Chatbox als Widget im Katalog
10. Dezember 2007 um 11:07 Keine KommentareLambert weist in Netbib auf die Widget-basierte Einbindung einer Chatbox im Katalog hin, wenn eine Suche keine Treffer liefert. Ein schönes Beispiel dafür, wie einzelne Dienstleistungen als eigenständige Services angeboten und kombiniert werden können. Mit der Ende September vorgestellte Universal Widget API (UWA) könnte das etwas einfacher werden. Dass trotz aller Begeisterung nicht jeder Service in jedem Kontext sinnvoll ist, dürfte klar sein – ein Haufen Widgets macht noch keine Bibliothek, dafür sind Bibliothekare notwendig, die eigene Ideen für Services und Widgets entwickeln und bestehende Dienste ausprobieren – die konkrete Programmierung neuer Widgets kann ja gerne Experten überlassen werden, aber Existierendes zusammenführen, Ausprobieren, Diskutieren, und Ideen entwickeln kann nicht einigen Wenigen überlassen werden!
Google-Wikipedia-Connection and the decay of academia
10. Dezember 2007 um 02:49 6 KommentareMathias pointed [de] me to a lengthy and partly ridiculous „Report on dangers and opportunities posed by large search engines, particularly Google“ by Hermann Maurer [de] (professor at the IICM, Graz) and various co-authors, among them Stefan Weber, whose book [de], I already wrote about [de]. Weber is known as well as Debora Weber-Wulff for detecting plagiarism in academia – a growing problem with the rise of Google and Wikipedia as Weber points out. But in the current study he (and/or his colleauges) produced so much nonsense that I could not let it uncommented.
Beitrag Google-Wikipedia-Connection and the decay of academia weiterlesen…
Keine Angst vorm Atom – wir haben ja Lobbyisten!
8. Dezember 2007 um 01:33 1 KommentarDas Deutsche Atomforum hat knapp gewonnen beim Worst EU Lobbying Award in der Kategorie „Worst EU Greenwash Award“. Die Lobbyorganisation versucht im Rahmen der Klimaschutz-Debatte Atomkraft als besonders umweltfreundlich zu verkaufen. Das geht doch viel besser, wie die NDR-Sendung „Extra 3“ (mit blog und podcast) im August treffend vormachte:
Wer nicht nur ein ordentlich oder unordentlich angemeldetes oder nicht angemeldetes „neuartiges Empfangsgerät“ hat (ob bei den Extra-3-Machern viel von meine Gebühren ankommt, bezweifle ich, da das Geld anscheinend für weitere regelmäßige Nachfragen draufgeht), sondern auch einen Fernseher, kann nicht nur die anscheinend hervorragende Sendung Extra-3, sondern auch im ZDF am Sonntag (zum Frühstück von 13:20-14 Uhr) einen Beitrag über Greenwash ansehen.
Übrigens werden nicht nur Politiker und Öffentlichkeit von Lobbyisten gehirngewaschen – denn „die Politik“ (natürlich quatsch – gemeint ist konkret die Bundesregierung) schlägt zurück: mittels Schleichwerbung und vorformulierten Beiträgen, die dank geheimgehaltener Werbeagenturen kommentarlos von anderen Medien übernommen werden. Brauchen Medien bald neben einem Prozessfonds zum Abwehren von Klagen auch einen Hilfsfond, um sich eigene Recherche leisten zu können? Notwendig ist ja auch noch ein Grundkurs in Anonymisierungsdiensten, denn wie u.A. dieser Video-Beitrag (ebenfalls vom NDR) recht gut deutlich macht, sieht es für investigativen Journalismus mit der Vorratsdatenspeicherung düster aus.
Von Göttinger Tier-Feeds und Hannoveraner Bibliotheks-Mashups
6. Dezember 2007 um 17:32 1 KommentarWährend der soeben beendeten, zweiten VZG-Fortbildung zu RSS, Feeds und Content Syndication (die Folien sind schon mal bei Slideshare) wollte ich bei Feedblendr zur Demonstration einen aggregierten Feed zur Stadt Göttingen zusammenstellen. Als erster Treffer bei Google Blogsearch kam dazu zufälligerweise eine Mitteilung über die in Hamm, Oldenburg und Göttingen verfügbare Onleihe (von der Göttinger Stadtbücherei hatte ich dazu schon gestern eine Mail bekommen). Zu den weiteren Entdeckungen gehört, das Göttinger „Tierheim 2.0„, wo Hunde, Katzen und Kleintiere per RSS-Feed abonniert werden können: „Feed the animals„!
Bei einer Google-Suche nach der (leider etwas schwer auffindbaren) Seite der Bibliothek im Kurt-Schwitters-Forum Hannover bin ich dann auf das Weblog Bibliotheken in Hannover gestoßen, in dem Christian Hauschke und Manfred Nowak vom Workshop „Social Software in hannoverschen Bibliotheken“ berichten. Christians Ausführungen zu Lageplänen mit Google Maps (einen Lageplan in Google Maps einzuzeichnen, dauert auch ohne Vorkenntnisse höchstens zwanzig Minuten) möchte ich um eine Mashup-Idee ergänzen, die ich bereits neulich in meiner Lehrveranstaltung vorgestellt habe: Mit dem Perl-Modul PICA::Record lässt sich der Gesamtkatalog Hannover über SRU nach Bestandsdaten durchsuchen – dazu ist lediglich in diesem Beispielskript die Datenbank 2.92 statt 2.1 auszuwählen. Die so ermittelten Bibliotheken können dann mit etwas Bastelei in Google Maps angezeigt werden. Statt oder neben einer Liste der Bestandsnachweise wird dann zu einem Titel geografisch angezeigt, in welcher Bibliothek das Buch vorhanden ist. Mit Zugriff auf die Exemplardaten in den einzelnen OPACs könnte sogar noch angezeigt werden, ob ausleihbare Exemplare gerade vorhanden sind – wie das im Ansatz geht, steht in diesen Folien.
Linking to Wikipedia via ISBN
5. Dezember 2007 um 19:52 2 KommentareTwo weeks ago I announced a new beta webservice for linking from title data to German Wikipedia articles that cite a given work by ISBN. Now Lambert pointed me to a message by Eric Hellmann about xISBN supporting links to the English Wikipedia since last week. This makes GBV one week earlier then OCLC and both of us ten month later then LibraryThing. The idea is not new but based on the work of Lars Aronsson, Spiritus rector of future library systems.
The three services have been developed partly parallel based on some same code. Here are two examples of the xISBN service by Xiaoming Liu and the GBV service that I am developing. xISBN is based on a powerfull API with many query parameters and planned to be part of WorldCat Grid Services (more about this maybe here, here, here, and here), while my service is based on a simple API called SeeAlso which is based on OpenSearch Suggestions and unAPI. Both approaches have their pros and cons. I will provide more information as soon as our server is more stable and the scripts are clean enough to get published at CPAN. Meanwhile I encourage everyone to play with OCLC’s xISBN (via an API of its own), WorldCat Idenities (via SRU), LibraryThing for Libraries (via an API of its own), available catalouges (via Z39.50, via SRU and via other APIs), the Wikipedia Query API, and the growing number of other services. Let’s mash up the library systems for the future!
Verweise auf passende Rezensionen
5. Dezember 2007 um 16:35 4 KommentareNachdem ich in einer Fortbildung (siehe slides) am Rande die Realisierung von Links auf Wikipedia mittels des SeeAlso-Protokolls vorgestellt habe, kam von einer Teilnehmerin die Idee, auf die selbe Weise auf Rezensionen zu verweisen. Neben Amazon (wo Rezensionen manipuliert werden) und LibraryThing gibt es eine Vielzahl von Rezensionsdiensten von Fachreferenten und Wissenschaftlern. Leider bekommt dies außerhalb enger Fachcommunities kein Schwein mit, da Rezensionen weder systematisch erschlossen werden, noch praktikabel recherchierbar sind – dies gilt anscheinend auch für Rezensionen in Zeitungen, z.B. bei der ZEIT. Die Idee, über einen Linkserver Verweise auf passende Rezensionen zu liefern, finde ich wunderbar, weshalb ich gleich mal ein Konzept erstellt habe. Hier nur das Diagram, ausführlich im GBV-Wiki:
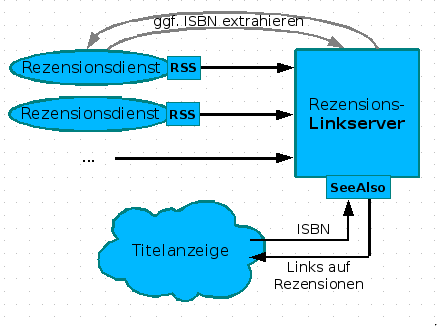
Leider hinken die meisten Rezensionsdienste dem Stand der Technik hinterher und bieten keine (oder kaputte) Feeds an. Wollen die nicht gelesen werden? Nun ja, vielleicht wachen Sie noch auf. Kennt jemand weitere Rezensionsdienste mit benutzbaren Feeds? So lange nicht genügend Rezensionsdienste verfügbar sind, ist der skizzierte Linkserver den Aufwand nicht wert, aber das kann ja noch kommen. Bitte mehr solcher Ideen! Wer nicht weiß, was Feeds sind und sich nicht vorstellen kann, wie ein Linkserver funktioniert, oder den Unterschied zwischen Indexbasierter und Metasuchmaschine nicht einigermaßen verinnerlicht hat, wird auch nicht auf die Ideen kommen, die notwendig sind, damit Bibliotheken nicht in der Bedeutungslosigkeit verschwinden. Deshalb sind Fortbildung und genügend freie Zeit zum Experimentieren so wichtig – zum Beispiel mit diesen Web 2.0-Diensten!
P.S: Neben Rezensionen und Lins auf Wikipedia können auch andere Informationen zu einem Werk von Interesse sein, z.B. Zusammenfassungen, Erwähnungen in Blogs etc.
Social Cataloging in Wikipedia
5. Dezember 2007 um 01:19 Keine KommentareLast week I gave an introduction into social tagging and cataloging for librarians (some German slides here at Slideshare). In a discussion on German Wikipedia about COinS I was pointed to the French Wikipedia: They have a special namespace référence to store more detailled bibliographic information (see MediaWiki-namespaces in general), some more information is collected in Projet:Références, but my French is too little to find out much. This example may demonstrate the concept:
The article „Première période intermédiaire égyptienne“ cites the source „Nicolas Grimal, Histoire de l’Égypte ancienne, 1988“. The citation provides a link to on a special page that lists several editions of the work. Actually this is another implementation of FRBR.
I like the idea of seggregating full bibliographic record and reference in the Wikipedia article, but the concrete solution is too complicated and limited. Wikipedia with flat text is just not the right tool to store bibliographic data. Maybe Semantic MediaWiki can help, but a multilingual approach like LibraryThing does is better. French Wikipedians should not have to duplicate cataloging efforts, but just point to LibraryThing, WorldCat or whatever bibliographic authority is usable. By the way most library catalouges are not usable in this sense – on the Web noone cares how good you data is if you cannot directly link to it and use it in other context.
Wikipedia-Wortschatz-Analyse aktualisiert
3. Dezember 2007 um 00:55 Keine KommentareWie Matthias Richter mitteilt, hat er die Wikipedia-Datenbasis im Deutschen Wortschatz-Portal aktualisiert. Neben statistisch signifikant häufig in einem Satz vorkommenden Wörtern, wird unter http://wortschatz.uni-leipzig.de/WP/ nun auch die Linkstruktur zwischen den Artikel analysiert. Siehe da: Internet wird signifikant häufiger zusammen mit Bibliothek verlinkt – noch häufiger aber sind Archiv und Museum. Ich schließe daraus unwissenschaftlicherweise, dass noch nicht ausgemacht ist, ob Bibliotheken irgendwann nur noch Archive und Museen sein werden oder im Internet auch in Zukunft für die Informationsversorgung relevant sein werden 😉

Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare