Fortbildung Weblogs und RSS
9. Mai 2008 um 09:57 3 KommentareGestern habe ich im Zentrum für bibliothekarische Fortbildung in Niedersachsen mal wieder einen Workshop veranstaltet, diesmal ging es speziell um Weblogs und Feeds. Die Vortragsfolien sind bei Slideshare (zum Anschauen im Browser oder zum Herunterladen im OpenOffice-Format). Für die eigene Nachbereitung und alle, die nicht dabei waren, kann ich die Lehrreihe Lernen 2.0 empfehlen – zu Weblogs gibt es dort drei Lektionen: Lektion 1: Weblog erstellen, Lektion 2: Im Weblog schreiben und Lektion 3: RSS entdecken und verstehen. Ich hoffe, die Teilnehmer streuen ihr Wissen auch unter ihren Kollegen, denn leider ist der Umgang mit Weblogs in Bibliotheken noch immer nicht so alltäglich wie es sein sollte. Vor allem in der Führungsebene fehlt manchmal das Grundverständnis für die neuen Mediengattungen, wenn lieber ignoriert oder nachgeplappert statt selber ausprobiert wird.
Zum Thema „Feeds von Fachzeitschriften“ möchte ich noch nachtragen, dass über die Datenbank Online Contents (OLC) theoretisch unter allgemeinen Suchanfragen natürlich auch die neuesten Artikel einer bestimmten Zeitschrift per RSS-Feed abonniert werden können. Dazu ist zunächst die Zeitschrift ausfindig zu machen (in der Datenbank OLC-Journals oder in der OLC-Gesamtdatenbank, z.B. nach ISSN oder ZDB), dann unten Rechts „Alle Aufsätze“ auszuwählen und es erscheint ein Hinweis auf den Feed. Diese 2-3 automatisierbaren Schritte könnte ich mit einem einfachen Service zusammenführen, so dass man über SeeAlso bei gegebener ISSN oder ZDB-ID im Katalog direkt einen passenden Feeds mit den neuesten Artikeln dieser Zeitschrift anbieten könnte. Praktisch scheitert dieses Vorhaben jedoch mal wieder an der Fortschrittsbremse Urheberrecht, denn Online-Contents ist nicht frei zugänglich und somit funktionieren auch die Feeds nur bedingt.
Bücher, die ich schon mal ausgeliehen hatte…
15. März 2008 um 15:38 1 KommentarHaftgrund berichtet, dass es in Wiener Büchereien „aus Datenschutzgründen“ nicht mehr möglich ist, im Bibliothekssystem auf Wunsch die Titel zu speichern, die man in der Vergangenheit schon mal ausgeliehen hatte. Schön, dass Bibliotheken anders als die meisten Webanbieter auf Datenschutz achten und nicht bis in alle Ewigkeiten speichern, wer wann was gemacht hat. In diesem Fall ist die Begründung aber wohl eher vorgeschoben, schließlich klingt „Datenschutz“ auch kompetenter als „unsere Software kann das nicht und/oder wir wissen nicht wie man sowas technisch umsetzt“. Die Möglichkeit, alle ausgeliehenden Bücher automatisch in einer Liste abzuspeichern, ist meinem Eindruck nach in Bibliotheken ebenso nützlich wie selten.
Wie Edlef bemerkt, kann man ausgeliehene Bücher ja auch „in citavi, Librarything oder beliebigen anderen Literaturverwaltungssystemen für sich selbst [speichern]“ – was prinzipiell tatsächlich die bessere Variante ist. Nur sollten Bibliotheken Nutzer dabei nicht in „kenn wa nich, wolln wa nicht, ham wa nich, geht nich“-Manier abspeisen, sondern aktiv für die Verknüpfung von Bibliothekssystemen mit Literaturverwaltungssystemen sorgen. Alles was über ein Feld „Ausleihen automatisch bei BibSonomy/LibraryThing/etc. eintragen“ im Benutzerkonto hinausgeht, ist nicht zumutbar und überflüssig.
Ein Lösungsansatz gemäß Serviceorientierter Architektur sähe folgendermaßen aus:
Das Ausleihsystem bekommt eine Webschnitttstelle, über die Nutzer abfragen können, welche Medien sie zur Zeit ausgeliehen haben. Wenn dabei RSS oder ATOM eingesetzt wird (natürlich nur über HTTPS und mit Passwort), sollten gängige Feed-Aggregatoren damit klarkommen. Bisher muss der Zugang zum Ausleihsystem für jede Anwendung wie Bücherwecker einzeln gehackt werden, was mühsam und fehleranfällig ist. Die ausgeliehenen Werke sollten (per URL-Parameter steuerbar) in möglichst vielen Datenformaten beschrieben werden. Prinzipiell reicht aber auch die Standard-Kurztitelanzeige und ein Identifier, mit dem z.B. über unAPI weitere Details in verschiedenen Datenformaten angefordert werden können. Zusätzlich zu diesem Pull-Verfahren sollte die Möglichkeit gegeben werden, á la Pingback andere Dienste zu benachrichtigen sobald ein Benutzer ein Medium ausgeliehen hat.
Den Rest (das automatische Eintragen in eine Literaturverwaltung) kann – und sollte – bei gegebenen APIs eine eigene Anwendung übernehmen. Es würde mich nicht wundern, wenn die fixen Entwickler von LibraryThing das selber basteln oder sich ein Student im Rahmen einer Diplom- oder Bachelorarbeit daran setzt. Sobald saubere, einfache Schnittstellen verfügbar sind, ist der Aufwand für neue „Mashups“ und Zusatzdienste minimal.
Von Göttinger Tier-Feeds und Hannoveraner Bibliotheks-Mashups
6. Dezember 2007 um 17:32 1 KommentarWährend der soeben beendeten, zweiten VZG-Fortbildung zu RSS, Feeds und Content Syndication (die Folien sind schon mal bei Slideshare) wollte ich bei Feedblendr zur Demonstration einen aggregierten Feed zur Stadt Göttingen zusammenstellen. Als erster Treffer bei Google Blogsearch kam dazu zufälligerweise eine Mitteilung über die in Hamm, Oldenburg und Göttingen verfügbare Onleihe (von der Göttinger Stadtbücherei hatte ich dazu schon gestern eine Mail bekommen). Zu den weiteren Entdeckungen gehört, das Göttinger „Tierheim 2.0„, wo Hunde, Katzen und Kleintiere per RSS-Feed abonniert werden können: „Feed the animals„!
Bei einer Google-Suche nach der (leider etwas schwer auffindbaren) Seite der Bibliothek im Kurt-Schwitters-Forum Hannover bin ich dann auf das Weblog Bibliotheken in Hannover gestoßen, in dem Christian Hauschke und Manfred Nowak vom Workshop „Social Software in hannoverschen Bibliotheken“ berichten. Christians Ausführungen zu Lageplänen mit Google Maps (einen Lageplan in Google Maps einzuzeichnen, dauert auch ohne Vorkenntnisse höchstens zwanzig Minuten) möchte ich um eine Mashup-Idee ergänzen, die ich bereits neulich in meiner Lehrveranstaltung vorgestellt habe: Mit dem Perl-Modul PICA::Record lässt sich der Gesamtkatalog Hannover über SRU nach Bestandsdaten durchsuchen – dazu ist lediglich in diesem Beispielskript die Datenbank 2.92 statt 2.1 auszuwählen. Die so ermittelten Bibliotheken können dann mit etwas Bastelei in Google Maps angezeigt werden. Statt oder neben einer Liste der Bestandsnachweise wird dann zu einem Titel geografisch angezeigt, in welcher Bibliothek das Buch vorhanden ist. Mit Zugriff auf die Exemplardaten in den einzelnen OPACs könnte sogar noch angezeigt werden, ob ausleihbare Exemplare gerade vorhanden sind – wie das im Ansatz geht, steht in diesen Folien.
Verweise auf passende Rezensionen
5. Dezember 2007 um 16:35 4 KommentareNachdem ich in einer Fortbildung (siehe slides) am Rande die Realisierung von Links auf Wikipedia mittels des SeeAlso-Protokolls vorgestellt habe, kam von einer Teilnehmerin die Idee, auf die selbe Weise auf Rezensionen zu verweisen. Neben Amazon (wo Rezensionen manipuliert werden) und LibraryThing gibt es eine Vielzahl von Rezensionsdiensten von Fachreferenten und Wissenschaftlern. Leider bekommt dies außerhalb enger Fachcommunities kein Schwein mit, da Rezensionen weder systematisch erschlossen werden, noch praktikabel recherchierbar sind – dies gilt anscheinend auch für Rezensionen in Zeitungen, z.B. bei der ZEIT. Die Idee, über einen Linkserver Verweise auf passende Rezensionen zu liefern, finde ich wunderbar, weshalb ich gleich mal ein Konzept erstellt habe. Hier nur das Diagram, ausführlich im GBV-Wiki:
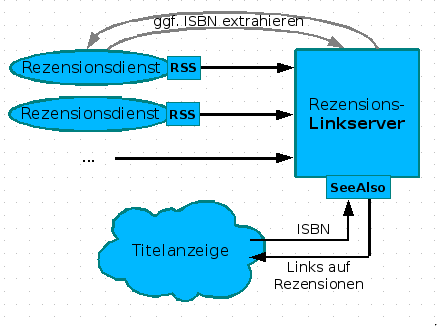
Leider hinken die meisten Rezensionsdienste dem Stand der Technik hinterher und bieten keine (oder kaputte) Feeds an. Wollen die nicht gelesen werden? Nun ja, vielleicht wachen Sie noch auf. Kennt jemand weitere Rezensionsdienste mit benutzbaren Feeds? So lange nicht genügend Rezensionsdienste verfügbar sind, ist der skizzierte Linkserver den Aufwand nicht wert, aber das kann ja noch kommen. Bitte mehr solcher Ideen! Wer nicht weiß, was Feeds sind und sich nicht vorstellen kann, wie ein Linkserver funktioniert, oder den Unterschied zwischen Indexbasierter und Metasuchmaschine nicht einigermaßen verinnerlicht hat, wird auch nicht auf die Ideen kommen, die notwendig sind, damit Bibliotheken nicht in der Bedeutungslosigkeit verschwinden. Deshalb sind Fortbildung und genügend freie Zeit zum Experimentieren so wichtig – zum Beispiel mit diesen Web 2.0-Diensten!
P.S: Neben Rezensionen und Lins auf Wikipedia können auch andere Informationen zu einem Werk von Interesse sein, z.B. Zusammenfassungen, Erwähnungen in Blogs etc.
Archiving Weblogs with ATOM and RFC 5005: An alternative to OAI-PMH
19. Oktober 2007 um 11:34 1 KommentarFollowing up to my recent post (in German) I had a conversation with my colleague about harvesting and archiving blogs and ATOM vs OAI-PMH. In my opinion with the recent RFC 5005 about Feed Paging and Archiving and its proposed extension of Archived Feeds ATOM can be an alternative to OAI-PMH. Instead of arguing which is better, digital libraries should support both for harvesting and providing archived publications such as preprints and weblog entries (scientific communication and publication already takes place in both).
Instead of having every project to implementing both protocols you could create a wrapper from ATOM with archived feeds to OAI-PMH and vice versa. The mapping from OAI-PMH to ATOM is probably the easier part: You partition the repository into chunks as defined in RFC 5005 with the from and until arguments of OAI-PMH. The mapping from OAI-PMH to ATOM is more complicated because you cannot select with timestamps. If you only specify a fromargument, the corresponding ATOM feed could be harvested going backwards in time but if there is an until argument you must harvest the whole archive just to get the first entries and and throw away the rest. Luckily the most frequent use case is to get the newest entries only. Anyway: Both protocols have their pros and cons and a two-way-wrapper could help both. Of course it should be implemented as open source so anyone can use it (by the way: There seems to be no OAI-crawler in Perl yet: Sure there is OAI-Harvester but for real-world applications you have to deal with unavailable servers, corrupt feeds, duplicated or deleted entries, and a way to save the harvested records, so a whole layer above the harvester is missing).
P.S.: At code4lib Ed Summers pointed me to Stuart Weibel who asked the same question about blog archiving, and to a discussion in John Udell’s blog that include blog archiving (he also mentions BlogML as a possible part of a solution – unluckily BlogML looks very dirty to me, the spec is here). And Daniel Chudnov drafted a blog mirroring architecture.
