein akademischen Prototypen bleibt, wie in der Informatik leider allzu oft üblich – bis jetzt ist ja auf der Homepage des Projekts wenig konkretes zu erfahren und der Aufruf zu einem Workshop 2006 ist ja auch nicht mehr ganz aktuell.
The many standards for structured vocabularies for information retrieval
1. Mai 2007 um 19:46 1 Kommentar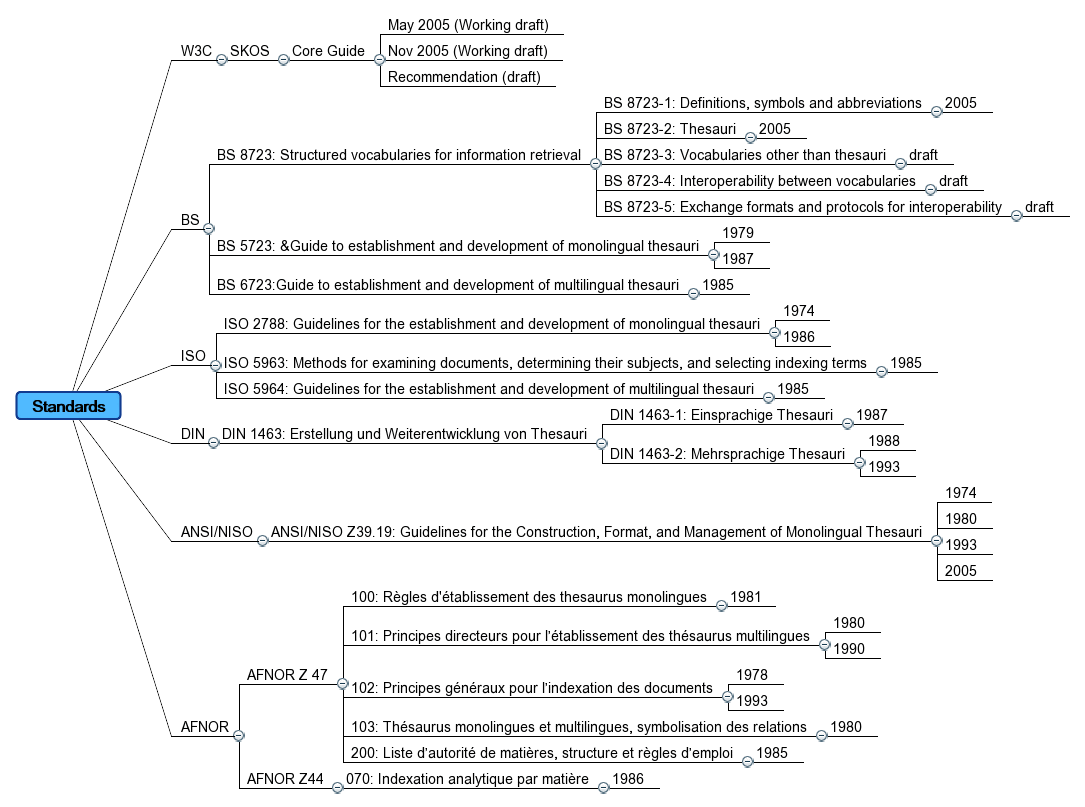
I am currently browsing through the draft of British Standard BS 8723: Structured vocabularies for information retrieval, part 3 (Vocabularies other than thesauri) and 4 (Interoperability between vocabularies). I must confess that reading standards is mostly a pain, especially this old-fashioned pre-web standards in information retrieval. I tried to find out the ancestors of BS 8723 but it took me almost hours. There are dozen of poorly documented related standards and versions (BS 5723, BS 6723, ISO 2788, ISO 5964, DIN 1463, ANSI/NISO Z39.19, AFNOR Z 47 etc.) and most of them are not freely available (and the only available standards are paper-centered PDF instead of web-centered HTML/XML). A standard that is not accesible is pretty worthless! I often complain about the Semantic Web community that ignores most of traditional information retrieval – but they understandably ignore previous results: If traditional information retrieval has not even achieved to visibly and clearly document its own standards on the web – what is it worth for? A general overhaul is necessary: SKOS and collaborative tagging are only two representatives of this change. I fear that BS 8723 will not be part of the new times unless it becomes available Hypertext.
Semantisches Wiki lobt Preis für besten Inhalt aus
18. April 2007 um 22:09 10 KommentareIn Wikimetrics habe ich auf einen Preis von „Centiare“, einem semantischen Wiki für (Personen-, Organisationen-, etc.)-Verzeichnisse hingewiesen. Einerseit eine schöne Sache (sowohl der Preis als auch die praktische Anwendung von Semantic MediaWiki, andererseits ist die in Centiare praktizierte Mischung von freien und nicht-freien Inhalten problematisch.
Semantic Web meets Digital Libraries
14. April 2007 um 16:45 2 KommentareI am currently researching on „Semantic Digital Libraries“ for a book chapter on „Semantic Wikipedia“. Here is a list of current events in this quite new research area (at least by name), ordered by date:
- 11th European Conference on Digital Libraries (ECDL, Sep 16-21, Budapest) – submission just closed, may include some related presentations
- Joint Conference on Digital Libraries 2007 (JCDL2007, June 17-23, Vancouver, Canada) – papers should be ready so preprints may be available
- Tutorial on Semantic Digital Libraries at the World Wide Web Conference 2007 (WWW2007, May 8-12, Alberta, Canada)
- Call for Papers (just elapsed) for a special issue on Digital Libraries: From Alexandria to YouTube and Wikipedia – Embedding Social Dynamics of the International Journal of Digital Culture and Electronic Tourism (IJDCET)
- International Conference on Semantic Web and Digital Libraries (ICDS-2007, Feb 21-22, Bangalore, India).
- Workshop on Semantic Technologies in Collaborative Applications (STICA 06, June 26-28, Manchester, UK)
- Joint Conference on Digital Libraries (JCDL 2006, June 11-15, USA), especially the Tutorials on Semantic Digital Libraries and Thesauri and ontologies in digital libraries and some other sessions.
- Workshop Semantic Approaches in Digital Libraries (June 23, 2004, Lund University, Sweden).
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare