Little more about The European Library (TEL)
24. August 2007 um 00:17 1 KommentarPatrick, who is enjoying the Winter in South Africa, went down well with his presentation (but I cannot find the slides?). In his blog he pointed out before IFLA that you can find more about The European Library (TEL) in Fleur Stigter’s blog. There is also a blog about the European Digital Library (EDL, very confusing) and a customized search engine for the projects. But I still have not found out what TEL and EDL are really about. To me as a library 2.0 developer one of the most interesting features of TEL is its SRU-interface which showed me that data quality needs to be the next hype. By the way TEL is hiring. If I could clone myself, I would apply here. In the context of Theseus there will surely also be some interesting jobs. Skilled library (2.0) developers where are you? Not every organization can do a hunt on you and reward 1.000$ like LibraryThing just did!
Quality studies at Wikimania2007
4. August 2007 um 05:38 Keine KommentareI just participated in a Wikimania 2007 session with two very smart talks about quality studies in Wikipedia. Both were examples of rare (but hopefully growing) number of scientific studies with knowledge of Wikipedia internals and relevance to the practical needs of Wikipedia. Last but not least they both include working implementations instead of ideas only.
First there is Using Natural Language Processing to determine the quality of Wikipedia articles by Brian Mingus, Trevor Pincock and Laura Rassbach. Brian, an undergraduate student at Colorado, presented a rating system that was trained by existing Quality assesments of Wikipedia articles and a large set of features that may possible be related to quality, mainly computed by methods of natural language processing. Machine classification could predict ratings very well. Brian believes (and convinced me) that the best approach to determining article quality is a combination of human ratings and machine classifications. Human ratings serve as training data and algorithms can reverse engineer the human ratings. You should not think that binary, top-down ratings like the upcoming stable versions done by expert are the definite solution – but they may be additional information to predict quality and to train automatic systems that reproduce and summarize quality ratings. I will publish links to Brian’s slides, paper and code as soon as I get them (we collect all slides). A preliminary paper is in the Wikimania Wiki.
In the second talk Luca De Alfaro presented A Content-Driven Reputation System for the Wikipedia. The basic idea of his clever algorithm to predict trustability of Wikipedia texts is that authors of long-lived contributions gain reputation and authors of reverted contributions lose reputation. The detection and rating of remaining, changed, and reverted contributions is similar to WikiBlame but much more elaborated. Based on the analysis of the whole English, Italian, and French Wikipedia paragraphs and words can be coloured: text that is likely to be trusted is white while text that better should be checked is more orange. See the demo and the paper presented at WWW2007 (slides will follow).
I hope that Wikipedians and local Wikimedia chapters will catch up these efforts to get the tools usable in practise, for instance at Wikimedia Toolserver. Wikipedians, developers, Wikimedia organizations, and scientists need to work together tightly to bring smart ideas in Wikipedia quality research to real applications.
LibrayThing makes subject indexing not suck
30. Juli 2007 um 02:19 Keine KommentareI just mentioned it in my previous post – LibraryThing released a new tagging feature called „Tagmash„. Here a quick review for those of you who don’t read German and because I am not the only one who is so excited about Tagmash:
From a library and information science point of view the feature is little more then saved searches for boolean retrieval in a collaborative subject indexing system. But this „little more“ makes the difference: It’s the interface, stupid! You can create elaborated queries with OR, AND, and NOT in library catalouges and information retrieval systems since decades but most users don’t even know about it – it’s just too complicated and last but not least: it’s not fun!
Tim knows how to make OPACs not suck. It’s refreshing to see the the inventions of information retrieval beeing reinvented implemented in a way that is usable for everyone. David Weinberger got the heard of it in a comment to his posting about Tagmash:
So it is really a matter of positioning and perception. The Google url for a search on france and wwii is: http://www.google.com/search?source=ig&hl=en&q=france+wwii
LibraryThing’s url for the tagmash is http://www.librarything.com/tag/france,wwii So, it’s more human readable. More important, the tagmash page tries to assemble resources related the tagmash.
That’s the point: Assembling resources. A retrievel system where you have to type in a query in some special language to only get a list of hits (or a stupid „nothing found“ message) is just out of date. Other ways to present catalouge content in libraries are rare and experimental but they exist – we need more of them!
The query language (I suppose Tim would not call it such) of LibraryThing is going to evolve as well as the retrieval system, for instance to support weighted boolean retrieval, but the most important part will remain the user interface.
P.S: What I miss in LibraryThing tagging is RSS-Feeds for the books in Tagmashes (so you can create alerting services) and support of SKOS for the Semantic Web (which is not Tim’s job and will take some time).
Wikimedia Conferentie Nederland 2007
28. Mai 2007 um 00:40 2 KommentareDie niederlandischen Wikimedianer veranstalten am 27. Oktober zum zweiten Mal eine kleine Konferenz und zwar in „Onbekend“. Ach nee, der Ort ist noch unbekannt 😉 Oder wie es auf der entsprechenden Wiki-Seite heisst:
De Wikimedia Conferentie Nederland 2007 (WCN’07) is de editie 2007 van de jaarlijkse conferentie georganiseerd door Vereniging Wikimedia Nederland. Naast de gebruikelijke onderwerpen binnen Wikimedia zal de conferentie zich dit jaar ook richten op de raakvlakken tussen Wikimedia en Educatie.

Oder wie Lodewijk Gelauff (Program coordinator Wikimedia Conference NL committee) in einem „Call for Participation“ schreibt:
Beitrag Wikimedia Conferentie Nederland 2007 weiterlesen…
The many standards for structured vocabularies for information retrieval
1. Mai 2007 um 19:46 1 Kommentar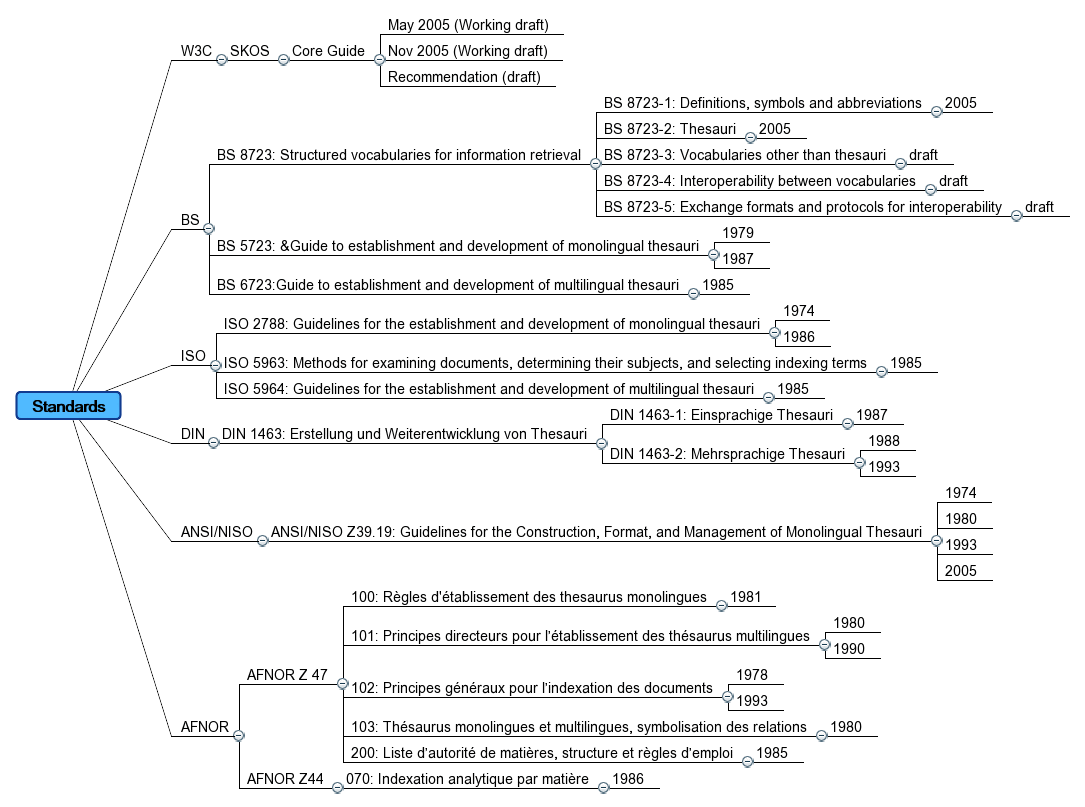
I am currently browsing through the draft of British Standard BS 8723: Structured vocabularies for information retrieval, part 3 (Vocabularies other than thesauri) and 4 (Interoperability between vocabularies). I must confess that reading standards is mostly a pain, especially this old-fashioned pre-web standards in information retrieval. I tried to find out the ancestors of BS 8723 but it took me almost hours. There are dozen of poorly documented related standards and versions (BS 5723, BS 6723, ISO 2788, ISO 5964, DIN 1463, ANSI/NISO Z39.19, AFNOR Z 47 etc.) and most of them are not freely available (and the only available standards are paper-centered PDF instead of web-centered HTML/XML). A standard that is not accesible is pretty worthless! I often complain about the Semantic Web community that ignores most of traditional information retrieval – but they understandably ignore previous results: If traditional information retrieval has not even achieved to visibly and clearly document its own standards on the web – what is it worth for? A general overhaul is necessary: SKOS and collaborative tagging are only two representatives of this change. I fear that BS 8723 will not be part of the new times unless it becomes available Hypertext.
Semantic Web meets Digital Libraries
14. April 2007 um 16:45 2 KommentareI am currently researching on „Semantic Digital Libraries“ for a book chapter on „Semantic Wikipedia“. Here is a list of current events in this quite new research area (at least by name), ordered by date:
- 11th European Conference on Digital Libraries (ECDL, Sep 16-21, Budapest) – submission just closed, may include some related presentations
- Joint Conference on Digital Libraries 2007 (JCDL2007, June 17-23, Vancouver, Canada) – papers should be ready so preprints may be available
- Tutorial on Semantic Digital Libraries at the World Wide Web Conference 2007 (WWW2007, May 8-12, Alberta, Canada)
- Call for Papers (just elapsed) for a special issue on Digital Libraries: From Alexandria to YouTube and Wikipedia – Embedding Social Dynamics of the International Journal of Digital Culture and Electronic Tourism (IJDCET)
- International Conference on Semantic Web and Digital Libraries (ICDS-2007, Feb 21-22, Bangalore, India).
- Workshop on Semantic Technologies in Collaborative Applications (STICA 06, June 26-28, Manchester, UK)
- Joint Conference on Digital Libraries (JCDL 2006, June 11-15, USA), especially the Tutorials on Semantic Digital Libraries and Thesauri and ontologies in digital libraries and some other sessions.
- Workshop Semantic Approaches in Digital Libraries (June 23, 2004, Lund University, Sweden).
Feeds
Siehe auch
Powered by WordPress with Theme based on Pool theme and Silk Icons.
Entries and comments feeds.
Valid XHTML and CSS. ^Top^
Neueste Kommentare