Weblogs Sammeln, Erschließen, Verfügbar machen und Archivieren
19. Oktober 2007 um 03:03 2 KommentareIch ärgere mich ja schon seit längerer Zeit, dass praktisch keine Bibliotheken Weblogs sammeln und archivieren, obwohl diese Mediengattung bereits jetzt teilweise die Funktion von Fachzeitschriften übernimmt. Inzwischen kann ich unter den Kollegen zwar ein steigendes Interesse an Blogs feststellen (der nächste Workshop war nach kurzer Zeit ausgebucht), aber so richtig ist bei der Mehrheit noch nicht angekommen, dass hier eine mit der Einführung des Buchdrucks oder Erfindung von Zeitschriften vergleichbare Evolution im Gange ist. Ansonsten sollten doch viel mehr Bibliotheken damit beginnen Weblogs zu Sammeln, Erschließen, Verfügbar zu machen und zu Archivieren.
Anstatt erstmal darüber zu diskutieren, in welche MAB-Spezialfelder die Daten kommen und als was für eine Mediengatung Weblogs gelten, müsste nur mal einer der existierenden Open Source-Feedreader aufgebohrt werden, so dass er im großen Maßstab auf einem oder mehreren Servern läuft und wenigstens jene Feeds sammelt, die irgend ein Bibliothekar mal als sammlungswürdig eigestuft hat. Alles was wohlgeformtes XML und mit einem Mindestsatz an obligatorischen Elementen (Autor [Zeichenkette], Titel [Zeichenkette], Datum [ISO 8061], Inhalt [Zeichenkette]) ausgestattet ist, dürfte doch wenigstens so archivierbar sein, dass sich der wesentliche Teil rekonstruieren lässt – Besonderheiten wie HTML-Inhalte, Kategorien und Kommentare können ja später noch dazu kommen, wenn die Infrastruktur (Harvester zum Sammeln, Speicher zum Archivieren, Index zum Erschließen und eine Lesemöglichkeit zum Verfügbar machen) steht.
Für die Millionen von Blogartikeln, die bislang verloren sind (abgesehen von den nicht für die Archivierung zur Verfügung stehenden Blogsuchmaschinen wie Bloglines, Technorati, Google Blogsearch, Blogdigger etc.) gibt es zumindest teilweise Hoffnung:
Im September wurde RFC 5005: Feed Paging and Archiving definiert eine (auch in RSS mögliche) Erweiterung des ATOM-Formats, bei der vom Feed der letzten Einträge auf die vorhergehenden Einträge und/oder ein Archiv verwiesen wird. Im Prinzip ist das schon länger möglich und hier an einem Beispiel beschrieben, aber jetzt wurde es nochmal etwas genauer spezifiziert. Damit ist ATOM eine echte Alternative zum OAI-PMH, das zwar der Bibliothekswelt etwas näher steht, aber leider auch noch etwas stiefmütterlich behandelt wird.
Wie auch immer: Bislang werden Blogs nicht systematisch und dauerhaft für die Nachwelt gesammelt und falls Bibliotheken überhaupt eine Zukunft haben, sind sie die einzigen Einrichtungen die dafür wirklich in Frage kommen. Dazu sollte in den nächsten Jahren aber die „Erwerbung“ eines Blogs für den Bibliotheksbestand ebenso vertraut werden wie die Anschaffung eines Buches oder einer Zeitschrift. Meinetwegen können dazu auch DFG-Anträge zur „Sammlung und Archivierung des in Form von Weblogs vorliegenden kulturellen Erbes“ gestellt werden, obgleich ich diesem Projektwesen eher skeptisch gegenüber bin: Die Beständige Weiterentwicklung von Anwendungen als Open Source bringt mehr und es wird auch weniger häufig das Rad neu erfunden.
P.S.: Auf der Informationsseite der DNB zur Sammlung von Netzpublikationen findet sich zu Weblogs noch nichts – es liegt also an jeder einzelnen Bibliothek, sich mal Gedanken über die Sammlung von für Sie relevanten Weblogs zu machen.
Kombinierte Tagsuche als Feed
15. Oktober 2007 um 00:04 Keine KommentareSo möchte ich auch mal Arbeiten: John Udell stellt in seinem eigenen Blog die eine Frage (wie verschiedene Dienste kombiniert nach einem Tag zu durchsuchen und die Treffer zu einem Feed zusammenfassen sind) und die Blogosphäre kommt herbei, um ihm Lösungen anzubieten. [via netbib]
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare