First Draft of SeeAlso Simple linkserver API
14. Januar 2008 um 23:45 2 KommentareI finally finished the first draft of the SeeAlso Simple Specification  . The webservice API for simple linkservers is based on OpenSearch Suggestions. It will be completed by the „SeeAlso Full Specification“ which adds unAPI and OpenSearch Description documents. The service is already implemented and running at the Union Catalog of GBV, see my earlier posting or simply have a look at this example. The same service is installed for testing at the Wikimedia Toolserver. For Wikipedia I drafted a different client that can be tested via a Bookmarklet: Drag the Link „ISBN2W“ to you bookmark toolbar, visit an English or German Wikipedia article with ISBNs on it, click the Bookmarklet link in your toolbar and hover the the ISBNs (that will become yellow) with the mouse. German Wikipedia users can also enable the service by adding a line of JavaScript to their user profile.
. The webservice API for simple linkservers is based on OpenSearch Suggestions. It will be completed by the „SeeAlso Full Specification“ which adds unAPI and OpenSearch Description documents. The service is already implemented and running at the Union Catalog of GBV, see my earlier posting or simply have a look at this example. The same service is installed for testing at the Wikimedia Toolserver. For Wikipedia I drafted a different client that can be tested via a Bookmarklet: Drag the Link „ISBN2W“ to you bookmark toolbar, visit an English or German Wikipedia article with ISBNs on it, click the Bookmarklet link in your toolbar and hover the the ISBNs (that will become yellow) with the mouse. German Wikipedia users can also enable the service by adding a line of JavaScript to their user profile.
An implementation (SeeAlso Simple and SeeAlso Full) in Perl is available at CPAN (there was neither unAPI nor OpenSearch Suggestions, so I implemented both). Please note that ISBN to Wikipedia is only one example how the API can be used. In my opinion the concept of a linkserver is highly undervalued but will become more important again (for instance as a lightweigth alternative to simple SPARQL queries). Feedback and usage is welcome!
Linking to Wikipedia via ISBN
5. Dezember 2007 um 19:52 2 KommentareTwo weeks ago I announced a new beta webservice for linking from title data to German Wikipedia articles that cite a given work by ISBN. Now Lambert pointed me to a message by Eric Hellmann about xISBN supporting links to the English Wikipedia since last week. This makes GBV one week earlier then OCLC and both of us ten month later then LibraryThing. The idea is not new but based on the work of Lars Aronsson, Spiritus rector of future library systems.
The three services have been developed partly parallel based on some same code. Here are two examples of the xISBN service by Xiaoming Liu and the GBV service that I am developing. xISBN is based on a powerfull API with many query parameters and planned to be part of WorldCat Grid Services (more about this maybe here, here, here, and here), while my service is based on a simple API called SeeAlso which is based on OpenSearch Suggestions and unAPI. Both approaches have their pros and cons. I will provide more information as soon as our server is more stable and the scripts are clean enough to get published at CPAN. Meanwhile I encourage everyone to play with OCLC’s xISBN (via an API of its own), WorldCat Idenities (via SRU), LibraryThing for Libraries (via an API of its own), available catalouges (via Z39.50, via SRU and via other APIs), the Wikipedia Query API, and the growing number of other services. Let’s mash up the library systems for the future!
Verweise auf passende Rezensionen
5. Dezember 2007 um 16:35 4 KommentareNachdem ich in einer Fortbildung (siehe slides) am Rande die Realisierung von Links auf Wikipedia mittels des SeeAlso-Protokolls vorgestellt habe, kam von einer Teilnehmerin die Idee, auf die selbe Weise auf Rezensionen zu verweisen. Neben Amazon (wo Rezensionen manipuliert werden) und LibraryThing gibt es eine Vielzahl von Rezensionsdiensten von Fachreferenten und Wissenschaftlern. Leider bekommt dies außerhalb enger Fachcommunities kein Schwein mit, da Rezensionen weder systematisch erschlossen werden, noch praktikabel recherchierbar sind – dies gilt anscheinend auch für Rezensionen in Zeitungen, z.B. bei der ZEIT. Die Idee, über einen Linkserver Verweise auf passende Rezensionen zu liefern, finde ich wunderbar, weshalb ich gleich mal ein Konzept erstellt habe. Hier nur das Diagram, ausführlich im GBV-Wiki:
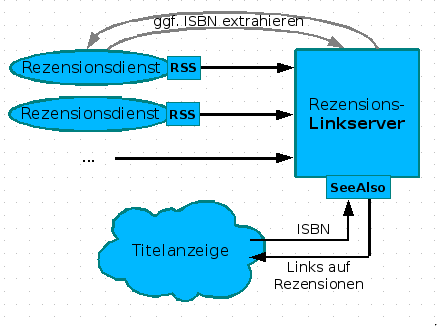
Leider hinken die meisten Rezensionsdienste dem Stand der Technik hinterher und bieten keine (oder kaputte) Feeds an. Wollen die nicht gelesen werden? Nun ja, vielleicht wachen Sie noch auf. Kennt jemand weitere Rezensionsdienste mit benutzbaren Feeds? So lange nicht genügend Rezensionsdienste verfügbar sind, ist der skizzierte Linkserver den Aufwand nicht wert, aber das kann ja noch kommen. Bitte mehr solcher Ideen! Wer nicht weiß, was Feeds sind und sich nicht vorstellen kann, wie ein Linkserver funktioniert, oder den Unterschied zwischen Indexbasierter und Metasuchmaschine nicht einigermaßen verinnerlicht hat, wird auch nicht auf die Ideen kommen, die notwendig sind, damit Bibliotheken nicht in der Bedeutungslosigkeit verschwinden. Deshalb sind Fortbildung und genügend freie Zeit zum Experimentieren so wichtig – zum Beispiel mit diesen Web 2.0-Diensten!
P.S: Neben Rezensionen und Lins auf Wikipedia können auch andere Informationen zu einem Werk von Interesse sein, z.B. Zusammenfassungen, Erwähnungen in Blogs etc.
Relevant APIs for (digital) libraries
30. November 2007 um 14:50 5 KommentareMy current impression of OCLC/WorldCat Service Grid is still far to abstract – instead of creating a framework, we (libraries and library associations) should agree upon some open protocols and (metadata) formats. To start with, here is a list of relevant, existing open standard APIs from my point of view:
Search: SRU/SRW (including CQL), OpenSearch, Z39.50
Harvest/Syndicate: OAI-PMH, RSS, Atom Syndication (also with ATOM Extensions)
Copy/Provide: unAPI, COinS, Microformats (not a real API but a way to provide data)
Upload/Edit: SRU Update, Atom Publishing Protocol
Identity Management: Shibboleth (and other SAML-based protocols), OpenID (see also OSIS)
For more complex applications, additional (REST)-APIs and common metadata standards need to be found (or defined) – but only if the application is just another kind of search, harvest/syndicate, copy/provide, upload/edit, or Identity Management.
P.S: I forgot NCIP, a „standard for the exchange of circulation data“. Frankly I don’t fully understand the meaning and importance of „circulation data“ and the standard looks more complex then needed. More on APIs for libraries can be found in WorldCat Developer Network, in the Jangle project and a DLF Working group on digital library APIs. For staying in the limited world if libraries, this may suffice, but on the web simplicity and availability of implementations matters – that’s why I am working on the SeeAlso linkserver protocol and now at a simple API to query availaibility information (more in August/September 2008).
P.P.S: A more detailed list of concrete library-related APIs was published by Roy Tennant based on a list by Owen Stephens.
P.P.S: And another list by Stephen Abram (SirsiDynix) from September 1st, 2009
Bibsonomy bietet API an
7. Oktober 2007 um 19:51 1 KommentarDer aus Kassel stammende Social Bookmarking und Catalouging-Dienst Bibsonomy bietet seit letzter Woche eine ziemlich umfangreiche, REST-basierte API an. Ein Client für JabRef ist auch schon erhältlich, allerdings anscheinend nur als Jar-File. Außerdem ist eine Java-API in Arbeit – auf der Projektseite zum Java-CLient ist übrigens schön das interne Datenmodell von Bibsonomy dargestellt.
Eine weitere Neuerung in Bibsonomy ist die Volltextsuche über alle (oder zumindest einige?) Metadatenfelder in einem gemeinsamen Index – dadurch ist beispielsweise Ego-Suche und die Suche nach konkreten Publikationen möglich – dabei fällt mir wieder die Menge an Duplikaten auf – also nicht immer nur auf den GBV schimpfen, Duplikate haben auch andere 😉
Ich habe die API bisher noch nicht ausprobiert, dafür ist (leider nicht unüblich) ein eigener Zugriffsschlüssel zu beantragen. Wenn ich mir so die API-Dokumentation anschaue, fehlt anscheinend bisher die Metadaten-Volltextsuche – ich hoffe, das kommt noch, denn auf diese Weise könnte automatisch nach einer gegebenen DOI, ISBN etc. gesucht und in Katalogen dynamisch eingeblendet werden, ob eine bestimmte Publikation schon in BibSonomy verzeichnet ist. Das Eintragen neuer Bookmarks und Referenzen aus Bibliothekskatalogen funktioniert ja schon – Voraussetzung dafür ist, dass der OPAC BibTeX exportieren kann.
Und der Fairness halber auch die Hinweise auf APIs einiger anderer Social Bookmarking und Cataloging-Dienste:Connotea API, CiteULike hat noch keine API, LibraryThing in Ansätzen (und es gibt Datenbankauszüge zum Download!), Del.icio.us API, Mister Wong hat keine API, Digg hat eine…
Und dann bin ich bei der Recherche noch auf den tollen Backlink-Service Xinureturns.com gestoßen, die Nutzen wahrscheinlich statt APIs eher eigene Scraper, die Informationen aus HTML-Seiten extrahieren – das geht natürlich auch immer, ist aber meist aufwändiger und fehleranfälliger.
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare